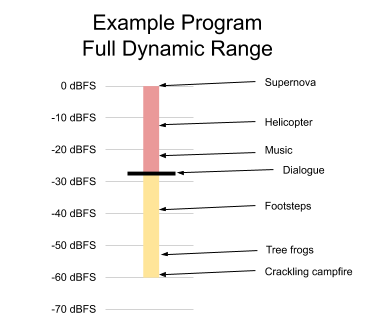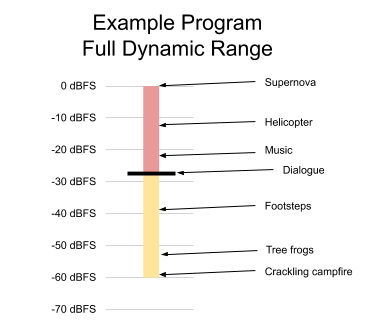This is an old piece of malware—the Chameleon Android banking Trojan—that now disables biometric authentication in order to steal the PIN:
The second notable new feature is the ability to interrupt biometric operations on the device, like fingerprint and face unlock, by using the Accessibility service to force a fallback to PIN or password authentication.
The malware captures any PINs and passwords the victim enters to unlock their device and can later use them to unlock the device at will to perform malicious activities hidden from view.
Having your phone lying around when your kids are playing with everything they find is a great security test. They immediately discover new features and ways to go beyond the usual flow.
This is the way I recently discovered a security issue with Android. Apparently, even if the phone is locked, the pull-down menu with quick settings works. Also, volume control works. Not every functionality inside the quick settings menu works fully while unlocked, but you can disable mobile data and Wi-Fi, you can turn on your hotspot, you can switch to Airplane mode.
While this has been pointed out on Google Pixel forums, on reddit and Stack Exchange, it has not been fixed in stock Android. Different manufacturers seem to have acknowledged the issue in their custom ROMs, but that’s not a reliable long-term solution.
Let me explain why this is an issue. First, it breaks the assumption that when the phone is locked nothing works. Breaking user assumptions is bad by itself.
Second, it allows criminals to steal your phone and put in in Airplane mode, thus disabling any ability to track the phone – either through “find my phone” services, or by the police through mobile carriers. They can silence the phone, so that it’s not found with “ring my phone” functionality. It’s true that an attacker can just take out the SIM card, but having the Wi-Fi on still allows tracking using wifi networks through which the phone passes.
Third, the hotspot (similar issues go with Bluetooth). Allowing a connection can be used to attack the device. It’s not trivial, but it’s not impossible either. It can also be used to do all sorts of network attacks on other devices connected to the hotspot (e.g. you enable the hotspot, a laptop connects automatically, and you execute an APR poisoning attack). The hotspot also allows attackers to use a device to commit online crimes and frame the owner. Especially if they do not steal the phone, but leave it lying where it originally was, just with the hotspot turned on. Of course, they would need to get the password for the hotspot, but this can be obtained through social engineering.
The interesting thing is that when you use Google’s Family Link to lock a device that’s given to a child, the pull-down menu doesn’t work. So the basic idea that “once locked, nothing should be accessible” is there, it’s just not implemented in the default use-case.
While the things described above are indeed edge-cases and may be far fetched, I think they should be fixed. The more functionality is available on a locked phone, the more attack surface it has (including for the exploitation of 0days).
A bunch of Android OEM signing keys have been leaked or stolen, and they are actively being used to sign malware.
Łukasz Siewierski, a member of Google’s Android Security Team, has a post on the Android Partner Vulnerability Initiative (AVPI) issue tracker detailing leaked platform certificate keys that are actively being used to sign malware. The post is just a list of the keys, but running each one through APKMirror or Google’s VirusTotal site will put names to some of the compromised keys: Samsung, LG, and Mediatek are the heavy hitters on the list of leaked keys, along with some smaller OEMs like Revoview and Szroco, which makes Walmart’s Onn tablets.
This is a huge problem. The whole system of authentication rests on the assumption that signing keys are kept secret by the legitimate signers. Once that assumption is broken, all bets are off:
Samsung’s compromised key is used for everything: Samsung Pay, Bixby, Samsung Account, the phone app, and a million other things you can find on the 101 pages of results for that key. It would be possible to craft a malicious update for any one of these apps, and Android would be happy to install it overtop of the real app. Some of the updates are from today, indicating Samsung has still not changed the key.
On November 30, 2022, a Google apvi report from Łukasz Siewierski initially filed on November 11, 2022 was made public. The report contained 10 different platform certificates and malware sample SHA256 sums where the malware sample had been signed by a platform certificate — the application signing certificate used to sign the “Android” application on the system image. Applications signed with platform certificates can therefore run with the same level of privileges as the “Android” application, yielding system privileges on the operating system without user input. Google has recommended that affected parties should rotate their platform certificate. However, platform certificates are considered very sensitive, and the source of these certificates is unknown at this time.
Impact and Remediation
This use of platform certificates to sign malware indicates that a sophisticated adversary has gained privileged access to very sensitive code signing certificates. Any application signed by these certificates could gain complete control over the victim device. Rapid7 does not have any information that would indicate a particular threat actor group as being responsible, but historically, these types of techniques have been preferred by state-sponsored actors. That said, a triage-level analysis of the malicious applications reported shows that the signed applications are adware — a malware type generally considered less sophisticated. This finding suggests that these platform certificates may have been widely available, as state-sponsored actors tend to be more subtle in their approach to highly privileged malware.
We note that although these platform certificates are very sensitive, the over-the-air update certificates are different, and so these cannot be used to push malicious updates.
In cases where the malware can be detected on user devices, it should be remediated immediately. The Google apvi report contains the relevant hashes and we have also listed them at the bottom of this post.
Depending on where you are when you download your Android apps, it might collect more or less data about you.
The apps we downloaded from Google Play also showed differences based on country in their security and privacy capabilities. One hundred twenty-seven apps varied in what the apps were allowed to access on users’ mobile phones, 49 of which had additional permissions deemed “dangerous” by Google. Apps in Bahrain, Tunisia and Canada requested the most additional dangerous permissions.
Three VPN apps enable clear text communication in some countries, which allows unauthorized access to users’ communications. One hundred and eighteen apps varied in the number of ad trackers included in an app in some countries, with the categories Games, Entertainment and Social, with Iran and Ukraine having the most increases in the number of ad trackers compared to the baseline number common to all countries.
One hundred and three apps have differences based on country in their privacy policies. Users in countries not covered by data protection regulations, such as GDPR in the EU and the California Consumer Privacy Act in the U.S., are at higher privacy risk. For instance, 71 apps available from Google Play have clauses to comply with GDPR only in the EU and CCPA only in the U.S. Twenty-eight apps that use dangerous permissions make no mention of it, despite Google’s policy requiring them to do so.
Abstract: Recent studies on the web ecosystem have been raising alarms on the increasing geodifferences in access to Internet content and services due to Internet censorship and geoblocking. However, geodifferences in the mobile app ecosystem have received limited attention, even though apps are central to how mobile users communicate and consume Internet content. We present the first large-scale measurement study of geodifferences in the mobile app ecosystem. We design a semi-automatic, parallel measurement testbed that we use to collect 5,684 popular apps from Google Play in 26 countries. In all, we collected 117,233 apk files and 112,607 privacy policies for those apps. Our results show high amounts of geoblocking with 3,672 apps geoblocked in at least one of our countries. While our data corroborates anecdotal evidence of takedowns due to government requests, unlike common perception, we find that blocking by developers is significantly higher than takedowns in all our countries, and has the most influence on geoblocking in the mobile app ecosystem. We also find instances of developers releasing different app versions to different countries, some with weaker security settings or privacy disclosures that expose users to higher security and privacy risks. We provide recommendations for app market proprietors to address the issues discovered.
Researchers have found a major encryption flaw in 100 million Samsung Galaxy phones.
From the abstract:
In this work, we expose the cryptographic design and implementation of Android’s Hardware-Backed Keystore in Samsung’s Galaxy S8, S9, S10, S20, and S21 flagship devices. We reversed-engineered and provide a detailed description of the cryptographic design and code structure, and we unveil severe design flaws. We present an IV reuse attack on AES-GCM that allows an attacker to extract hardware-protected key material, and a downgrade attack that makes even the latest Samsung devices vulnerable to the IV reuse attack. We demonstrate working key extraction attacks on the latest devices. We also show the implications of our attacks on two higher-level cryptographic protocols between the TrustZone and a remote server: we demonstrate a working FIDO2 WebAuthn login bypass and a compromise of Google’s Secure Key Import.
Here are the details:
As we discussed in Section 3, the wrapping key used to encrypt the key blobs (HDK) is derived using a salt value computed by the Keymaster TA. In v15 and v20-s9 blobs, the salt is a deterministic function that depends only on the application ID and application data (and constant strings), which the Normal World client fully controls. This means that for a given application, all key blobs will be encrypted using the same key. As the blobs are encrypted in AES-GCM mode-of-operation, the security of the resulting encryption scheme depends on its IV values never being reused.
Gadzooks. That’s a really embarrassing mistake. GSM needs a new nonce for every encryption. Samsung took a secure cipher mode and implemented it insecurely.
Interesting story about a barcode scanner app that has been pushing malware on to Android phones. The app is called Barcode Scanner. It’s been around since 2017 and is owned by the Ukrainian company Lavabird Ldt. But a December 2020 update included some new features:
However, a rash of malicious activity was recently traced back to the app. Users began noticing something weird going on with their phones: their default browsers kept getting hijacked and redirected to random advertisements, seemingly out of nowhere.
Generally, when this sort of thing happens it’s because the app was recently sold. That’s not the case here.
It is frightening that with one update an app can turn malicious while going under the radar of Google Play Protect. It is baffling to me that an app developer with a popular app would turn it into malware. Was this the scheme all along, to have an app lie dormant, waiting to strike after it reaches popularity? I guess we will never know.
ESET says that based on evidence its researchers gathered, a threat actor compromised one of the company’s official API (api.bignox.com) and file-hosting servers (res06.bignox.com).
Using this access, hackers tampered with the download URL of NoxPlayer updates in the API server to deliver malware to NoxPlayer users.
[…]
Despite evidence implying that attackers had access to BigNox servers since at least September 2020, ESET said the threat actor didn’t target all of the company’s users but instead focused on specific machines, suggesting this was a highly-targeted attack looking to infect only a certain class of users.
Until today, and based on its own telemetry, ESET said it spotted malware-laced NoxPlayer updates being delivered to only five victims, located in Taiwan, Hong Kong, and Sri Lanka.
I don’t know if there are actually more supply-chain attacks occurring right now. More likely is that they’ve been happening for a while, and we have recently become more diligent about looking for them.
At Netflix, we are passionate about delivering great audio to our members. We began streaming 5.1 channel surround sound in 2010, Dolby Atmos in 2017, and adaptive bitrate audio in 2019. Continuing in this tradition, we are proud to announce that Netflix now streams Extended HE-AAC with MPEG-D DRC (xHE-AAC) to compatible Android Mobile devices (Android 9 and newer). With its capability to improve intelligibility in noisy environments, adapt to variable cellular connections, and scale to studio-quality, xHE-AAC will be a sonic delight to members who stream on these devices.
xHE-AAC Features
MPEG-D DRC
One way that xHE-AAC brings value to Netflix members is through its mandatory MPEG-D DRC metadata. We use APIs described in the MediaFormat class to control the experience in decoders. In this section we will first describe loudness and dynamic range, and then explain how MPEG-D DRC in xHE-AAC works and how we use it.
Dialogue Levels and Dynamic Range
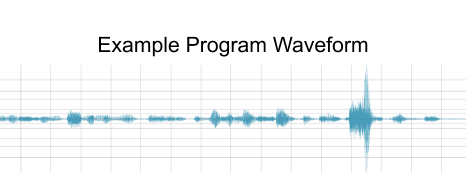
In order to understand the utility of loudness management & dynamic range control, we first must understand the phenomena that we are controlling. As an example, let’s start with the waveform of a program, shown below in Figure 1.
Figure 1. Example program waveform
To measure a program’s dynamic range, we break the waveform into short segments, such as half-second intervals, and compute the RMS level of each segment in dBFS. The summary of those measurements can be plotted on a single vertical line, as shown below in Figure 2. The ambient sound of a campfire may be up to 60 dB softer than the exploding car in an action scene. The dynamic range of a program is the difference between its quietest and the loudest sounds. So in our example, we would say that the program has a dynamic range of 60 dB. We will revisit this example in the section that discusses dynamic range control.
Figure 2. Dynamic range of a program with some examples
Loudness is the subjective perception of sound pressure. Although it is most directly correlated with sound pressure level, it is also affected by the duration and spectral makeup of the sound. Research has shown that, in cinematic and television content, the dialogue level is the most important element to viewers’ perception of a program’s loudness. Since it is the critical component of program loudness, dialogue level is indicated with a bold black line in Figure 2.
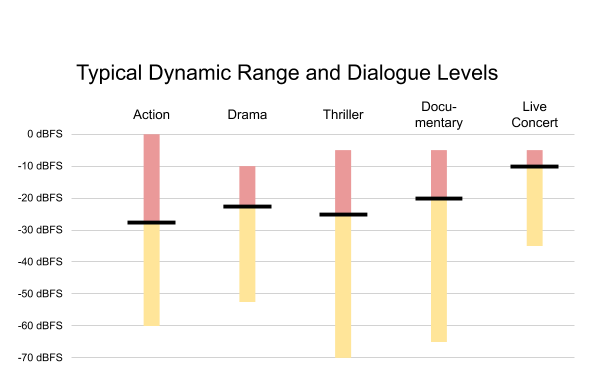
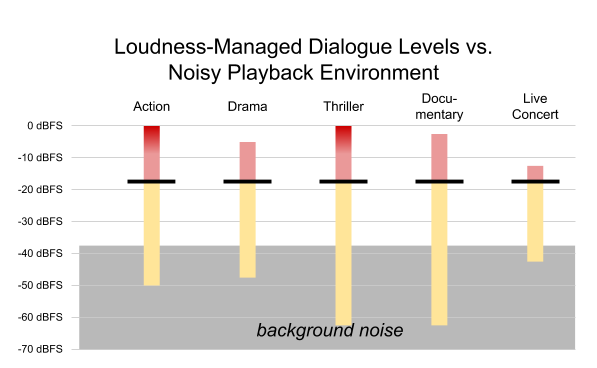
Not every program has the same dialogue level or the same dynamic range. Figure 3 shows a variety of dialogue levels and dynamic ranges for different programs.
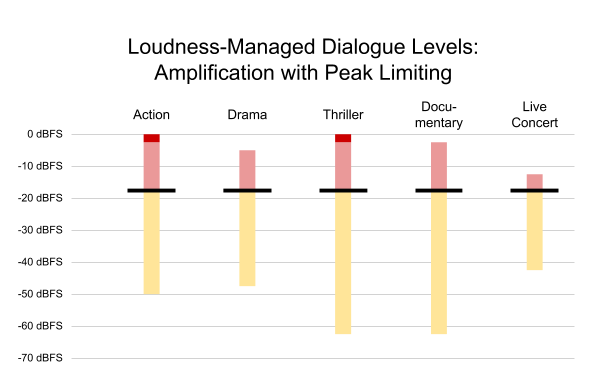
Figure 3. Typical dynamic range and dialogue levels of a variety of content. Black lines indicate average dialogue level; red and yellow are used for louder/softer sounds.
The action film contains dialogue at -27 dBFS, leaving headroom for loud effects like explosions. On the other hand, the live concert has a relatively small dynamic range, with dialogue near the top of the mix. Other shows have varying dialogue levels and varying dynamic ranges. Each show is mixed based on a unique set of conditions.
Now, imagine you were watching these shows, one after the other. If you switched from the action show to the live concert, you would likely be diving for the volume control to turn it down! Then, when the drama comes on, you might not be able to understand the dialogue until you turn the volume back up. If you were to switch partway through shows, the effect might even be more pronounced. This is what loudness management aims to solve.
Loudness Management
The goal of loudness management is to play all titles at a consistent volume, relative to each other. When it is working effectively, once you set your volume to a comfortable level, you never have to change it, even as you switch from a movie to a documentary, to a live concert. Netflix specifically aims to play all dialogue at the same level. This is consistent with the North American television broadcasting standard ATSC A/85 and AES71 recommendations for online video distribution.
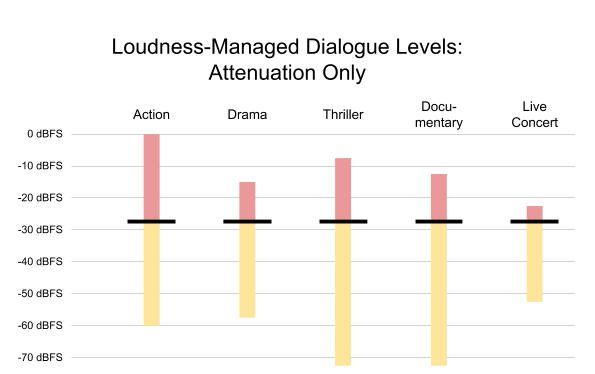
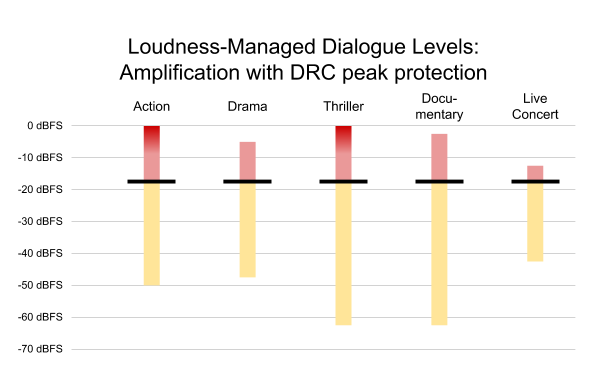
The loudness metrics of all Netflix content are measured before encoding. Since our goal is to play all dialogue at the same level, we use anchor-based (dialogue) measurement, as recommended in A/85. The measured dialog level is delivered in MPEG-D DRC metadata in the xHE-AAC bitstream, using the anchorLoudness metadata set. In the example from Figure 3, the action show would have an anchorLoudness of -27 dBFS; the documentary, -20 dBFS.
On Android, Netflix uses KEY_AAC_DRC_TARGET_REFERENCE_LEVEL to set the output level. The decoder applies a gain equal to the difference between the output level and the anchorLoudness metadata, to normalize all content such that dialogue is always output at the same level. In Figure 4, the output level is set to -27 dBFS. Content with higher anchor loudness is attenuated accordingly.
Figure 4. Content from Figure 3, normalized to achieve consistent dialogue levels
Now, in our imaginary playback scenario, you no longer reach for the volume control when switching from the action program to the live concert — or when switching to any other program.
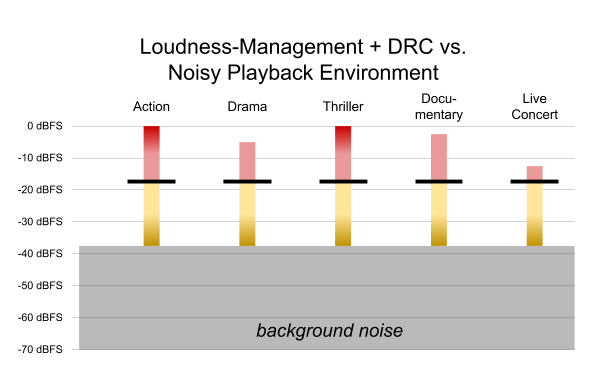
Each device can set a target output level based on its capabilities and the member’s environment. For example, on a mobile device with small speakers, it is often desirable to use a higher output level, such as -16 dBFS, as shown in Figure 5.
Figure 5. Content from Figure 3, normalized to a higher output level, with peak limiting applied as needed (dark red)
Some programs — notably, the action and the thriller — were amplified to achieve the desired output level. In so doing, the loudest content in these programs would be clipped, introducing undesirable harmonic distortion into the sound — so the decoder must apply peak limiting to prevent spurious output. This is not ideal, but it may be a desirable tradeoff to achieve a sufficient output level on some devices. Fortunately, xHE-AAC provides an option to improve peak protection, as described in the Peak Audio Sample Metadata section below.
By using metadata and decode-side gain to normalize loudness, Netflix leverages xHE-AAC to minimize the total number of gain stages in the end-to-end system, maximizing audio quality. Devices retain the ability to customize output level based on unique listening conditions. We also retain the option to defeat loudness normalization completely, for a ‘pure’ mode, when listening conditions are optimal, as in a home theater setting.
Dynamic Range Control
Dynamic range control (DRC) has a wide variety of creative and practical uses in audio production. When playing back content, the goal of dynamic range control is to optimize the dynamic range of a program to provide the best listening experience on any device, in any environment. Netflix leverages the uniDRC() payload metadata, contained in xHE-AAC MPEG-D DRC, to carefully and thoughtfully apply a sophisticated DRC when we know it will be beneficial to our members, based on their device and their environment.
Figure 2 (repeated). Dynamic range of a program with some examples
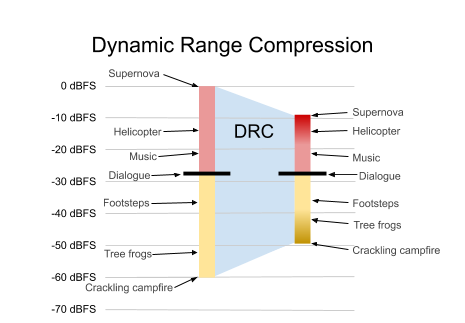
Figure 2 is repeated above. It has a total dynamic range of 60 dB. In a high-end listening environment, like over-ear headphones, home theater, or cinema, members can be fully immersed into both the subtlety of a quiet scene and a bombastic action scene. But many playback scenarios exist where reproduction of such a large dynamic range is undesirable or even impossible (e.g. low-fidelity earbuds, or mobile device speakers, or playback in the presence of loud background noise). If the dynamic range of a member’s device and environment is less than the dynamic range of the content, then they will not hear all of the details in the soundtrack. Or they might frequently adjust the volume during the show, turning up the soft sections, and then turning it back down when things get loud. In extreme cases, they may have difficulty understanding the dialogue, even with the volume turned all the way up. In all of these situations, DRC can be used to reduce the dynamic range of the content to a more suitable range, shown in Figure 6.
Figure 6. The program from Figure 5, after dynamic range compression (gradient). Note that DRC affects loudest and softest parts, but not dialogue.
To reduce dynamic range in a sonically pleasing way requires a sophisticated algorithm, ideally with significant lookahead. Specifically, a good DRC algorithm will not affect dialogue levels, and only apply a gentle adjustment when sounds are too loud or too soft for the listening conditions. As such, it is common to compute DRC parameters at encode-time, when processing power and lookahead is ample. The decoder then simply applies gains that have been specified in metadata. This is exactly how MPEG-D DRC works in xHE-AAC.
Since listening conditions cannot be predicted at encode time, MPEG-D DRC contains multiple DRC profiles that cover a range of situations — for example, Limited Playback Range (for playback over small speakers), Clipping Protection (only for clipping protection as described below), or Noisy Environment (for … noisy environments). On Android decoders, DRC profiles are selected using KEY_AAC_DRC_EFFECT_TYPE.
In MPEG-D DRC, samplePeakLevel signals the maximum level of a program. Another way to think of it is the maximum headroom of the program. For example, in Figure 3, the thriller’s samplePeakLevel is -6 dBFS.
When the combination of a program’s anchorLoudness and a decoder’s target output level results in amplification, as in the action and thriller programs in Figure 3, samplePeakLevel allows DRC gains to be used for peak limiting instead of the decoder’s built-in peak limiter. Again, since DRC is calculated in the encoder using a sophisticated algorithm, this results in higher fidelity audio than running a peak limiter, with limited lookahead, in the decoder. As shown in Figure 7, samplePeakLevel allows the decoder to replace its peak limiter with DRC for the loudest peaks.
Figure 7. Content from Figure 3, normalized to a higher output level, using DRC to prevent clipping as needed.
Putting it Together
Working together, loudness management and DRC can provide an optimal listening experience even in a compromised environment. Figure 8 illustrates a case in which the member is in a noisy environment. The background noise is so loud that softer details — everything below -40 dBFS — are completely inaudible, even when using an elevated target output level of -16 dBFS.
Figure 8. Content from Figure 7, in the presence of background noise
This example is not the worst-case. As previously mentioned, in some scenarios, members using small mobile device speakers are unable to hear even the dialogue due to the background noise!
This is where DRC metadata shows its full value. By engaging DRC, the softest details of programs are boosted enough to be heard even in the presence of the background noise, as illustrated in Figure 9. Since loudness management has already been used to normalize dialogue to -16 dBFS, DRC has no effect on the dialogue. This provides the best possible experience for suboptimal listening situations.
Figure 9. Content from Figure 8, with DRC applied to boost previously-inaudible details.
Seamless Switching and Adaptive Bit Rate
For years, adaptive video bitrate switching has been a core functionality for Netflix media playback. Audio bitrates were fixed, partly due to codec limitations. In 2019, we began delivering high-quality, adaptive bitrate audio to TVs. Now, thanks to xHE-AAC’s native support for seamless bitrate switching, we can bring adaptive bitrate audio to Android mobile devices. Using an approach similar to that described in our High Quality Audio Article, our xHE-AAC streams deliver studio-quality audio when network conditions allow, and minimize rebuffers when the network is congested.
Deployment, Testing and Observations
At Netflix we always perform a comprehensive AB test before any major product change, and a new streaming audio codec is no exception. Content was encoded using the xHE-AAC encoder provided by Fraunhofer IIS, packaged using MP4Box, and A/B tested against our existing streaming audio codec, HE-AAC, on Android mobile devices running Android 9 and newer. Default values were used for KEY_AAC_DRC_TARGET_REFERENCE_LEVEL and KEY_AAC_DRC_EFFECT_TYPE in the xHE-AAC decoder.
Members engage with audio using the device’s built-in speakers, wired headphones/earbuds, or Bluetooth connected devices. We refer to these as the audio sinks. At a high level, xHE-AAC with default loudness and DRC settings showed improved consumer engagement on Android mobile.
In particular, our test focused on audio-related metrics and member usage patterns. Let’s look at three of them: Time-weighted device volume level, volume change interactions, and audio sink changes.
Volume Level
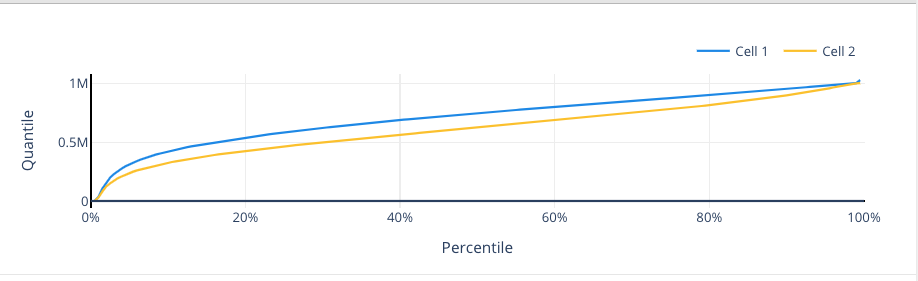
Figure 10. Time-weighted volume level distribution for built-in speakers. (Cell 2: xHE-AAC)
Figure 10 illustrates the volume level for the built-in speaker audio sink. The y-axis shows the volume level reported by Android — which is mapped from 0 (mute) to 1,000,000 (max level). The x-axis shows the percentile that had volume set at or below a particular level. One way to read the graph would be to say that for Cell 2, about 30% of members had the volume set below 0.5M; for Cell 1, it was about 15%. Overall, time-weighted volume levels of xHE-AAC are lower; this is expected as the content itself is 11dB louder. We also note that fewer members have the volume at the maximum level. We believe that if a member has volume at maximum level, they may still not be satisfied with the output level. So we see this as a sign that fewer members are dissatisfied with the overall volume level.
Volume Changes
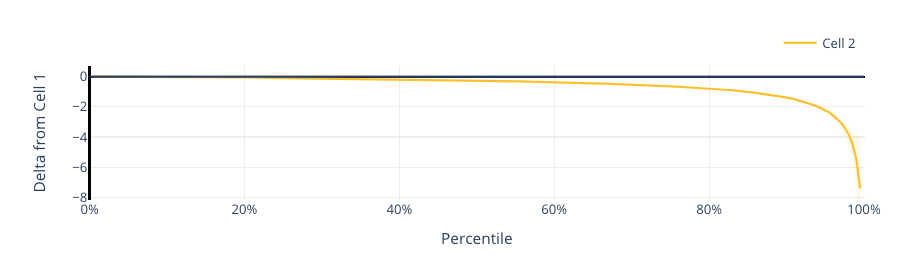
Figure 11. Difference in total volume change interactions (Cell 2: xHE-AAC)
When a show has a high dynamic range, a member may ‘ride the volume’ to turn down the loud segments and turn up the soft segments. Figure 11 shows that volume change interactions are noticeably down for xHE-AAC. This indicates that DRC is doing a good job of managing the volume changes within shows. These differences are far more pronounced for titles with a high dynamic range.
Audio Sink Changes
On mobile devices, most Netflix members use built-in speakers. When members switch to headphones, it can be a sign that the built-in output level is not satisfactory, and they hope for a better experience. For example, perhaps the dialogue level is not audible. In our test, we found that members switched away from built-in speakers 7% less often when listening to xHE-AAC. When the content was high dynamic range, they switched 16% less.
Conclusion
The lessons we have learned while deploying xHE-AAC to Android Mobile devices are not unique — we expect them to apply to other platforms that support the new codec. Netflix always strives to give the best member experience, in every listening environment. So the next time you experience The Crown, get ready to be immersed and not have to reach out to the volume control or grab your earbuds.
Security researcher Ahmed Hassan has shown that spoofing the Android’s “People Nearby” feature allows him to pinpoint the physical location of Telegram users:
Using readily available software and a rooted Android device, he’s able to spoof the location his device reports to Telegram servers. By using just three different locations and measuring the corresponding distance reported by People Nearby, he is able to pinpoint a user’s precise location.
[…]
A proof-of-concept video the researcher sent to Telegram showed how he could discern the address of a People Nearby user when he used a free GPS spoofing app to make his phone report just three different locations. He then drew a circle around each of the three locations with a radius of the distance reported by Telegram. The user’s precise location was where all three intersected.
[…]
Fixing the problem — or at least making it much harder to exploit it — wouldn’t be hard from a technical perspective. Rounding locations to the nearest mile and adding some random bits generally suffices. When the Tinder app had a similar disclosure vulnerability, developers used this kind of technique to fix it.
zANTI is an Android Wireless Hacking Tool that functions as a mobile penetration testing toolkit that lets you assess the risk level of a network using your mobile device for free download.
This easy to use mobile toolkit enables IT Security Administrators to simulate an advanced attacker to identify the malicious techniques they use in the wild to compromise the corporate network.
Features of zANTI Android Wireless Hacking Tool
This network auditor comes along with a rather simple interface compared to other solutions and running its tasks is pretty straightforward.
At Grab, we build a seamless user experience that addresses more and more of the daily lifestyle needs of people across South East Asia. We’re proud of our Grab rides, payments, and delivery services, and want to provide a unified experience across these offerings.
Here is couple of examples of what Grab does for millions of people across South East Asia every day:
Grab Service Offerings
The Grab Passenger application reached super app status more than a year ago and continues to provide hundreds of life-changing use cases in dozens of areas for millions of users.
With the big product scale, it brings with it even bigger technical challenges. Here are a couple of dimensions that can give you a sense of the scale we’re working with.
Engineering and product structure
Technical and product teams work in close collaboration to outserve our customers. These teams are combined into dedicated groups to form Tech Families and focus on similar use cases and areas.
Grab consists of many Tech Families who work on food, payments, transport, and other services, which are supported by hundreds of engineers. The diverse landscape makes the development process complicated and requires the industry’s best practices and approaches.
Codebase scale overview
The Passenger Applications (Android and iOS) contain more than 2.5 million lines of code each and it keeps growing. We have 1000+ modules in the Android App and 700+ targets in the iOS App. Hundreds of commits are merged by all the mobile engineers on a daily basis.
To maintain the health of the codebase and product stability, we run 40K+ unit tests on Android and 30K+ unit tests on iOS, as well as thousands of UI tests and hundreds of end-to-end tests on both platforms.
Build time challenges
The described complexity and scale do not come without challenges. A huge codebase propels the build process to the ultimate extreme- challenging the efficiency of build systems and hardware used to compile the super app, and creating out of the line challenges to be addressed.
Local build time
Local build time (the build on engineers’ laptop) is one of the most obvious challenges. More code goes in the application binary, hence the build system requires more time to compile it.
ADR local build time
The Android ecosystem provides a great out-of-the-box tool to build your project called Gradle. It’s flexible and user friendly, and provides huge capabilities for a reasonable cost. But is this always true? It appears to not be the case due to multiple reasons. Let’s unpack these reasons below.
Gradle performs well for medium sized projects with say 1 million line of code. Once the code surpasses that 1 million mark (or so), Gradle starts failing in giving engineers a reasonable build time for the given flexibility. And that’s exactly what we have observed in our Android application.
At some point in time, the Android local build became ridiculously long. We even encountered cases where engineers’ laptops simply failed to build the project due to hardware resources limits. Clean builds took by the hours, and incremental builds easily hit dozens of minutes.
iOS local build time
Xcode behaved a bit better compared to Gradle. The Xcode build cache was somehow bearable for incremental builds and didn’t exceed a couple of minutes. Clean builds still took dozens of minutes though. When Xcode failed to provide the valid cache, engineers had to rerun everything as a clean build, which killed the experience entirely.
CI pipeline time
Each time an engineer submits a Merge Request (MR), our CI kicks in running a wide variety of jobs to ensure the commit is valid and doesn’t introduce regression to the master branch. The feedback loop time is critical here as well, and the pipeline time tends to skyrocket alongside the code base growth. We found ourselves on the trend where the feedback loop came in by the hours, which again was just breaking the engineering experience, and prevented us from delivering the world’s best features to our customers.
As mentioned, we have a large number of unit tests (30K-40K+) and UI tests (700+) that we run on a pre-merge pipeline. This brings us to hours of execution time before we could actually allow MRs to land to the master branch.
The number of daily commits, which is by the hundreds, adds another stone to the basket of challenges.
All this clearly indicated the area of improvement. We were missing opportunities in terms of engineering productivity.
The extra mile
The biggest question for us to answer was how to put all this scale into a reasonable experience with minimal engineering idle time and fast feedback loop.
Build time critical path optimization
The most reasonable thing to do was to pay attention to the utilization of the hardware resources and make the build process optimal.
This literally boiled down to the simplest approach:
Decouple building blocks
Make building blocks as small as possible
This approach is valid for any build system and applies for both iOS and Android. The first thing we focused on was to understand what our build graph looked like, how dependencies were distributed, and which blocks were bottlenecks.
Given the scale of the apps, it’s practically not possible to manage a dependency tree manually, thus we created a tool to help us.
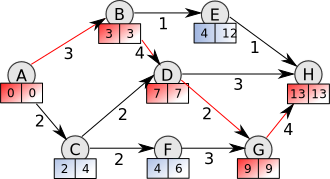
Critical path overview
We introduced the Critical Path concept:
The critical path is the longest (time) chain of sequential dependencies, which must be built one after the other.
Critical Path build
Even with an infinite number of parallel processors/cores, the total build time cannot be less than the critical path time.
We implemented the tool that parsed the dependency trees (for both Android and iOS), aggregated modules/target build time, and calculated the critical path.
The concept of the critical path introduced a number of action items, which we prioritized:
The critical path must be as short as possible.
Any huge module/target on the critical path must be split into smaller modules/targets.
Depend on interfaces/bridges rather than implementations to shorten the critical path.
The presence of other teams’ implementation modules/targets in the critical path of the given team is a red flag.
Stack representation of the Critical Path build time
Project’s scale factor
To implement the conceptually easy action items, we ran a Grab-wide program. The program has impacted almost every mobile team at Grab and involved 200+ engineers to some degree. The whole implementation took 6 months to complete.
During this period of time, we assigned engineers who were responsible to review the changes, provide support to the engineers across Grab, and monitor the results.
Results
Even though the overall plan seemed to be good on paper, the results were minimal – it just flattened the build time curve of the upcoming trend introduced by the growth of the codebase. The estimated impact was almost the same for both platforms and gave us about a 7%-10% cut in the CI and local build time.
Open source plan
The critical path tool proved to be effective to illustrate the projects’ bottlenecks in a dependency tree configuration. It is currently widely used by mobile teams at Grab to analyze their dependencies and cut out or limit an unnecessary impact on the respective scope.
The tool is currently considered to be open-sourced as we’d like to hear feedback from other external teams and see what can be built on top of it. We’ll provide more details on this in future posts.
Remote build
Another pillar of the build process is the hardware where the build runs. The solution is really straightforward – put more muscles on your build to get it stronger and to run faster.
Clearly, our engineers’ laptops could not be considered fast enough. To have a fast enough build we were looking at something with 20+ cores, ~200Gb of RAM. None of the desktop or laptop computers can reach those numbers within reasonable pricing. We hit a bottleneck in hardware. Further parallelization of the build process didn’t give any significant improvement as all the build tasks were just queueing and waiting for the resources to be released. And that’s where cloud computing came into the picture where a huge variety of available options is ready to be used.
ADR mainframer
We took advantage of the Mainframer tool. When the build must run, the code diff is pushed to the remote executor, gets compiled, and then the generated artifacts are pushed back to the local machine. An engineer might still benefit from indexing, debugging, and other features available in the IDE.
To make the infrastructure mature enough, we’ve introduced Kubernetes-based autoscaling based on the load. Currently, we have a stable infrastructure that accommodates 100+ Android engineers scaling up and down (saving costs).
This strategy gave us a 40-50% improvement in the local build time. Android builds finished, in the extreme case, x2 faster.
iOS
Given the success of the Android remote build infrastructure, we have immediately turned our attention to the iOS builds. It was an obvious move for us – we wanted the same infrastructure for iOS builds. The idea looked good on paper and was proven with Android infrastructure, but the reality was a bit different for our iOS builds.
Our very first roadblock was that Xcode is not that flexible and the process of delegating build to remote is way more complicated compared to Android. We tackled a series of blockers such as running indexing on a remote machine, sending and consuming build artifacts, and even running the remote build itself.
The reality was that the remote build was absolutely possible for iOS. There were minor tradeoffs impacting engineering experience alongside obvious gains from utilizing cloud computing resources. But the problem is that legally iOS builds are only allowed to be built on an Apple machine.
Even if we get the most powerful hardware – a macPro – the specs are still not ideal and are unfortunately not optimized for the build process. A 24 core, 194Gb RAM macPro could have given about x2 improvement on the build time, but when it had to run 3 builds simultaneously for different users, the build efficiency immediately dropped to the baseline value.
Android remote machines with the above same specs are capable of running up to 8 simultaneous builds. This allowed us to accommodate up to 30-35 engineers per machine, whereas iOS’ infrastructure would require to keep this balance at 5-6 engineers per machine. This solution didn’t seem to be scalable at all, causing us to abandon the idea of the remote builds for iOS at that moment.
Test impact analysis
The other battlefront was the CI pipeline time. Our efforts in dependency tree optimizations complemented with comparably powerful hardware played a good part in achieving a reasonable build time on CI.
CI validations also include the execution of unit and UI tests and may easily take 50%-60% of the pipeline time. The problem was getting worse as the number of tests was constantly growing. We were to face incredibly huge tests’ execution time in the near future. We could mitigate the problem by a muscle approach – throwing more runners and shredding tests – but it won’t make finance executives happy.
So the time for smart solutions came again. It’s a known fact that the simpler solution is more likely to be correct. The simplest solution was to stop running ALL tests. The idea was to run only those tests that were impacted by the codebase change introduced in the given MR.
Behind this simple idea, we’ve found a huge impact. Once the Test Impact Analysis was applied to the pre-merge pipelines, we’ve managed to cut down the total number of executed tests by up to 90% without any impact on the codebase quality or applications’ stability. As a result, we cut the pipeline for both platforms by more than 30%.
Today, the Test Impact Analysis is coupled with our codebase. We are looking to invest some effort to make it available for open sourcing. We are excited to be on this path.
The end of the Native Build Systems
One might say that our journey was long and we won the battle for the build time.
Today, we hit a limit to the native build systems’ efficiency and hardware for both Android and iOS. And it’s clear to us that in our current setup, we would not be able to scale up while delivering high engineering experience.
Let’s move to Bazel
To introduce another big improvement to the build time, we needed to make some ground-level changes. And this time, we focused on the build system itself.
Native build systems are designed to work well for small and medium-sized projects, however they have not been as successful in large scale projects such as the Grab Passenger applications.
With these assumptions, we considered options and found the Bazel build system to be a good contender. The deep comparison of build systems disclosed that Bazel was promising better results almost in all key areas:
Bazel enables remote builds out of box
Bazel provides sustainable cache capabilities (local and remote). This cache can be reused across all consumers – local builds, CI builds
Bazel was designed with the big codebase as a cornerstone requirement
The majority of the tooling may be reused across multiple platforms
Ways of adopting
On paper, Bazel was awesome and shining. All our playground investigations showed positive results:
Cache worked great
Incremental builds were incredibly fast
But the effort to shift to this new build system was huge. We made sure that we foresee all possible pitfalls and impediments. It took us about 5 months to estimate the impact and put together a sustainable proof of concept, which reflected the majority of our use cases.
Migration limitations
After those 5 months of investigation, we got the endless list of incompatible features and major blockers to be addressed. Those blockers touched even such obvious things as indexing and the jump to definition IDE feature, which we used to take for granted.
But the biggest challenge was the need to keep the pace of the product release. There was no compromise of stopping the product development even for a day. The way out appeared to be a hybrid build concept. We figured out how to marry native and Bazel build systems to live together in harmony. This move gave us a chance to start migrating target by target, project by project moving from the bottom to top of the dependency graph.
This approach was a valid enabler, however we were still faced with a challenge of our app’s scale. The codebase of over 2.5 million of LOC cannot be migrated overnight. The initial estimation was based on the idea of manually migrating the whole codebase, which would have required us to invest dozens of person-months.
Team capacity limitations
This approach was immediately pushed back by multiple teams arguing with the priority and concerns about the impact on their own product roadmap.
We were left with not much choice. On one hand, we had a pressingly long build time. And on the other hand, we were asking for a huge effort from teams. We clearly needed to get buy-ins from all of our stakeholders to push things forward.
Getting buy-in
To get all needed buy-ins, all stakeholders were grouped and addressed separately. We defined key factors for each group.
Key factors
C-level stakeholders:
Impact. The migration impact must be significant – at least a 40% decrease on the build time.
Costs. Migration costs must be paid back in a reasonable time and the positive impact is extended to the future.
Engineering experience. The user experience must not be compromised. All tools and features engineers used must be available during migration and even after.
Engineers:
Engineering experience. Similar to the criteria established at the C-level factor.
Early adopters engagement. A common core experience must be created across the mobile engineering community to support other engineers in the later stages.
Education. Awareness campaigns must be in place. Planned and conducted a series of tech talks and workshops to raise awareness among engineers and cut the learning curve. We wrote hundreds of pages of documentation and guidelines.
Product teams:
No roadmap impact. Migration must not affect the product roadmap.
Minimize the engineering effort. Migration must not increase the efforts from engineering.
Migration automation (separate talks)
The biggest concern for the majority of the stakeholders appeared to be the estimated migration effort, which impacted the cost, the product roadmap, and the engineering experience. It became evident that we needed to streamline the process and reduce the effort for migration.
Fortunately, the actual migration process was routine in nature, so we had opportunities for automation. We investigated ideas on automating the whole migration process.
The tools we’ve created
We found that it’s relatively easy to create a bunch of tools that read the native project structure and create an equivalent Bazel set up. This was a game changer.
Things moved pretty smoothly for both Android and iOS projects. We managed to roll out tooling to migrate the codebase in a single click/command (well with some exceptions as of now. Stay tuned for another blog post on this). With this tooling combined with the hybrid build concept, we addressed all the key buy-in factors:
Migration cost dropped by at least 50%.
Less engineers required for the actual migration. There was no need to engage the wide engineering community as a small group of people can manage the whole process.
There is no more impact on the product roadmap.
Where do we stand today
When we were in the middle of the actual migration, we decided to take a pragmatic path and migrate our applications in phases to ensure everything was under control and that there were no unforeseen issues.
The hybrid build time is racing alongside our migration progress. It has a linear dependency on the amount of the migrated code. The figures look positive and we are confident in achieving our impact goal of decreasing at least 40% of the build time.
Plans to open source
The automated migration tooling we’ve created is planned to be open sourced. We are doing a bit better on the Android side decoupling it from our applications’ implementation details and plan to open source it in the near future.
The iOS tooling is a bit behind, and we expect it to be available for open-sourcing by the end of Q1’2021.
Is it worth it all?
Bazel is not a silver bullet for the build time and your project. There are a lot of edge cases you’ll never know until it punches you straight in your face.
It’s far from industry standard and you might find yourself having difficulty hiring engineers with such knowledge. It has a steep learning curve as well. It’s absolutely an overhead for small to medium-sized projects, but it’s undeniably essential once you start playing in a high league of super apps.
If you were to ask whether we’d go this path again, the answer would come in a fast and correct way – yes, without any doubts.
Authored by Sergii Grechukha on behalf of the Passenger App team at Grab. Special thanks to Madushan Gamage, Mikhail Zinov, Nguyen Van Minh, Mihai Costiug, Arunkumar Sampathkumar, Maryna Shaposhnikova, Pavlo Stavytskyi, Michael Goletto, Nico Liu, and Omar Gawish for their contributions.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
To scale up to the needs of our customers, we’ve adopted ways to efficiently deliver our services through our everyday superapp – whether it’s through continuous process improvements or coding best practices. For one, libraries have made it possible for us to increase our development velocity. In the Passenger App Android team, we’ve a mix of libraries – from libraries that we’ve built in-house to open source ones.
Every week, we release a new version of our Passenger App. Each update contains on average between five to ten library updates. In this article, we will explain how we keep all libraries used by our app up to date, and the different actions we take to avoid defect leaks into production.
How many libraries are we using?
Before we add a new library to a project, it goes through a rigorous assessment process covering many parts, such as security issue detection and usability tests measuring the impact on the app size and app startup time. This process ensures that only libraries up to our standards are added.
In total, there are more than 170 libraries powering the SuperApp, including 55 AndroidX artifacts and 22 libraries used for the sole purpose of writing automation testing (Unit Testing or UI Testing).
Who is responsible for updating
While we do have an internal process on how to update the libraries, it doesn’t mention who and how often it should be done. In fact, it’s everyone’s responsibility to make sure our libraries are up to date. Each team should be aware of the libraries they’re using and whenever a new version is released.
However, this isn’t really the case. We’ve a few developers taking ownership of the libraries as a whole and trying to maintain it. With more than 170 external libraries, we surveyed the Android developer community on how they manage libraries in the company. The result can be summarized as follow:
Survey Results
While most developers are aware of updates, they don’t update a library because the risk of defects leaking into production is too high.
Risk management
The risk is to have a defect leaking into production. It can cause regressions on existing features or introduce new crashes in the app. In a worst case scenario, if this isn’t caught before publishing, it can force us to make a hotfix and a certain number of users will be impacted.
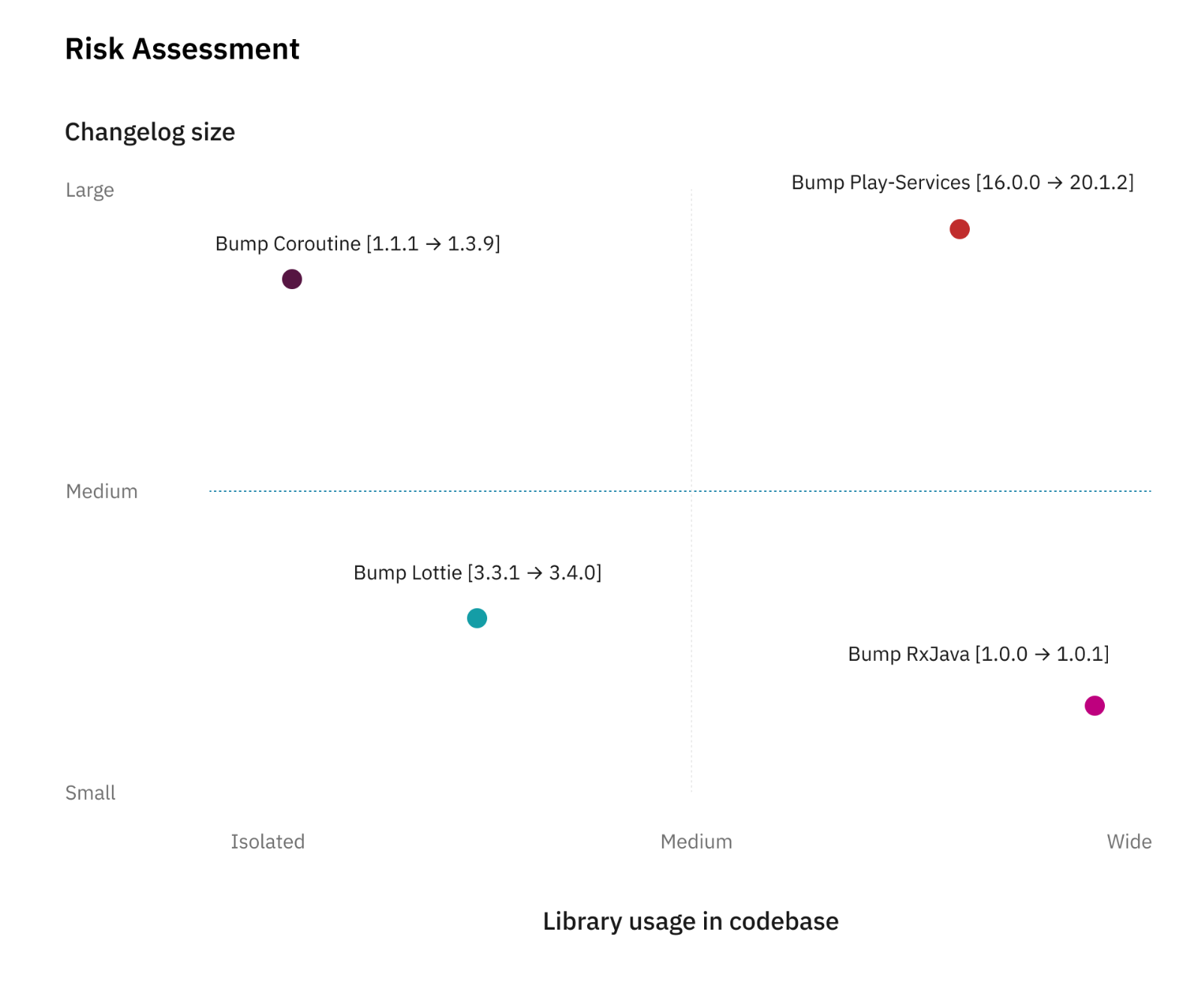
Before updating (bump) a library, we evaluate two metrics:
the usage of this library in the codebase.
the number of changes introduced in the library between the current version and the targeted version.
The risk needs to be assessed between the number of usages of a certain library and the size of the changes. The following chart illustrate this point.
Risk Assessment Radar
This arbitrary scale helps us in deciding if we will require additional signoff from the QA team. If the estimation places the item on the bottom-left corner, the update will be less risky while if it’s on the top-right corner, it means we should follow extra verification to reduce the risk.
A good practice to reduce the risks of updating a library is to update it frequently, decreasing the diffs hence reducing the scope of impact.
Reducing the risk
The first thing we’re doing to reduce the risk is to update our libraries on a weekly basis. As described above, small changes are always less risky than large changes even if the usage of this partial library is wide. By following incremental updates, we avoid accumulating potential issues over a longer period of time.
For example, the Android Jetpack and Firebase libraries follow a two-week release train. So every two weeks, we check for new updates, read the changelogs, and proceed with the update.
In case of a defect detected, we can easily revert the change until we figure out a proper solution or raise the issue to the library owner.
Automation
To reduce risk on any merge request (not limited to library update), we’ve spent a tremendous amount of effort on automating tests. For each new feature we’ve a set of test cases written in Gherkin syntax.
Automation is implemented as UI tests that run on continuous integration (CI) for every merge request. If those tests fail, we won’t be able to merge any changes.
To further elaborate, let’s take this example: Team A developed a lot of features and now has a total of 1,000 test cases. During regression testing before each release, only a subset of those are executed manually based on the impacted area. With automation in place, team A now has 60% of those tests executed as part of CI. So, when all the tests successfully pass, we’re already 60% confident that no defect is detected. This tremendously increases our confidence level while reducing manual testing.
QA signoff
When the update is in the risk threshold area and the automation tests are insufficient, the developer works with QA engineers on analyzing impacted areas. They would then execute test cases related to the impacted area.
For example, if we’re updating Facebook library, the impacted area would be the “Login with Facebook” functionality. QA engineers would then run test cases related to social login.
A single or multiple team can be involved. In some cases, QA signoff can be required by all the teams if they’re all affected by the update.
This process requires a lot of effort from different teams and can affect the current roadmap. To avoid falling into this category, we refine the impacted area analysis to be as specific as possible.
Update before it becomes mandatory
Google updates the Google Play requirements regularly to ensure that published apps are fully compatible with the latest Android version.
For example, starting 1st November 2020 all apps must target API 29. This change causes behavior changes for some API. New behavior has to be supported and verified for our code, but also for all the libraries we use. Libraries bundled inside our app are also affected if they’re using Android API. However, the support for newer API is done by each library maintainer. By keeping our libraries up to date, we ensure compatibility with the latest Android API.
Key takeaways
Keep updating your libraries. If they’re following a release plan, try to match it so it won’t accumulate too many changes. For every new release at Grab, we ship a new version each week, which includes between 5 to 10 libraries bump.
For each update, identify the potential risks on your app and find the correct balance between risk and effort required to mitigate this. Don’t overestimate the risk, especially if the changes are minimal and only include some minor bug fixing. Some library updates don’t even change any single line of code and are only documentation updates.
Invest in robust automation testing to create a high confidence level when making changes, including potentially large changes like a huge library bump.
Authored by Lucas Nelaupe on behalf of the Grab Android Development team. Special thanks to Tridip Thrizu and Karen Kue for the design and copyediting contributions.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
Over the last few years Netflix has been developing a mobile app called Prodicle to innovate in the physical production of TV shows and movies. The world of physical production is fast-paced, and needs vary significantly between the country, region, and even from one production to the next. The nature of the work means we’re developing write-heavy software, in a distributed environment, on devices where less than ⅓ of our users have very reliable connectivity whilst on set, and with a limited margin for error. For these reasons, as a small engineering team, we’ve found that optimizing for reliability and speed of product delivery is required for us to serve our evolving customers’ needs successfully.
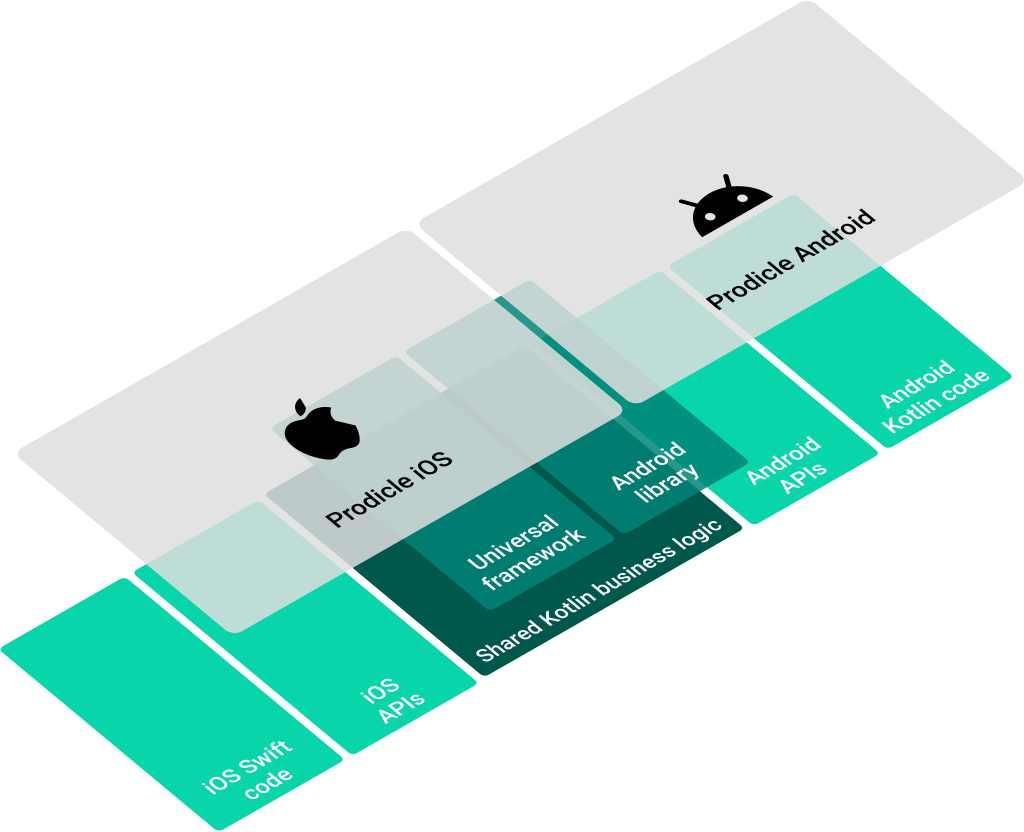
The high likelihood of unreliable network connectivity led us to lean into mobile solutions for robust client side persistence and offline support. The need for fast product delivery led us to experiment with a multiplatform architecture. Now we’re taking this one step further by using Kotlin Multiplatform to write platform agnostic business logic once in Kotlin and compiling to a Kotlin library for Android and a native Universal Framework for iOS via Kotlin/Native.
Kotlin Multiplatform
Kotlin Multiplatform allows you to use a single codebase for the business logic of iOS and Android apps. You only need to write platform-specific code where it’s necessary, for example, to implement a native UI or when working with platform-specific APIs.
Kotlin Multiplatform approaches cross-platform mobile development differently from some well known technologies in the space. Where other technologies abstract away or completely replace platform specific app development, Kotlin Multiplatform is complementary to existing platform specific technologies and is geared towards replacing platform agnostic business logic. It’s a new tool in the toolbox as opposed to replacing the toolbox.
This approach works well for us for several reasons:
Our Android and iOS studio apps have a shared architecture with similar or in some cases identical business logic written on both platforms.
Almost 50% of the production code in our Android and iOS apps is decoupled from the underlying platform.
Our appetite for exploring the latest technologies offered by respective platforms (Android Jetpack Compose, Swift UI, etc) isn’t hampered in any way.
So, what are we doing with it?
Experience Management
As noted earlier, our user needs vary significantly from one production to the next. This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. Decoupling the code that manages these configurations from the apps themselves helps to reduce complexity as the apps grow. Our first exploration with code sharing involves the implementation of a mobile SDK for our internal experience management tool, Hendrix.
At its core, Hendrix is a simple interpreted language that expresses how configuration values should be computed. These expressions are evaluated in the current app session context, and can access data such as A/B test assignments, locality, device attributes, etc. For our use-case, we’re configuring the availability of production, version, and region specific app feature sets.
Poor network connectivity coupled with frequently changing configuration values in response to user activity means that on-device rule evaluation is preferable to server-side evaluation.
This led us to build a lightweight Hendrix mobile SDK — a great candidate for Kotlin Multiplatform as it requires significant business logic and is entirely platform agnostic.
Implementation
For brevity, we’ll skip over the Hendrix specific details and touch on some of the differences involved in using Kotlin Multiplatform in place of Kotlin/Swift.
Build
For Android, it’s business as usual. The Hendrix Multiplatform SDK is imported via gradle as an Android library project dependency in the same fashion as any other dependency. On the iOS side, the native binary is included in the Xcode project as a universal framework.
Developer ergonomics
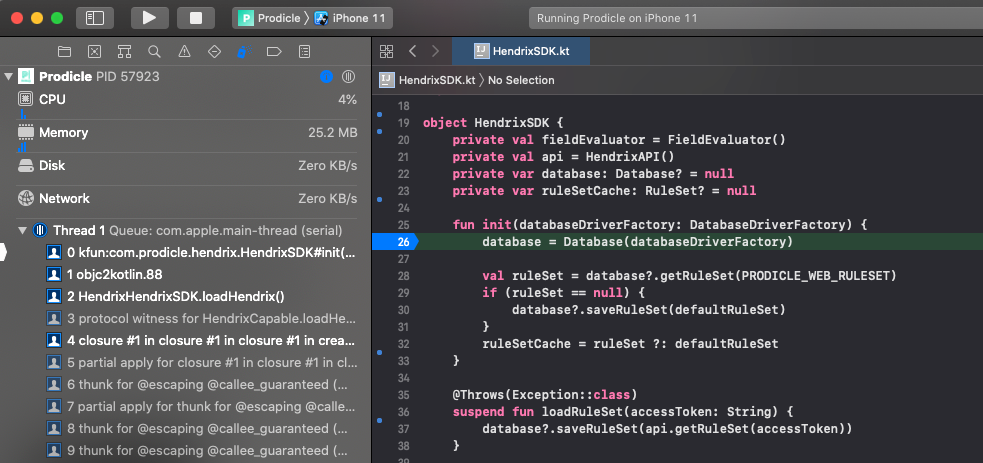
Kotlin Multiplatform source code can be edited, recompiled, and can have a debugger attached with breakpoints in Android Studio and Xcode (including lldb support). Android Studio works out of the box, Xcode support is achieved via TouchLabs’ xcode-kotlin plugin.
Debugging Kotlin source code from Xcode.
Networking
Hendrix interprets rule set(s) — remotely configurable files that get downloaded to the device. We’re using Ktor’s Multiplatform HttpClient to embed our networking code within the SDK.
Disk cache
Of course, network connectivity may not always be available so downloaded rule sets need to be cached to disk. For this, we’re using SQLDelight along with it’s Android and Native Database drivers for Multiplatform persistence.
Final thoughts
We’ve followed the evolution of Kotlin Multiplatform keenly over the last few years and believe that the technology has reached an inflection point. The tooling and build system integrations for Xcode have improved significantly such that the complexities involved in integration and maintenance are outweighed by the benefit of not having to write and maintain multiple platform specific implementations.
Opportunities for additional code sharing between our Android and iOS studio apps are plentiful. Potential future applications of the technology become even more interesting when we consider that Javascript transpilation is also possible.
We’re excited by the possibility of evolving our studio mobile apps into thin UI layers with shared business logic and will continue to share our learnings with you on that journey.
As Android developers, we usually have the luxury of treating our backends as magic boxes running in the cloud, faithfully returning us JSON. At Netflix, we have adopted the Backend for Frontend (BFF) pattern: instead of having one general purpose “backend API”, we have one backend per client (Android/iOS/TV/web). On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code.
Recently, we completed a year-long project rearchitecting and decoupling our backend from the centralized model used previously. We did this migration without slowing down the usual cadence of our releases, and with particular care to avoid any negative effects to the user experience. We went from an essentially serverless model in a monolithic service, to deploying and maintaining a new microservice that hosted our app backend endpoints. This allowed Android engineers to have much more control and observability over how we get our data. Over the course of this post, we will talk about our approach to this migration, the strategies that we employed, and the tools we built to support this.
Background
The Netflix Android app uses the falcor data model and query protocol. This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. As mentioned earlier, each client team owns their respective endpoints: which effectively means that we’re writing the resolvers for each of the paths that are in a query.
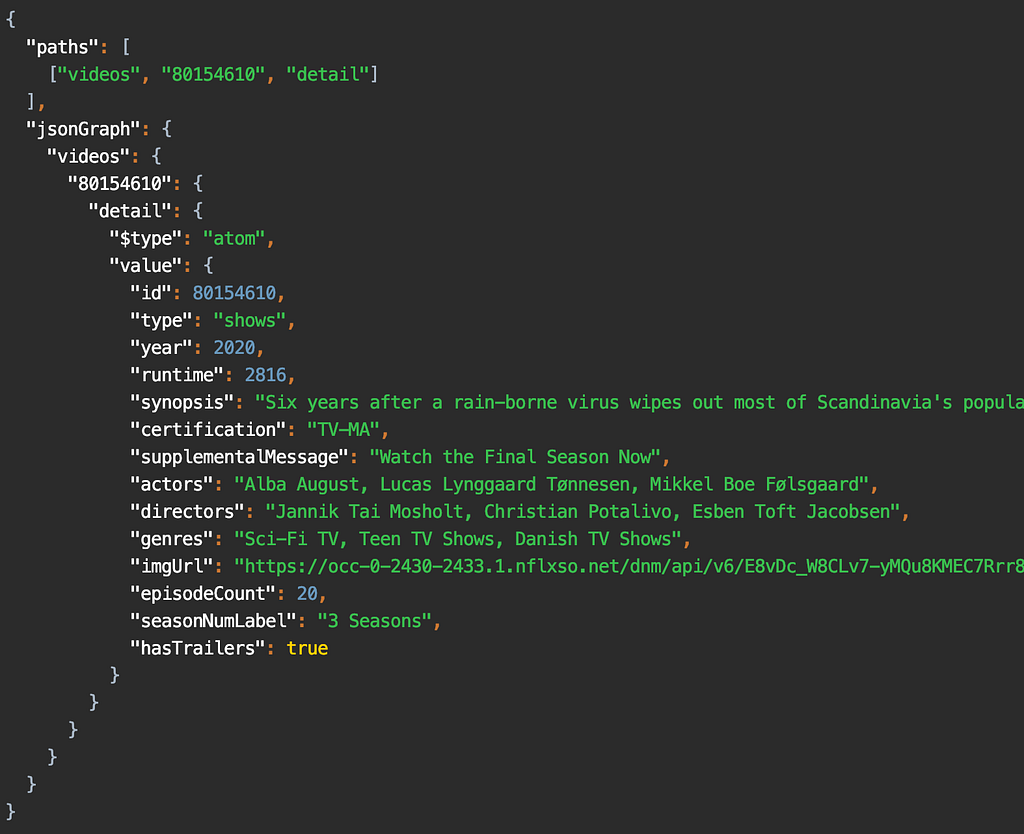
As an example, to render the screen shown here, the app sends a query that looks like this:
paths: ["videos", 80154610, "detail"]
A path starts from a root object, and is followed by a sequence of keys that we want to retrieve the data for. In the snippet above, we’re accessing the detail key for the video object with id 80154610.
For that query, the response is:
Response for the query [“videos”, 80154610, “detail”]
In the Monolith
In the example you see above, the data that the app needs is served by different backend microservices. For example, the artwork service is separate from the video metadata service, but we need the data from both in the detail key.
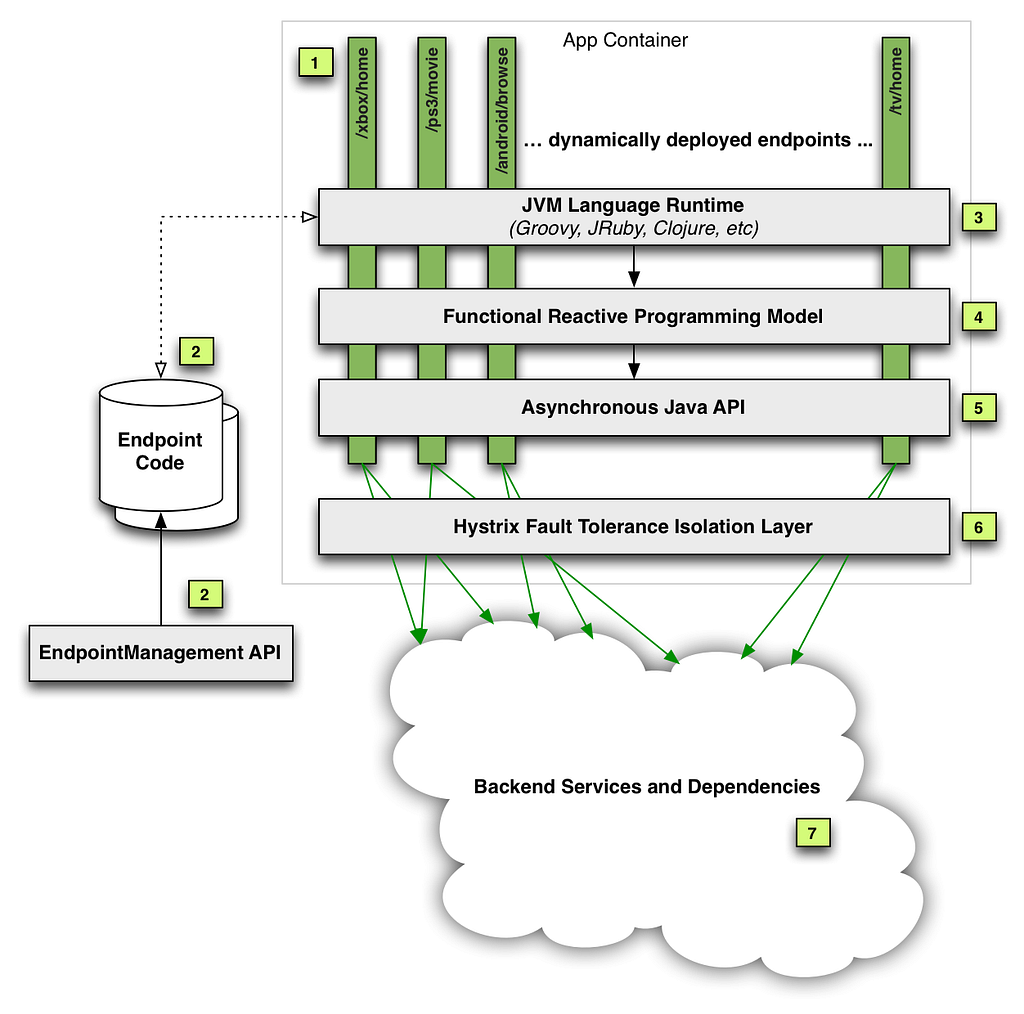
We do this orchestration on our endpoint code using a library provided by our API team, which exposes an RxJava API to handle the downstream calls to the various backend microservices. Our endpoint route handlers are effectively fetching the data using this API, usually across multiple different calls, and massaging it into data models that the UI expects. These handlers we wrote were deployed into a service run by the API team, shown in the diagram below.
As you can see, our code was just a part (#2 in the diagram) of this monolithic service. In addition to hosting our route handlers, this service also handled the business logic necessary to make the downstream calls in a fault tolerant manner. While this gave client teams a very convenient “serverless” model, over time we ran into multiple operational and devex challenges with this service. You can read more about this in our previous posts here: part 1, part 2.
The Microservice
It was clear that we needed to isolate the endpoint code (owned by each client team), from the complex logic of fault tolerant downstream calls. Essentially, we wanted to break out the client-specific code from this monolith into its own service. We tried a few iterations of what this new service should look like, and eventually settled on a modern architecture that aimed to give more control of the API experience to the client teams. It was a Node.js service with a composable JavaScript API that made downstream microservice calls, replacing the old Java API.
Java…Script?
As Android developers, we’ve come to rely on the safety of a strongly typed language like Kotlin, maybe with a side of Java. Since this new microservice uses Node.js, we had to write our endpoints in JavaScript, a language that many people on our team were not familiar with. The context around why the Node.js ecosystem was chosen for this new service deserves an article in and of itself. For us, it means that we now need to have ~15 MDN tabs open when writing routes 🙂
Let’s briefly discuss the architecture of this microservice. It looks like a very typical backend service in the Node.js world: a combination of Restify, a stack of HTTP middleware, and the Falcor-based API. We’ll gloss over the details of this stack: the general idea is that we’re still writing resolvers for paths like [videos, <id>, detail], but we’re now writing them in JavaScript.
The big difference from the monolith, though, is that this is now a standalone service deployed as a separate “application” (service) in our cloud infrastructure. More importantly, we’re no longer just getting and returning requests from the context of an endpoint script running in a service: we’re now getting a chance to handle the HTTP request in its entirety. Starting from “terminating” the request from our public gateway, we then make downstream calls to the api application (using the previously mentioned JS API), and build up various parts of the response. Finally, we return the required JSON response from our service.
The Migration
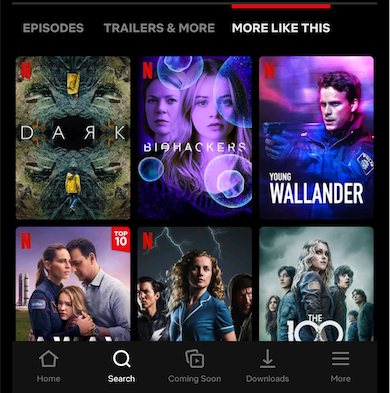
Before we look at what this change meant for us, we want to talk about how we did it. Our app had ~170 query paths (think: route handlers), so we had to figure out an iterative approach to this migration. Let’s take a look at what we built in the app to support this migration. Going back to the screenshot above, if you scroll a bit further down on that page, you will see the section titled “more like this”:
As you can imagine, this does not belong in the video details data for this title. Instead, it is part of a different path: [videos, <id>, similars]. The general idea here is that each UI screen (Activity/Fragment) needs data from multiple query paths to render the UI.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen. Our app uses a version of the repository pattern, where each screen can fetch data using a list of query paths. These paths, along with some other configuration, builds a Task. These Tasks already carry a uiLabel that uniquely identifies each screen: this label became our starting point, which we passed in a header to our endpoint. We then used this to log the time taken to respond to each query, grouped by the uiLabel. This meant that we could track any possible regressions to user experience by screen, which corresponds to how users navigate through the app. We will talk more about how we used these metrics in the sections to follow.
Fast forward a year: the 170 number we started with slowly but surely whittled down to 0, and we had all our “routes” (query paths) migrated to the new microservice. So, how did it go…?
The Good
Today, a big part of this migration is done: most of our app gets its data from this new microservice, and hopefully our users never noticed. As with any migration of this scale, we hit a few bumps along the way: but first, let’s look at good parts.
Migration Testing Infrastructure
Our monolith had been around for many years and hadn’t been created with functional and unit testing in mind, so those were independently bolted on by each UI team. For the migration, testing was a first-class citizen. While there was no technical reason stopping us from adding full automation coverage earlier, it was just much easier to add this while migrating each query path.
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. If we pare down the problem to absolute basics, we essentially have two services returning JSON. We want to make sure that for a given set of paths as input, the returned JSON is always exactly the same. With lots of guidance from other platform and backend teams, we took a 3-pronged approach to ensure correctness for each route migrated.
Functional Testing Functional testing was the most straightforward of them all: a set of tests alongside each path exercised it against the old and new endpoints. We then used the excellent Jest testing framework with a set of custom matchers that sanitized a few things like timestamps and uuids. It gave us really high confidence during development, and helped us cover all the code paths that we had to migrate. The test suite automated a few things like setting up a test user, and matching the query parameters/headers sent by a real device: but that’s as far as it goes. The scope of functional testing was limited to the already setup test scenarios, but we would never be able to replicate the variety of device, language and locale combinations used by millions of our users across the globe.
Replay Testing Enter replay testing. This was a custom built, 3-step pipeline:
Capture the production traffic for the desired path(s)
Replay the traffic against the two services in the TEST environment
Compare and assert for differences
It was a self-contained flow that, by design, captured entire requests, and not just the one path we requested. This test was the closest to production: it replayed real requests sent by the device, thus exercising the part of our service that fetches responses from the old endpoint and stitches them together with data from the new endpoint. The thoroughness and flexibility of this replay pipeline is best described in its own post. For us, the replay test tooling gave the confidence that our new code was nearly bug free.
Canaries Canaries were the last step involved in “vetting” our new route handler implementation. In this step, a pipeline picks our candidate change, deploys the service, makes it publicly discoverable, and redirects a small percentage of production traffic to this new service. You can find a lot more details about how this works in the Spinnaker canaries documentation.
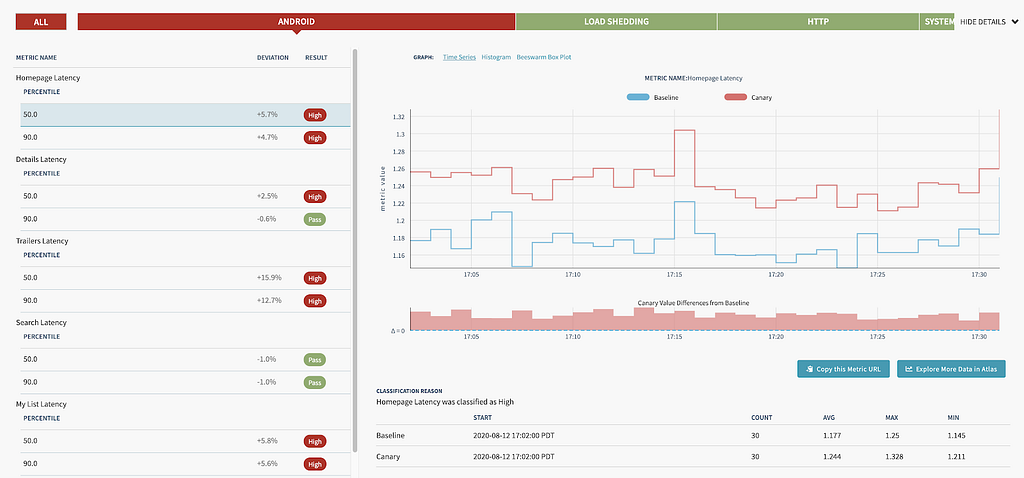
This is where our previously mentioned uiLabel metrics become relevant: for the duration of the canary, Kayenta was configured to capture and compare these metrics for all requests (in addition to the system level metrics already being tracked, like server CPU and memory). At the end of the canary period, we got a report that aggregated and compared the percentiles of each request made by a particular UI screen. Looking at our high traffic UI screens (like the homepage) allowed us to identify any regressions caused by the endpoint before we enabled it for all our users. Here’s one such report to get an idea of what it looks like:
Each identified regression (like this one) was subject to a lot of analysis: chasing down a few of these led to previously unidentified performance gains! Being able to canary a new route let us verify latency and error rates were within acceptable limits. This type of tooling required time and effort to create, but in the end, the feedback it provided was well worth the cost.
Observability
Many Android engineers will be familiar with systrace or one of the excellent profilers in Android Studio. Imagine getting a similar tracing for your endpoint code, traversing along many different microservices: that is effectively what distributed tracing provides. Our microservice and router were already integrated into the Netflix request tracing infrastructure. We used Zipkin to consume the traces, which allowed us to search for a trace by path. Here’s what a typical trace looks like:
A typical zipkin trace (truncated)
Request tracing has been critical to the success of Netflix infrastructure, but when we operated in the monolith, we did not have the ability to get this detailed look into how our app interacted with the various microservices. To demonstrate how this helped us, let us zoom into this part of the picture:
Serialized calls to this service adds a few ms latency
It’s pretty clear here that the calls are being serialized: however, at this point we’re already ~10 hops disconnected from our microservice. It’s hard to conclude this, and uncover such problems, from looking at raw numbers: either on our service or the testservice above, and even harder to attribute them back to the exact UI platform or screen. With the rich end-to-end tracing instrumented in the Netflix microservice ecosystem and made easily accessible via Zipkin, we were able to pretty quickly triage this problem to the responsible team.
End-to-end Ownership
As we mentioned earlier, our new service now had the “ownership” for the lifetime of the request. Where previously we only returned a Java object back to the api middleware, now the final step in the service was to flush the JSON down the request buffer. This increased ownership gave us the opportunity to easily test new optimisations at this layer. For example, with about a day’s worth of work, we had a prototype of the app using the binary msgpack response format instead of plain JSON. In addition to the flexible service architecture, this can also be attributed to the Node.js ecosystem and the rich selection of npm packages available.
Local Development
Before the migration, developing and debugging on the endpoint was painful due to slow deployment and lack of local debugging (this post covers that in more detail). One of the Android team’s biggest motivations for doing this migration project was to improve this experience. The new microservice gave us fast deployment and debug support by running the service in a local Docker instance, which has led to significant productivity improvements.
The Not-so-good
In the arduous process of breaking a monolith, you might get a sharp shard or two flung at you. A lot of what follows is not specific to Android, but we want to briefly mention these issues because they did end up affecting our app.
Latencies
The old api service was running on the same “machine” that also cached a lot of video metadata (by design). This meant that data that was static (e.g. video titles, descriptions) could be aggressively cached and reused across multiple requests. However, with the new microservice, even fetching this cached data needed to incur a network round trip, which added some latency.
This might sound like a classic example of “monoliths vs microservices”, but the reality is somewhat more complex. The monolith was also essentially still talking to a lot of downstream microservices: it just happened to have a custom-designed cache that helped a lot. Some of this increased latency was mitigated by better observability and more efficient batching of requests. But, for a small fraction of requests, after a lot of attempts at optimization, we just had to take the latency hit: sometimes, there are no silver bullets.
Increased Partial Query Errors
As each call to our endpoint might need to make multiple requests to the api service, some of these calls can fail, leaving us with partial data. Handling such partial query errors isn’t a new problem: it is baked into the nature of composite protocols like Falcor or GraphQL. However, as we moved our route handlers into a new microservice, we now introduced a network boundary for fetching any data, as mentioned earlier.
This meant that we now ran into partial states that weren’t possible before because of the custom caching. We were not completely aware of this problem in the beginning of our migration: we only saw it when some of our deserialized data objects had null fields. Since a lot of our code uses Kotlin, these partial data objects led to immediate crashes, which helped us notice the problem early: before it ever hit production.
As a result of increased partial errors, we’ve had to improve overall error handling approach and explore ways to minimize the impact of the network errors. In some cases, we also added custom retry logic on either the endpoint or the client code.
Final Thoughts
This has been a long (you can tell!) and a fulfilling journey for us on the Android team: as we mentioned earlier, on our team we typically work on the app and, until now, we did not have a chance to work with our endpoint with this level of scrutiny. Not only did we learn more about the intriguing world of microservices, but for us working on this project, it provided us the perfect opportunity to add observability to our app-endpoint interaction. At the same time, we ran into some unexpected issues like partial errors and made our app more resilient to them in the process.
As we continue to evolve and improve our app, we hope to share more insights like these with you.
The planning and successful migration to this new service was the combined effort of multiple backend and front end teams.
On the Android team, we ship the Netflix app on Android to millions of members around the world. Our responsibilities include extensive A/B testing on a wide variety of devices by building highly performant and often custom UI experiences. We work on data driven optimizations at scale in a diverse and sometimes unforgiving device and network ecosystem. If you find these challenges interesting, and want to work with us, we have an open position.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.