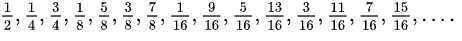Good essay on software bloat and the insecurities it causes.
The world ships too much code, most of it by third parties, sometimes unintended, most of it uninspected. Because of this, there is a huge attack surface full of mediocre code. Efforts are ongoing to improve the quality of code itself, but many exploits are due to logic fails, and less progress has been made scanning for those. Meanwhile, great strides could be made by paring down just how much code we expose to the world. This will increase time to market for products, but legislation is around the corner that should force vendors to take security more seriously.
This is an excerpt from a longer paper. You can read the whole thing (complete with sidebars and illustrations) here.
Our message is simple: it is possible to get the best of both worlds. We can and should get the benefits of the cloud while taking security back into our own hands. Here we outline a strategy for doing that.
What Is Decoupling?
In the last few years, a slew of ideas old and new have converged to reveal a path out of this morass, but they haven’t been widely recognized, combined, or used. These ideas, which we’ll refer to in the aggregate as “decoupling,” allow us to rethink both security and privacy.
Here’s the gist. The less someone knows, the less they can put you and your data at risk. In security this is called Least Privilege. The decoupling principle applies that idea to cloud services by making sure systems know as little as possible while doing their jobs. It states that we gain security and privacy by separating private data that today is unnecessarily concentrated.
To unpack that a bit, consider the three primary modes for working with our data as we use cloud services: data in motion, data at rest, and data in use. We should decouple them all.
Our data is in motion as we exchange traffic with cloud services such as videoconferencing servers, remote file-storage systems, and other content-delivery networks. Our data at rest, while sometimes on individual devices, is usually stored or backed up in the cloud, governed by cloud provider services and policies. And many services use the cloud to do extensive processing on our data, sometimes without our consent or knowledge. Most services involve more than one of these modes.
To ensure that cloud services do not learn more than they should, and that a breach of one does not pose a fundamental threat to our data, we need two types of decoupling. The first is organizational decoupling: dividing private information among organizations such that none knows the totality of what is going on. The second is functional decoupling: splitting information among layers of software. Identifiers used to authenticate users, for example, should be kept separate from identifiers used to connect their devices to the network.
In designing decoupled systems, cloud providers should be considered potential threats, whether due to malice, negligence, or greed. To verify that decoupling has been done right, we can learn from how we think about encryption: you’ve encrypted properly if you’re comfortable sending your message with your adversary’s communications system. Similarly, you’ve decoupled properly if you’re comfortable using cloud services that have been split across a noncolluding group of adversaries.
When Zuul was designed and developed, there was an inherent assumption that connections were effectively free, given we weren’t using mutual TLS (mTLS). It’s built on top of Netty, using event loops for non-blocking execution of requests, one loop per core. To reduce contention among event loops, we created connection pools for each, keeping them completely independent. The result is that the entire request-response cycle happens on the same thread, significantly reducing context switching.
There is also a significant downside. It means that if each event loop has a connection pool that connects to every origin (our name for backend) server, there would be a multiplication of event loops by servers by Zuul instances. For example, a 16-core box connecting to an 800-server origin would have 12,800 connections. If the Zuul cluster has 100 instances, that’s 1,280,000 connections. That’s a significant amount and certainly more than is necessary relative to the traffic on most clusters.
As streaming has grown over the years, these numbers multiplied with bigger Zuul and origin clusters. More acutely, if a traffic spike occurs and Zuul instances scale up, it exponentially increases connections open to origins. Although this has been a known issue for a long time, it has never been a critical pain point until we moved large streaming applications to mTLS and our Envoy-based service mesh.
Fixing the Flows
The first step in improving connection overhead was implementing HTTP/2 (H2) multiplexing to the origins. Multiplexing allows the reuse of existing connections by creating multiple streams per connection, each able to send a request. Rather than requiring a connection for every request, we could reuse the same connection for many simultaneous requests. The more we reuse connections, the less overhead we have in establishing mTLS sessions with roundtrips, handshaking, and so on.
Although Zuul has had H2 proxying for some time, it never supported multiplexing. It effectively treated H2 connections as HTTP/1 (H1). For backward compatibility with existing H1 functionality, we modified the H2 connection bootstrap to create a stream and immediately release the connection back into the pool. Future requests will then be able to reuse the existing connection without creating a new one. Ideally, the connections to each origin server should converge towards 1 per event loop. It seems like a minor change, but it had to be seamlessly integrated into our existing metrics and connection bookkeeping.
The standard way to initiate H2 connections is, over TLS, via an upgrade with ALPN (Application-Layer Protocol Negotiation). ALPN allows us to gracefully downgrade back to H1 if the origin doesn’t support H2, so we can broadly enable it without impacting customers. Service mesh being available on many services made testing and rolling out this feature very easy because it enables ALPN by default. It meant that no work was required by service owners who were already on service mesh and mTLS.
Sadly, our plan hit a snag when we rolled out multiplexing. Although the feature was stable and functionally there was no impact, we didn’t get a reduction in overall connections. Because some origin clusters were so large, and we were connecting to them from all event loops, there wasn’t enough re-use of existing connections to trigger multiplexing. Even though we were now capable of multiplexing, we weren’t utilizing it.
Divide and Conquer
H2 multiplexing will improve connection spikes under load when there is a large demand for all the existing connections, but it didn’t help in steady-state. Partitioning the whole origin into subsets would allow us to reduce total connection counts while leveraging multiplexing to maintain existing throughput and headroom.
We had discussed subsetting many times over the years, but there was concern about disrupting load balancing with the algorithms available. An even distribution of traffic to origins is critical for accurate canary analysis and preventing hot-spotting of traffic on origin instances.
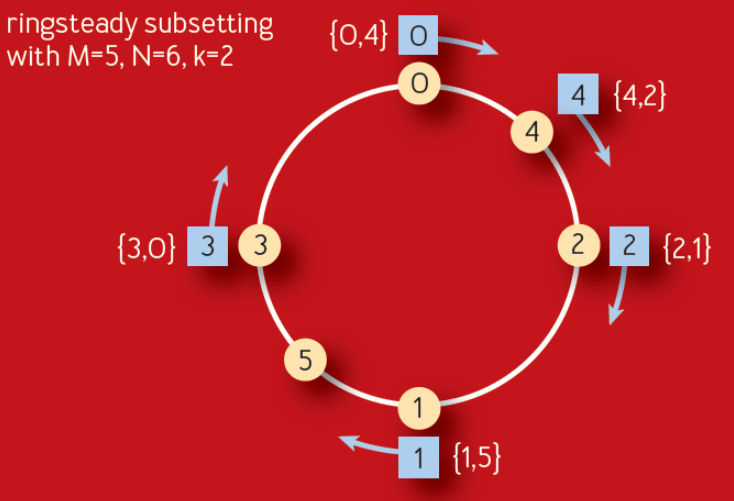
Subsetting was also top of mind after reading a recent ACM paper published by Google. It describes an improvement on their long-standing Deterministic Subsetting algorithm that they’ve used for many years. The Ringsteady algorithm (figure below) creates an evenly distributed ring of servers (yellow nodes) and then walks the ring to allocate them to each front-end task (blue nodes).
The algorithm relies on the idea of low-discrepancy numeric sequences to create a naturally balanced distribution ring that is more consistent than one built on a randomness-based consistent hash. The particular sequence used is a binary variant of the Van der Corput sequence. As long as the sequence of added servers is monotonically incrementing, for each additional server, the distribution will be evenly balanced between 0–1. Below is an example of what the binary Van der Corput sequence looks like.
Another big benefit of this distribution is that it provides a consistent expansion of the ring as servers are removed and added over time, evenly spreading new nodes among the subsets. This results in the stability of subsets and no cascading churn based on origin changes over time. Each node added or removed will only affect one subset, and new nodes will be added to a different subset every time.
Here’s a more concrete demonstration of the sequence above, in decimal form, with each number between 0–1 assigned to 4 subsets. In this example, each subset has 0.25 of that range depicted with its own color.
You can see that each new node added is balanced across subsets extremely well. If 50 nodes are added quickly, they will get distributed just as evenly. Similarly, if a large number of nodes are removed, it will affect all subsets equally.
The real killer feature, though, is that if a node is removed or added, it doesn’t require all the subsets to be shuffled and recomputed. Every single change will generally only create or remove one connection. This will hold for bigger changes, too, reducing almost all churn in the subsets.
Zuul’s Take
Our approach to implement this in Zuul was to integrate with Eureka service discovery changes and feed them into a distribution ring, based on the ideas discussed above. When new origins register in Zuul, we load their instances and create a new ring, and from then on, manage it with incremental deltas. We also take the additional step of shuffling the order of nodes before adding them to the ring. This helps prevent accidental hot spotting or overlap among Zuul instances.
The quirk in any load balancing algorithm from Google is that they do their load balancing centrally. Their centralized service creates subsets and load balances across their entire fleet, with a global view of the world. To use this algorithm, the key insight was to apply it to the event loops rather than the instances themselves. This allows us to continue having decentralized, client-side load balancing while also having the benefits of accurate subsetting. Although Zuul continues connecting to all origin servers, each event loop’s connection pool only gets a small subset of the whole. We end up with a singular, global view of the distribution that we can control on each instance — and a single sequence number that we can increment for each origin’s ring.
When a request comes in, Netty assigns it to an event loop, and it remains there for the duration of the request-response lifecycle. After running the inbound filters, we determine the destination and load the connection pool for this event loop. This will pull from a mapping of loop-to-subset, giving us the limited set of nodes we’re looking for. We then load balance using a modified choice-of-2, as discussed before. If this sounds familiar, it’s because there are no fundamental changes to how Zuul works. The only difference is that we provide a loop-bound subset of nodes to the load balancer as a starting point for its decision.
Another insight we had was that we needed to replicate the number of subsets among the event loops. This allows us to maintain low connection counts for large and small origins. At the same time, having a reasonable subset size ensures we can continue providing good balance and resiliency features for the origin. Most origins require this because they are not big enough to create enough instances in each subset.
However, we also don’t want to change this replication factor too often because it would cause a reshuffling of the entire ring and introduce a lot of churn. After a lot of iteration, we ended up implementing this by starting with an “ideal” subset size. We achieve this by computing the subset size that would achieve the ideal replication factor for a given cardinality of origin nodes. We can scale the replication factor across origins by growing our subsets until the desired subset size is achieved, especially as they scale up or down based on traffic patterns. Finally, we work backward to divide the ring into even slices based on the computed subset size.
Our ideal subset side is roughly 25–50 nodes, so an origin with 400 nodes will have 8 subsets of 50 nodes. On a 32-core instance, we’ll have a replication factor of 4. However, that also means that between 200 and 400 nodes, we’re not shuffling the subsets at all. An example of this subset recomputation is in the rollout graphs below.
An interesting challenge here was to satisfy the dual constraints of origin nodes with a range of cardinality, and the number of event loops that hold the subsets. Our goal is to scale the subsets as we run on instances with higher event loops, with a sub-linear increase in overall connections, and sufficient replication for availability guarantees. Scaling the replication factor elastically described above helped us achieve this successfully.
Subsetting Success
The results were outstanding. We saw improvements across all key metrics on Zuul, but most importantly, there was a significant reduction in total connection counts and churn.
Total Connections
This graph (as well as the ones below) shows a week’s worth of data, with the typical diurnal cycle of Netflix usage. Each of the 3 colors represents our deployment regions in AWS, and the blue vertical line shows when we turned on the feature.
Total connections at peak were significantly reduced in all 3 regions by a factor of 10x. This is a huge improvement, and it makes sense if you dig into how subsetting works. For example, a machine running 16 event loops could have 8 subsets — each subset is on 2 event loops. That means we’re dividing an origin by 8, hence an 8x improvement. As to why peak improvement goes up to 10x, it’s probably related to reduced churn (below).
Churn
This graph is a good proxy for churn. It shows how many TCP connections Zuul is opening per second. You can see the before and after very clearly. Looking at the peak-to-peak improvement, there is roughly an 8x improvement.
The decrease in churn is a testament to the stability of the subsets, even as origins scale up, down, and redeploy over time.
Looking specifically at connections created in the pool, the reduction is even more impressive:
The peak-to-peak reduction is massive and clearly shows how stable this distribution is. Although hard to see on the graph, the reduction went from thousands per second at peak down to about 60. Thereis effectively no churn of connections, even at peak traffic.
Load Balancing
The key constraint to subsetting is ensuring that the load balance on the backends is still consistent and evenly distributed. You’ll notice all the RPS on origin nodes grouped tightly, as expected. The thicker lines represent the subset size and the total origin size.
Balance at deployBalance 12 hours after deploy
In the second graph, you’ll note that we recompute the subset size (blue line) because the origin (purple line) became large enough that we could get away with less replication in the subsets. In this case, we went from a subset size of 100 for 400 servers (a division of 4) to 50 (a division of 8).
System Metrics
Given the significant reduction in connections, we saw reduced CPU utilization (~4%), heap usage (~15%), and latency (~3%) on Zuul, as well.
Zuul canary metrics
Rolling it Out
As we rolled this feature out to our largest origins — streaming playback APIs — we saw the pattern above continue, but with scale, it became more impressive. On some Zuul shards, we saw a reduction of as much as 13 million connections at peak, with almost no churn.
Today the feature is rolled out widely. We’re serving the same amount of traffic but with tens of millions fewer connections. Despite the reduction of connections, there is no decrease in resiliency or load balancing. H2 multiplexing allows us to scale up requests separately from connections, and our subsetting algorithm ensures an even traffic balance.
Although challenging to get right, subsetting is a worthwhile investment.
Acknowledgments
We would also like to thank Peter Ward, Paul Wankadia, and Kavita Guliani at Google for developing this algorithm and publishing their work for the benefit of the industry.
Last August, LastPass reported a security breach, saying that no customer information—or passwords—were compromised. Turns out the full story is worse:
While no customer data was accessed during the August 2022 incident, some source code and technical information were stolen from our development environment and used to target another employee, obtaining credentials and keys which were used to access and decrypt some storage volumes within the cloud-based storage service.
[…]
To date, we have determined that once the cloud storage access key and dual storage container decryption keys were obtained, the threat actor copied information from backup that contained basic customer account information and related metadata including company names, end-user names, billing addresses, email addresses, telephone numbers, and the IP addresses from which customers were accessing the LastPass service.
The threat actor was also able to copy a backup of customer vault data from the encrypted storage container which is stored in a proprietary binary format that contains both unencrypted data, such as website URLs, as well as fully-encrypted sensitive fields such as website usernames and passwords, secure notes, and form-filled data.
That’s bad. It’s not an epic disaster, though.
These encrypted fields remain secured with 256-bit AES encryption and can only be decrypted with a unique encryption key derived from each user’s master password using our Zero Knowledge architecture. As a reminder, the master password is never known to LastPass and is not stored or maintained by LastPass.
So, according to the company, if you chose a strong master password—here’s my advice on how to do it—your passwords are safe. That is, you are secure as long as your password is resilient to a brute-force attack. (That they lost customer data is another story….)
Fair enough, as far as it goes. My guess is that many LastPass users do not have strong master passwords, even though the compromise of your encrypted password file should be part of your threat model. But, even so, note this unverified tweet:
I think the situation at @LastPass may be worse than they are letting on. On Sunday the 18th, four of my wallets were compromised. The losses are not significant. Their seeds were kept, encrypted, in my lastpass vault, behind a 16 character password using all character types.
If that’s true, it means that LastPass has some backdoor—possibly unintentional—into the password databases that the hackers are accessing. (Or that @Cryptopathic’s “16 character password using all character types” is something like “P@ssw0rdP@ssw0rd.”)
My guess is that we’ll learn more during the coming days. But this should serve as a cautionary tale for anyone who is using the cloud: the cloud is another name for “someone else’s computer,” and you need to understand how much or how little you trust that computer.
If you’re changing password managers, look at my own Password Safe. Its main downside is that you can’t synch between devices, but that’s because I don’t use the cloud for anything.
Based on a screenshot from Apple, these categories are covered when you flip on Advanced Data Protection: device backups, messages backups, iCloud Drive, Notes, Photos, Reminders, Safari bookmarks, Siri Shortcuts, Voice Memos, and Wallet Passes. Apple says the only “major” categories not covered by Advanced Data Protection are iCloud Mail, Contacts, and Calendar because “of the need to interoperate with the global email, contacts, and calendar systems,” according to its press release.
You can see the full list of data categories and what is protected under standard data protection, which is the default for your account, and Advanced Data Protection on Apple’s website.
With standard data protection, Apple holds the encryption keys for things that aren’t end-to-end encrypted, which means the company can help you recover that data if needed. Data that’s end-to-end encrypted can only be encrypted on “your trusted devices where you’re signed in with your Apple ID,” according to Apple, meaning that the company—or law enforcement or hackers—cannot access your data from Apple’s databases.
Note that this system doesn’t have the backdoor that was in Apple’s previous proposal, the one put there under the guise of detecting CSAM.
Apple says that it will roll out worldwide by the end of next year. I wonder how China will react to this.
Researchers claim that supposedly anonymous device analytics information can identify users:
On Twitter, security researchers Tommy Mysk and Talal Haj Bakry have found that Apple’s device analytics data includes an iCloud account and can be linked directly to a specific user, including their name, date of birth, email, and associated information stored on iCloud.
Apple has long claimed otherwise:
On Apple’s device analytics and privacy legal page, the company says no information collected from a device for analytics purposes is traceable back to a specific user. “iPhone Analytics may include details about hardware and operating system specifications, performance statistics, and data about how you use your devices and applications. None of the collected information identifies you personally,” the company claims.
Apple was just sued for tracking iOS users without their consent, even when they explicitly opt out of tracking.
There are a variety of ways in which to host a website online. This blog (post) explores how to simply publish and automate a statically built website. Hugo is one such example of a system which can create static websites and is popularly used for blogs.
The final website itself, will consist and contain; HTML, CSS, Images and JavaScript. During this process, (Anchor’s cloud experts) have listed the AWS Services in order to achieve our goal. These include:
Cloudfront
CodeBuild
CodePipeline
IAM
Amazon S3
CodeCommit
This Solution should be well below $5 per month as most of the items are within the Always Free Tier, except the AWS S3 Storage (Which only has valid free-tier for the first 12 month) depending on the traffic.
In order to keep this simple, the below steps are done via the console, although I have also published a similar simplified project using Terraform which can be found on Github.
Setup the AWS Components Setup S3
To begin with, you will need to setup some storage for the website’s content, as well as the pipeline’s artifacts.
Create the bucket for your Pipeline Files. Ensure that Block all public access is checked. It’s recommended you also enable Server-side encryption by default with SSE-S3.
Create a bucket for your Website Files. Ensure that block all public access is NOT checked. This bucket will be open to the world as it will need to be configured to host a website.
When the Website Files bucket is created. Go to Properties tab and Edit Static website hosting. Set it to Enable, and select the type as Host a static website. Save Changes. Note the URL under Bucket website endpoint.Go to Permissions tab and Edit the Bucket policy. Paste in a policy such as the samplebelow. Update ${website-bucket-name} accordingly to match the name of the bucket.
You will need to first create an IAM Role which your CodePipeline and CodeBuild will be able to assume. Some of the below permissions can be drilled down further, as they are fairly generic. In this case we are merging the CodePipeline/CodeBuild into one user.Create a Role in IAM with a unique name based on your project. You will need to setup the below trust policy.
Create a Policy. Paste in a policy such as the below sample. Update ${website-bucket-name} and ${pipeline-bucket-name} accordingly. Attach the policy to the role you created in the step prior.
Access Cloudfront and select Create distribution. Under Origin domain – select the S3 Bucket you created earlier.
Under Viewer protocol policy, set your desired actions. If you have a proper SSL you can set it up later and use Redirect HTTP to HTTPS.
Under Allowed HTTP methods, select GET, HEAD.
You can setup Alternate domain name here, but make sure you have an ACM Certificate to cover it, and setup Customer SSL certificate if you wish to use HTTPS.
Set the Default root object to index.html. This will ensure it loads the website if someone visits the root of the domain.
Leave everything else as default for the moment and click Create distribution.
Note down the Distribution ID, as you will need it for the Pipeline.
Setup the Pipeline
Now that all the components have been created, let’s setup the Pipeline to Tie them all Together. Setup CodeCommit Navigate in to CodeCommit, and select Create Repository You can use git-remote-codecommit in order to checkout the repository locally. You will need to check it out to make additional changes.
You will need to make a sample commit, so create a directory called public and a file called index.html within it with some sample content, and push it up.
$ cat public/index.html This is an S3-hosted website test
After this is done, you should have a branch called “master” or “main” depending on your local configuration. This will need to be referenced during pipeline creation. Setup buildspec in Repository
Add a buildSpec.yml file to the CodeCommit Repo in order to automatically upload your files to AWS S3, and Invalidate the Cloudfront Cache. Note that ${bucketname} and ${cloudfront_id} in the examples below need to be replaced with the real values.
In our example, we’re going to use a very simple and straightforward pipeline. It will have a Source and Deployment phase.
Navigate in to CodePipeline, and select Create Pipeline. Enter your Pipeline name, and select the role you created earlier under Service role.
Under Advanced Settings, set the Artifact Store to Custom Location and update the field to reference the pipeline bucket you created earlier on.
Click next, and move to Adding a Source Provider. Select the Source provider, Repository name and Branch name setup previously, and click next leaving everything else as default.
On the Build section, select Build provider as AWS CodeBuild, and click Create Project under Project name.
This will open a new window. Codebuild will need to be created through this interface, otherwise it doesn’t support the artifacts, and source configuration correctly.
Under Environment, select the latest Ubuntu Runtime for codebuild, and under Service role select the IAM role you created earlier.Once that’s all done, click Continue to CodePipeline and it will close out the window and your project will now be created.
Click Next, and then Skip deploy stage (we’re doing it during the build stage!). Finally, click on create the pipeline and it will start running based on the work you’ve done so far.
The website so far should now be available in the browser! Any further changes to the CodeCommit repository will result in the website being updated on S3 within minutes!
Apple’s announcement that it’s going to start scanning photos for child abuse material is a big deal. (Herearefivenewsstories.) I have been following the details, and discussing it in several different email lists. I don’t have time right now to delve into the details, but wanted to post something.
There are two main features that the company is planning to install in every Apple device. One is a scanning feature that will scan all photos as they get uploaded into iCloud Photos to see if they match a photo in the database of known child sexual abuse material (CSAM) maintained by the National Center for Missing & Exploited Children (NCMEC). The other feature scans all iMessage images sent or received by child accounts — that is, accounts designated as owned by a minor — for sexually explicit material, and if the child is young enough, notifies the parent when these images are sent or received. This feature can be turned on or off by parents.
This is pretty shocking coming from Apple, which is generally really good about privacy. It opens the door for all sorts of other surveillance, since now that the system is built it can be used for all sorts of other messages. And it breaks end-to-end encryption, despite Apple’s denials:
Does this break end-to-end encryption in Messages?
No. This doesn’t change the privacy assurances of Messages, and Apple never gains access to communications as a result of this feature. Any user of Messages, including those with with communication safety enabled, retains control over what is sent and to whom. If the feature is enabled for the child account, the device will evaluate images in Messages and present an intervention if the image is determined to be sexually explicit. For accounts of children age 12 and under, parents can set up parental notifications which will be sent if the child confirms and sends or views an image that has been determined to be sexually explicit. None of the communications, image evaluation, interventions, or notifications are available to Apple.
Notice Apple changing the definition of “end-to-end encryption.” No longer is the message a private communication between sender and receiver. A third party is alerted if the message meets a certain criteria.
EDITED TO ADD (8/13): Really good essay by EFF’s Kurt Opsahl. Ross Anderson did an interview with Glenn Beck. And this news article talks about dissent within Apple about this feature.
The Economist has a good take. Apple responds to criticisms. (It’s worth watching the Wall Street Journalvideo interview as well.)
EDITED TO ADD (8/14): Apple released a threat model
EDITED TO ADD (8/20): Follow-on blog posts here and here.
Abstract: Cloud photo services are widely used for persistent, convenient, and often free photo storage, which is especially useful for mobile devices. As users store more and more photos in the cloud, significant privacy concerns arise because even a single compromise of a user’s credentials give attackers unfettered access to all of the user’s photos. We have created Easy Secure Photos (ESP) to enable users to protect their photos on cloud photo services such as Google Photos. ESP introduces a new client-side encryption architecture that includes a novel format-preserving image encryption algorithm, an encrypted thumbnail display mechanism, and a usable key management system. ESP encrypts image data such that the result is still a standard format image like JPEG that is compatible with cloud photo services. ESP efficiently generates and displays encrypted thumbnails for fast and easy browsing of photo galleries from trusted user devices. ESP’s key management makes it simple to authorize multiple user devices to view encrypted image content via a process similar to device pairing, but using the cloud photo service as a QR code communication channel. We have implemented ESP in a popular Android photos app for use with Google Photos and demonstrate that it is easy to use and provides encryption functionality transparently to users, maintains good interactive performance and image quality while providing strong privacy guarantees, and retains the sharing and storage benefits of Google Photos without any changes to the cloud service
At this year’s Apple Worldwide Developer Conference, Apple announcedsomething called “iCloud Private Relay.” That’s basically its private version of onionrouting, which is what Tor does.
Privacy Relay is built into both the forthcoming iOS and MacOS versions, but it will only work if you’re an iCloud Plus subscriber and you have it enabled from within your iCloud settings.
Once it’s enabled and you open Safari to browse, Private Relay splits up two pieces of information that — when delivered to websites together as normal — could quickly identify you. Those are your IP address (who and exactly where you are) and your DNS request (the address of the website you want, in numeric form).
Once the two pieces of information are split, Private Relay encrypts your DNS request and sends both the IP address and now-encrypted DNS request to an Apple proxy server. This is the first of two stops your traffic will make before you see a website. At this point, Apple has already handed over the encryption keys to the third party running the second of the two stops, so Apple can’t see what website you’re trying to access with your encrypted DNS request. All Apple can see is your IP address.
Although it has received both your IP address and encrypted DNS request, Apple’s server doesn’t send your original IP address to the second stop. Instead, it gives you an anonymous IP address that is approximately associated with your general region or city.
Not available in China, of course — and also Belarus, Colombia, Egypt, Kazakhstan, Saudi Arabia, South Africa, Turkmenistan, Uganda, and the Philippines.
The CEO of ‘Waterfall & Silo’ walks into the meeting room and asks his three internal advisors: How are we progressing with our enterprise transformation towards DevOps, business agility and simplification?
The well-prepared advisors, who had read at least a book and a half about organisational transformation and also watched a considerable number of Youtube videos, confidently reply: We are nearly there. We only need to get one more team on board. We have the first CI/CD pipelines established, and the containers are already up and running.
Unfortunately the advisors overlooked some details.
Two weeks later, the CEO asks the same question, and this time the response is: We only need to get two more teams on board, agree on some common tooling, the delivery methodology and relaunch our community of practice.
A month later, an executive decision is made to go back to the previous processes, tooling and perceived ‘customer focus’.
Two years later, the business closes its doors whilst other competitors achieve record revenues.
What has gone wrong, and why does this happen so often?
To answer this question, let’s have a look…
Why do you need to transform your business?
Without transforming your business, you will run the risk of falling behind because you are potentially:
Dealing with the drag of outdated processes and ways of working. Therefore your organisation cannot react swiftly to new business opportunities and changing market trends.
Wasting a lot of time and money on Undifferentiated heavy lifting (UHL). These are tasks that don’t differentiate your business from others but can be easily done better, faster and cheaper by someone else, for example, providing cloud infrastructure. Every minute you spend on UHL distracts you from focusing on your customer.
Not focusing enough on what your customers need. If you don’t have sufficient data insights or experiment with new customer features, you will probably mainly focus on your competition. That makes you a follower. Customer-focused organisations will figure out earlier what works for them and what doesn’t. They will take the lead.
How do you get started?
The biggest enablers for your transformation are the people in your business. If they work together in a collaborative way, they can leverage synergies and coach each other. This will ultimately motivate them. Delivering customer value is like in a team sport: not the team with the best player wins, but the team with the best strategy and overall team performance.
How do we get there?
Establishing top-performing DevOps teams
Moving towards cross-functional DevOps teams, also called squads, helps to reduce manual hand-offs and waiting times in your delivery. It is also a very scalable model that is used by many modern organisations that have a good customer experience at their forefront. This applies to a variety of industries, from financial services to retail and professional services. Squad members have different skills and work together towards a shared outcome. A top-performing squad that understands the business goals will not only figure out how to deliver effectively but also how to simplify the solution and reduce Undifferentiated Heavy Lifting. A mature DevOps team will always try out new ways to solve problems. The experimental aspect is crucial for continuous improvement, and it keeps the team excited. Regular feedback in the form of metrics and retrospectives will make it easier for the team to know that they are on the right track.
Understand your customer needs and value chain
There are different methodologies to identify customer needs. Amazon has the “working backwards from the customer” methodology to come up with new ideas, and Google has the “design sprint” methodology. Identifying your actual opportunities and understanding the landscape you are operating in are big challenges. It is easy to get lost in detail and head in the wrong direction. Getting the strategy right is only one aspect of the bigger picture. You also need to get the execution right, experiment with new approaches and establish strong feedback loops between execution and strategy.
This brings us to the next point that describes how we link those two aspects.
A bidirectional governance approach
DevOps teams operate autonomously and figure out how to best work together within their scope. They do not necessarily know what capabilities are required across the business. Hence you will need a governing working group that has complete visibility of this. That way, you can leverage synergies organisation-wide and not just within a squad. It is important that this working group gets feedback from the individual squads who are closer to specific business domains. One size does not fit all, and for some edge cases, you might need different technologies or delivery approaches. A bidirectional feedback loop will make sure you can improve customer focus and execution across the business.
Key takeaways
Establishing a mature DevOps model is a journey, and it may take some time. Each organisation and industry deals with different challenges, and therefore the journey does not always look the same. It is important to continuously tweak the approach and measure progress to make sure the customer focus can improve.
But if you don’t start the DevOps journey, you could turn into another ‘Waterfall & Silo’.
The retail market has changed a lot over the last years and Covid is often referenced as the main driver for digital transformation and self-service offerings. Retail customers can easily compare products and customer feedback online via various comparison websites and search engines.
The customers interact with the e-commerce application that allows them to search for products, purchase them and keep them updated about the delivery status. Customers do not care where the application is hosted or what the technology stack is. They care about things like usability, speed, features and they want to interact with the applications on different devices.
What is Cloud Native?
Cloud Native is an approach where your application leverages the advantages of the cloud computing delivery model. Cloud-native systems are designed to embrace rapid change, large scale, and resilience. With this approach you let AWS do the Undifferentiated Heavy Lifting and your team can focus on the actual application. For example, you can deploy your code to fully managed runtime environments that scale automatically and AWS manages all the operational aspects and security of those runtimes for you.
Why is Cloud Native a retail enabler?
Taking a customer centric view, you want to focus on the things that provide value to the customer. The most visible aspect of the retail solution is the actual application or service – not the IT infrastructure behind it. Therefore you want to make sure that your application keeps improving without wasting time and budget on things that can be commoditised.
Let’s look at an example: You run a coffee shop. You grind the beans so the coffee is fresh. Your customers can then enjoy a great tasting experience. This is the ultimate business value that the customer can see. You would not generate the electricity yourself, as an energy provider does that in a much more efficient way.
This is exactly the same with all the underlying infrastructure of your retail application: AWS can manage this for you in a much more efficient, secure and cost effective way. AWS calls all those activities that do not differentiate your business from others ‘Undifferentiated Heavy Lifting’. By handing all those Undifferentiated Heavy Lifting activities over to AWS you can focus on the things that really matter to your customers – like good coffee!
How do you get started?
If you start from scratch then you have an easier journey ahead because you can tap into all the cloud native offerings right from the beginning. For now we will assume that you already have an application and you want to move it to the cloud, leveraging the advantages of Cloud Native services. At the beginning of your journey you will make sure you have answers to some of the typical discovery questions, such as:
Understand your current state and pain points
Time to market:
Do you get new features out quick and often enough. If not, what is causing those delays?
Data insights and metrics:
What insights do you need to understand what your customers want and how you can increase your conversion rate?
Quality assurance and security:
Are there sufficient quality checks in place before you release new features or product catalogue items? Do you have guardrails in place that protect your team from security breaches?
Understand the Return on Investment of Cloud Native and why do you want to migrate
Lost opportunity:
What is the impact of not moving to cloud native? For example you will be slower in releasing new features than your competitors.
Operational simplification:
How can you focus more on your customer facing application when you remove the Undifferentiated Heavy Lifting?
Business agility:
Do you need geographic data isolation to meet regulatory requirements or do you need temporary environments for testing or demos?
Are your ways of working aligned with where you want to be in the future?
Internal collaboration:
Is your internal communication structure future proof? “Conways Law” describes how organisations design systems which mirror their own communication structure. This is one of many reasons why organisation move towards cross-functional delivery squads.
Team hand-offs:
Do you have many hand-offs during your software delivery life-cycle? This will slow down the process due to waiting times between team hand-offs and also potential communication gaps.
Skills:
Does your team have the required skills? By offloading the Undifferentiated Heavy Lifting to AWS the required skill set becomes narrower and your team can focus on training that is relevant for the application development and test automation.
How to expertly execute a Cloud Native approach
Understand your strategy:
Strategy:
The strategy will articulate why you want to achieve change and what principles will guide the the target state
Target State:
The target state describes where you eventually want to be. Words like ‘customer focus’ and ‘simplification’ should be on the forefront of your mind. Amazons “Working backwards from the customer” framework and the AWS Well Architected Framework can help you here.
Transitions:
The transition states describe how to get to your target state. The transition states are individual architecture blueprints that describe your transformation stages.
Build a roadmap
Define a backlog:
The backlog articulates the expected business outcomes typically in form of user stories that can be achieved within a sprint duration (1-2 weeks). Good user stories also include acceptance criteria and test cases.
Understand dependencies:
The backlog is driven by business outcomes but there will be some technical dependencies that dictate in which order some activities need to be completed. Understanding those dependencies is important to make sure the team can be productive and do not have unnecessary wait times.
Identify skill gaps and build a learning plan:
Once you build your backlog you get a better understanding of the required skills. This helps you to plan for training courses and other learning initiatives.
Build a governance framework
Strategic guidelines:
Having clear articulated guidelines in place will help you to speed up the decision process for any changes you will perform. Make sure the required teams are represented in your governance working group so that you don’t miss out any requirements and concerns.
Align with best practices:
There are lots of best practices that can be utilised rather than reinventing the wheel. The AWS Well Architected Framework for example can help you with architecture guidelines and principles.
Define how you measure success:
You need to know what good looks like: what does a good customer experience look like and what are your milestones? What is the productivity, team happiness and customer satisfaction that you need as a successful and sustainable retail business? Agree on a set of metrics that you can compare against. You can gradually build up these metrics.
Establish cross-functional teams (squads)
Squads:
A squad will have team members representing architecture, development, testing and technical business analysis. The goal is to establish an autonomous team that can tackle the user stories from the backlog. Depending on your organisation structure the squad will be represented by members from different business units.
Ceremonies:
Since the squad members can come from different business units, they might not have worked together before. Therefore a good team collaboration is crucial and agile ceremonies will help with that. Some of the key ceremonies are sprint planning, daily standups (maximum 15 minutes), a demo at the end of the sprint to show the stakeholders the produced outputs, followed by a retrospective to get feedback from the team.
Experiment:
When you change your ways of working approach it is easier to start small and pick an initiative that is not overly time critical. This way you can start with a smaller team, establish short feedback loops and tweak the approach for your organisation. The insights from the retrospective will help you to improve the process. Once you have established one successful squad you can start rolling out the new process further.
Measure your outcomes:
Feedback from your team:
Your team will provide feedback during the retrospective session at the end of each sprint. You can measure aspects like: How much did the team learn, did it feel like they delivered value? This gives you visibility of any trends and if any changes around the process result in better feedback.
Feedback from the customer:
There are several ways how you can measure this. Customer surveys are insightful if you ask the right questions. Statistics from your website will be very helpful for any retail organisation. You can measure things like average time on a page, bounce rate, exit rates, conversion rates. If you can link those numbers back to your releases and release changes you can actually see which website updates change the customer behaviour. Machine learning is another way how you can identify customer patterns and determine the sentiment of online chats or phone calls to a virtual call center like Amazon Connect.
Insights from your automation tools:
Your automation tools can provide metrics such as number of incidents, criticality, ratio of successful deployments, test coverage and many more. Once you can capture those metrics you can run historic comparison and project trends. If you link incidents to releases you will also get insights into the root cause of problems.
Key Cloud Native takeaways
Adopting Cloud Native is not just a technical challenge, it is a journey. If you want to turn it into a success story you need to consider the cultural changes and also a governance process that makes sure you are heading in the right direction. This can be complex and challenging when you haven’t done it before. The good news is that Anchor have championed it many times and we can help you on the journey.
If you’re an SMB or enterprise business with a sizable reliance on digital infrastructure, it is a common query to wonder if moving your online services to a cloud provider could allow you simplify your services, benefit from a network that is perceived to be infallible, and ultimately, to downsize on technical staff and slim down your IT spend.
Many businesses believe that without having to purchase their own server hardware, pay for data centre rackspace costs, or pay for quite so many staff members to manage it all, a significant amount of money can be saved on IT costs. However, while it is true that moving to the AWS cloud would reduce hardware and rackspace costs to nil, there are a number of new costs and challenges to consider.
Is the cloud actually cheaper?
Upon completing the migration from data centre hosting services to cloud hosting services, many businesses mistakenly believe that they will be able to lower their costs by downsizing on the number of IT staff they need to manage their technological infrastructure. This is not always the case. Cloud can require more extensive expertise to both set up and maintain on an ongoing basis as a trade-off for the other benefits offered.
AWS is a complex beast, and without proper support and planning, businesses can find their costs higher than they originally were, their services more complex and difficult to manage, as well as their online assets failing on an even more regular basis. Wasted cloud spend is a very common occurrence within the cloud services industry, with many cloud users not optimising costs where they can. In a 2019 report from Flexera, they measured the actual waste of cloud spending at 35 percent.
Why is it not such a simple switch?
Cloud is fundamentally a different approach to hosting and provides more opportunity, scale and complexity. Understanding how to make the most of those requires a thorough assessment of your infrastructure and business. It is, therefore, of pertinent importance to ensure that the IT staff that you do intend to retain are properly trained and qualified to manage cloud services.
Check out our blog, “What’s the difference between Traditional Hosting and AWS Cloud Hosting?” for more information on how the two environments greatly differ.
If your IT staff are more certified in AWS cloud management, you could be looking at higher costs than you started with. You would therefore need to factor in the costs of hiring new, properly qualified staff, or investing in upskilling existing staff – at the risk of losing that investment should the staff member leave in future.
The costs of qualified staff.
Certain types of AWS certified professionals are able to command some of the highest salaries in the cloud industry, due to the high level of expertise and capability that they can provide to a business. AWS engineers can maintain the performance and security of high- demand websites and software, optimising them for lower cost and better performance.
Large enterprises conducting a high volume of online transactions, or businesses that involve the handling of sensitive data would be in particular need of high-quality architects and engineers to keep their cloud environments both adequately optimised, reliable and safe. Though even as a small business, the build, deployment and operating of AWS services is always best conducted by experienced, AWS certified professionals to ensure the integrity and availability of your online services.
Oftentimes, the cost optimisations achieved by a high-quality AWS management service provider completely pay for themselves in what would otherwise be wasted spend. Check out our blog, “4 Important Considerations To Avoid Wasted Cloud Spend” to learn more about wasted cloud spend.
One of the most beneficial things an AWS management service provider can offer your business is ensuring that you’re only paying for what your business needs. It may save your business significantly more money in the long run, even when factoring in management fees.
If you’re interested in learning more about how managed AWS services can help your business to potentially slim down on IT spend, please contact our friendly AWS experts on 1300 883 979, or submit an enquiry through our website anytime.
COVID-19 has been an eye-opening experience for many of us. Prior to the current pandemic, many of us, as individuals, had never experienced the impacts of a global health crisis before. The same can very much be said for the business world. Quite simply, many businesses never considered it, nor had a plan in place to survive it.
As a consequence, we’ve seen the devastating toll that COVID-19 has had on some businesses and even entire sectors. According to an analysis by Oxford Economics, McKinsey and McKinsey Global Institute, certain sectors such as manufacturing, accommodation and food services, arts, entertainment and recreation, transportation and warehousing and educational services will take at least 5 years to recover from the impact of COVID-19 and return to pre-pandemic contributions to GDP. There is one industry however, that was impacted by the pandemic in the very opposite way; technology services.
The growth of our digital landscape
With many countries going into varying levels of lockdown, schools and workplaces shutting down their premises, and social distancing enforcement in many facets of our new COVID-safe lives, our reliance on technology has skyrocketed throughout 2020. In 2020, “buy online” searches increased by 50% over 2019, almost doubling during the first wave of the pandemic in March. Looking at statistics from the recent Black Friday sales event gives us a staggering further example of how much our lives have transitioned into the digital world.
In the US, Black Friday online searches increased by 34.13% this year. Even here in Australia, where there is significantly less tradition surrounding the Thanksgiving/Black Friday events, online searches for Black Friday still also increased by 34.39%. Globally, when you compare October 2019 to October 2020, online retail traffic numbers grew by a massive 30%, which accounts for billions of visitors.
Retail isn’t the only sector that now relies on the cloud far more heavily than ever before. Enterprises have also had to move even more of their operations into the cloud to accommodate the sudden need for remote working facilities. With lockdowns occurring all over the world for sometimes unknown lengths of time, businesses have had to quickly adapt to allow employees to continue their roles from their own homes. Likewise, the education sector is another who have had to adapt to providing their resources and services to students remotely. Cloud computing platforms, such as AWS, are the only viable platforms that are set up to handle such vast volumes of data while remaining both reliable and affordable.
Making the transition to online
With such clear growth in the digital sector, it makes sense that businesses who already existed online, or were quick to transition to an online presence at the start of the pandemic, have by far and large had the best chance at surviving. In the early months of the pandemic, many bricks and mortar businesses returned to their innovative roots, finding ways to digitise and mobilise their products and services. Many in the hospitality industry, for example, had to quickly adapt to online ordering and delivery to stay afloat, while many other businesses and sectors transitioned in new and unexpected ways too.
What many of these businesses had in common, was to decide somewhere along the way how to get online quickly, while being mindful of costs and long-term sustainability. When it comes to flexibility, availability and reliability, there really is no competition to cloud computing to be able to consistently deliver all three.
What is AWS Managed Cloud Hosting?
Amazon Web Services has taken over the world as one of the leading public cloud infrastructure providers, offering an abundance of products and services that can greatly assist you in bringing your business presence online.
AWS provides pay-as-you-go infrastructure that allows businesses to scale their IT resources with the business demand. Prior to the proliferation of cloud providers, businesses would turn to smaller localised companies, such as web hosts and software development agencies, to provide them with what they needed. Over recent years, things have greatly progressed as cloud services have become more expansive, integrated and able to cater to more complex business requirements than ever before.
When you first create an account with AWS and open up the console menu for the first time, the expansive nature of the services that they provide becomes very apparent.
Here, you’ll find all of the most expected services such as online storage facilities such as (S3), database hosting (RDS), DNS hosting (Route 53) and computing (EC2). But it doesn’t stop there, other popular services include Lambda, Lightsail and VPC, creating an array of infrastructure options large enough to host any environment. At the time of writing, there are 161 different services on offer in the AWS Management Console, spread out over 26 broader categories.
AWS Cloud Uptake during the Pandemic
Due to the flexible, scalable and highly reliable nature of AWS cloud hosting, the uptake of managed cloud services has continued to rise steadily throughout the pandemic. So far in 2020, AWS has experienced a 29% growth, bringing the total value up to a sizable $10.8bn.
With the help of an accredited and reputable AWS MSP (Managed Service Provider), businesses of all scales are able to digitise their operations quickly and cost-effectively. Whether you’re an SMB in the retail space who needs to provide a reliable platform for customers to find and purchase your goods, or an enterprise level business with thousands of staff members who rely on internal networks to perform their work remotely, AWS provides a vast array of services to cater to every need.
The thought of downtime can bring a chill to the bones of any IT team. Depending on the online demand you have for your products or services, even an hour or two of downtime can result in significant financial losses or catastrophic consequences of various other kinds.
As such, avoiding downtime should be a high priority item for any IT or Operations Manager. So, is the AWS cloud completely immune to downtime? We’ll discuss the various aspects of this question below.
The true cost of downtime
The true cost of downtime will vary from business to business, but whether you’re an SMB or an enterprise, all businesses that have critical services on the cloud should design their services from the ground up for high availability.
Gartner has reported the average cost of downtime to be $5,600 per minute. This varies between businesses, as no single business is run the exact same way or has the exact same setup, so at the low end this average could be more like $140,000 per hour, and $300,000 per hour on the high end.
To further break down their findings, Gartner’s research showed that 98% of organisations experience costs over $100,000 from a single hour of downtime. 81% of respondents said that 60 minutes of downtime costs their business in excess of $300,000. And 33% of enterprises found that that one hour of downtime cost them anywhere between $1-5 million.
Some of the causes for such a huge loss during and after a business experiences downtime can include some of the following:
Loss of sales
Certain business-critical data can become corrupted, depending on the outage
Costs of reviewing and resolving systems issues and processes
Detrimental reputational effect with stakeholders and customers
A drop in employee morale
A reduction in employee productivity
The always-online cloud services fallacy
Many businesses have migrated to the cloud and assumed that high availability is all a part of the cloud package, and doesn’t require any further expertise, investigation or implementation – however, this is not the case. To ensure high availability and uptime of internal systems and tools, a business must plan for this during its initial implementation. Properly setting up a business AWS environment for high availability requires an in-depth understanding of all that AWS has to offer, which is where a business can benefit greatly from outsourcing to an MSP that specialises in AWS cloud services.
Your business could experience more downtime with AWS than you would with a traditional hosting service.
Many people are surprised to learn that simply migrating to the cloud doesn’t automatically mean that their services will effectively become bullet-proof. In fact, the opposite can often be true.
AWS cloud services are complex and require extensive experience and in-depth knowledge to properly manage. This means there is a far greater chance for error when AWS services are being configured by an inexperienced user, leaving the services more vulnerable to security threats or performance issues that could ultimately result in downtime.
However, on the other hand, when AWS cloud services have been properly planned and configured from the ground up by certified professionals, the cloud can offer significantly greater availability and protection from downtime than traditional hosting services.
High Availability, Redundancy and Backups
‘High Availability’ is a term often attributed to cloud services, and refers to having multiple geographical regions where your website or application can be accessed from (as opposed to end-users always relaying requests back to a single server in one location). Because of the dynamic and data replicating nature of the cloud, some businesses mistake high availability for being inclusive of redundancy and backups.
High availability can refer to redundancy in the sense that should one geographical access point suffer an outage, and another can automatically step in to cater to an end-user’s request. However, it does not mean that your website or application does not still also require an effective backup and disaster recovery plan.
Should something go wrong with your cloud services, or certain parts of your environment become unavailable, you will need to rely on your own plan for replication or recovery. AWS offers a range of options to cater to this, and these should always be carefully considered and implemented during the planning and building phases.
How can you best protect your business from downtime?
So, to answer the question “Are AWS cloud services immune to downtime?”, the answer is no, as it would be for any form of technology. At this time, there is no technology that can truly claim to be entirely failsafe. However, AWS cloud services can get your business as close to failsafe as it is possible to get – if it’s done right.
For businesses that are serious about ensuring their online operations are available as much as possible, such as those involved in providing critical care, high demand eCommerce environments, or enterprise-level tools and systems, it’s essential to have your cloud services designed by a team of certified AWS professionals who have the correct credentials and expertise. If you’re interested in discussing this further, please don’t hesitate to get in touch with our expert team for a free consultation.
If you’re an IT Manager or Operations Manager who has considered moving your company’s online assets into the AWS cloud, you may have started by wondering, what is it truly going to involve?
One of the first decisions you will need to make is whether you are going to approach the cloud with the assistance of an AWS managed service provider (AWS MSP), or whether you intend to fully self-manage.
Whether or not a fully managed service is the right option for you comes down to two pivotal questions;
Do you have the technical expertise required to properly deploy and maintain AWS cloud services?
Do you, or your team, have the time/capacity to take this on – not just right now, but in an ongoing capacity too?
Below, we’ll briefly cover some of the considerations you’ll need to make when choosing between fully managed AWS Cloud Services and Self-Managed AWS Cloud Services.
Self-Managed AWS Services
Why outsource the management of your AWS when you can train your own in-house staff to do it?
With self-managed AWS Services, this means you’re responsible for every aspect of the service from start to finish. Managing your own services allows for the benefit of ultimate control, which may be beneficial if you require very specific deployment conditions or software versions to run your applications. It can also allow you to very gradually test your applications within their new infrastructure, and learn as you go.
This will result in knowing how to manage and control your own services on a closer level, but it comes with the downside of a very heavy learning curve and time investment if you have never entered the cloud environment before. In the context of a business or corporate environment, you’d also need to ensure that multiple staff members go through this process to ensure redundancy for staff availability and turnover. You’d also need in either case to invest in continuous development to keep up with the latest best practices and security protocols, because the cloud, like any technical landscape, is fast-paced and ever-changing.
This can end up being a significant investment in training and staff development. As employees are never guaranteed to stay, there is the risk of that investment, or at least substantial portions of it, disappearing at some point.
At the time of writing, there are 450 items in the AWS learning library, for those looking to self-learn. In terms of taking exams to obtain official accreditation, AWS offers 3 levels of certification at present, starting with Foundational, through to Associate, and finally, Professional. To reach the Professional level, AWS requires “Two years of comprehensive experience designing, operating, and troubleshooting solutions using the AWS Cloud”.
Fully Managed AWS Services
Hand the reins over to accredited professionals.
Fully-managed AWS services mean you’ll reap all of the extensive benefits of moving your online infrastructure into the cloud, without taking on the responsibility of setting up or maintaining those services.
You will hand over the stress of managing backups, high availability, software versions, patches, fixes, dependencies, cost optimisation, network infrastructure, security, and various other aspects of keeping your cloud services secure and cost-effective. You won’t need to spend anything on staff training or development, and there is no risk of losing control of your services when internal staff come and go. Essentially, you will be handing the reins over to a team of experts who have already obtained their AWS certifications at the highest level, with collective decades of experience in all manner of business operations and requirements.
The main risk here is choosing where the right place to outsource your AWS management is. When choosing to outsource AWS cloud management, you’ll want to be sure the AWS partner you choose offers the level of support you are going to require, as well as hold all relevant certifications. When partnered with the right AWS MSP team, you’ll also often find that the management fees pay for themselves due to the greater level of AWS cost optimisation that can be achieved by seasoned professionals.
If you’re interested in finding out an estimation of professional AWS cloud management costs for your business or discussing how your business operations could be improved or revolutionised through the AWS cloud platform, please don’t hesitate to get in touch with our expert team for a free consultation. Our expert team can conduct a thorough assessment of your current infrastructure and business, and provide you with a report on how your business can specifically benefit from a migration to the AWS cloud platform.
Year after year, AWS maintains a very significant lead in the cloud marketplace over its closest competitors, including Microsoft Azure, Google Cloud Platform, as well as a number of other smaller cloud providers.
According to recent research published by Synergy Research Group, Amazon has 33% of the cloud infrastructure market share, with Microsoft trailing behind at 18%, and Google sitting at 9%.
So why has Amazon always been the leader of the pack when it comes to the major cloud service providers? The reasons for AWS’ significant lead may be more simple than you would first think. Below, we will go into just a few of the many reasons AWS has maintained such a dominant lead since its conception.
It’s Been Around The Longest
In any race, one of the most valuable things you can have is a head start. Amazon launched Amazon Web Services (AWS) back in 2006 and began offering their initial cloud computing service offerings to, primarily, developers. Their initial service offerings included Amazon S3 cloud storage, SQS, and EC2.
Google and Microsoft had dabbled in their own Cloud offerings at the time, but didn’t put the same resources into it that Amazon did. Google launched their Cloud Platform in 2008, and Microsoft Azure later followed them and launched in 2010. However, neither Google nor Microsoft invested the same amount of resources early on. As a result, Amazon was able to establish a firm lead in the cloud services market. Other providers have been playing a never-ending battle of catch-up ever since.
Constant Innovation
Although we can attribute a lot of AWS’ success to their early foothold, they wouldn’t be able to maintain such a significant market share on that alone. Since the beginning, Amazon has continually innovated year after year.
Since 2006, Amazon have greatly increased their service offerings and created many innovative services. In fact, at the time of writing, AWS offers an astounding 175 individual products and services to consumers. Many of these services are original Amazon innovations. You would be hard-pressed to find a task you can’t accomplish with one of Amazon’s many services, and they’re only adding more and more to their catalogue each year. We expect to see a specific focus on Artificial Intelligence Services from Amazon in the next few years, as it’s one of the fastest-growing areas of cloud computing.
Price Cuts
One of the greatest reasons AWS stays not only incredibly competitive, while still leading the market, is their constant efforts to reduce consumer costs. In fact, research published in 2018 by TSO Logic found that AWS costs get lower every year. AWS has no problem maintaining their existing customer base with increasingly diminishing prices, while also attracting new customers. Plus, the larger AWS gets, the more ability they have to achieve even higher economies of scale, thus passing more price cuts onto their customers.
In Amazon’s own words, they state the following on their website:
“Benefit from massive economies of scale – By using cloud computing, you can achieve a lower variable cost than you can get on your own. Because usage from hundreds of thousands of customers is aggregated in the cloud, providers such as AWS can achieve higher economies of scale, which translates into lower pay as-you-go prices.”
Backed by Amazon
With the full long-term backing of Amazon, which comes in at #3 worldwide of all public corporations by market capitalization, AWS is quite simply a juggernaut of resources and capability. At the time of writing, Amazon has an estimated net value of $1.14 trillion. Amazon’s founder, Jeff Bezos, has an estimated worth of $190 billion.
With these kinds of numbers, Amazon are of course a formidable opponent for any newcomers to the cloud services marketplace. They also don’t look to be slowing down anytime soon in terms of their vision for the future and upcoming technological innovations.
Conclusion
AWS provides a platform which is ever-evolving and constantly becoming more financially accessible for businesses of all sizes. With new offerings, technology, features and opportunities for performance improvements every year, AWS provides a solid and proven platform for businesses who are looking to bring their business into the cloud.
If you think your business may benefit from taking advantage of AWS’ huge range of services, get in touch with us today for an expert consultation on how we can assist you in your journey to the cloud.
Business leaders know all too well the long list of challenges involved in taking any business to the next level. Cash flow, human resources, infrastructure, growing marketing spend, refining or expanding on processes, and company culture are just a few of the many considerations. One particularly important challenge is choosing the right software and tools early on, to allow your business to provide its products or services efficiently and cost-effectively.
One of the greatest ways to achieve reliable and harmonious business practices is to ensure the technological infrastructure that your business is built upon is carefully planned to not only cater to your immediate business needs but also to be flexible for future growth.
Cloud computing services are more popular than ever before, and even in the face of the COVID-19 pandemic, have continued to grow just as steadily. Below, we’ve outlined 5 common business problems that are solved by migration to AWS cloud. If you’ve been considering the potential advantages of AWS for your business, read on!
Common problem: Convoluted/expensive/unnecessary services within pre-packaged traditional hosting plans.
With traditional hosting services, products tend to be pre-packaged with a selection of commonly required services as well as tiered/set resources. As a business grows larger and requires more heavy-duty online infrastructure, the cost of pre-packaged services can become much more expensive than it needs to be. That is because you may not be using some of the inclusions provided with these services, or require less of one resource or more of another. Pre-packaged service pricing also generally has factored in the cost of software licences needed to deliver all of the inclusions offered. If you’re not using these services, why should you be paying for them?
How AWS cloud computing services solves this: With AWS cloud hosting, each individual service is billed separately, and charges are based on different metrics such as the number of hours or seconds a service is online, or how much data transfer takes place. This allows a business to have very granular control over where they are directing their spend, as well as offering the ability to avoid paying for service inclusions that they are simply not using.
Common problem: Cost creep over time.
Cost creep is a common problem both in traditional hosting services and cloud computing services. As your business grows and evolves, your online infrastructure may need access to more services, features or integrations, as well as more computing resources. Each of these things almost always comes with an additional cost.
How AWS cloud computing services solves this: Between traditional hosting services and cloud computing, cloud is the only one that offers a plethora of ways to prevent, monitor and even reverse cost creep over time. Cost creep is a common occurrence for many businesses, especially in the early deployment stages when traffic is the least predictable and resource requirements are difficult to allocate in advance. This is something that can be greatly improved over time as usage data becomes available, along with traffic and resource usage patterns of your website or application. With proper maintenance and the utilisation of AWS reserved instances (which can provide the same resources at a greatly lower cost), there are many opportunities to minimise, and even reverse cost creep over time with cloud services.
Common problem: Infrastructure that offers a lack of horizontal scaling.
Horizontal scaling can translate to cost efficiencies, by adding or removing computing resources, and only paying for them while you are actually using them. For example, say you were running a food delivery application where you required a lot of computing resources to handle traffic during the lunch and dinner rush. If you were to purchase a computing instance with enough power to handle the rush hour, that might become an expensive waste of resources to still be running when business is quiet at 4 am. This is where horizontal scaling can come in to maximise efficiency through the addition and reduction of additional computing power, as needed.
Traditional hosting services rarely offer horizontal scalability, meaning you will be overpaying for resources or services that you aren’t utilising a lot of the time.
How AWS cloud computing services solves this: AWS offers powerful options when it comes to horizontally scaling computing power on demand. Scaling horizontally means adding additional computing instances to support an application running on an existing instance, as needed.
One of the greatest advantages of cloud computing services such as AWS is that their range of services are billed by the amount of time you are using them. So horizontal scaling can translate to cost efficiencies, by adding or removing computing resources, and only paying for them while you are actually using them.
Growth for cloud services is at an all-time high in 2020, partly due to the COVID-19 pandemic and businesses scrambling to migrate to the cloud as soon as possible. But with that record growth, wasted spend on unnecessary or unoptimised cloud usage is also at an all-time high.
Wasted cloud spend generally boils down to paying for services or resources that you aren’t using. You can most commonly attribute wasted spend on services that aren’t being used at all in either the development or production stages, services that are often idle (not being used 80-90% of the time), or simply over-provisioned resources (more resources than necessary).
Wasted cloud spend is expected to reach as high as $17.6 billion in 2020. In a 2019 report from Flexera, they measured the actual waste of cloud spending at 35 percent of all cloud services revenue. This highlights how crucial it can be, and how much money a business can save, by having an experienced and dedicated AWS management team looking after their cloud services. In many cases, having the right team managing your cloud services can more than repay any associated management costs. Read on below for some further insight into the most common pitfalls of wasted cloud spending.
Lack Of Research, Skills and/or Management
A lack of proper research, skills or management involved in a migration to cloud services is probably the most frequent and costly pitfall. Without proper AWS cloud migration best practices and a comprehensive strategy in place, businesses may dive into setting up their services without realising how complex the initial learning curve can be to sufficiently manage their cloud spend. It’s a common occurrence for not just businesses, but anyone first experimenting with cloud, to see a bill that’s much higher than they first anticipated. This can lead a business to believe the cloud is significantly more expensive than it really needs to be.
It’s absolutely crucial to have a strategy in place for all potential usage situations, so that you don’t end up paying much more than you should. This is something that a managed cloud provider can expertly design for you, to ensure that you’re only paying for exactly what you need and potentially quite drastically reducing your spend over time.
Unused Or Unnecessary Snapshots
Snapshots can create a point in time backup of your AWS services. Each snapshot contains all of the information that is needed to restore your data to the point when the snapshot was taken. This is an incredibly important and useful tool when managed correctly. However it’s also one of the biggest mistakes businesses can make in their AWS cloud spend.
Charges for snapshots are based on the amount of data stored, and each snapshot increases the amount of data that you’re storing. Many users will take and store a high number of snapshots and never delete them when they’re no longer needed, and in a lot of cases, not realise that this is exponentially increasing their cloud spend.
Idle Resources
Idle resources account for another of the largest parts of cloud waste. Idle resources are resources that aren’t being used for anything, yet you’re still paying for them. They can be useful in the event of resource spike, but for the most part may not be worth you paying for them when you look at your average usage over a period of time. A good analogy for this would be paying rent for a holiday home all year round, when you only spend 2 weeks using it every Christmas. This is where horizontal scaling comes into play. When set up by skilled AWS experts, horizontal scaling can turn services and resources on or off depending on when they are actually needed.
Over-Provisioned Services
This particular issue somewhat ties into idle resources, as seen above. Over-provisioned services refers to paying for entire instances that are not in use whatsoever, or very minimally. This could be an Amazon RDS service for a database that’s not in use, an Amazon EC2 instance that’s idle 100% of the time, or any number of other services. It’s important to have a cloud strategy in place that involves frequently auditing what services your business is using and not using, in order to minimise your cloud spend as much as possible.
Conclusion
As you can see from the statistics provided by Flexera above, wasted cloud spend is one of the most significant problems facing businesses that have migrated to the cloud. But with the right team of experts in place, wasted spend can easily be avoided, and even mitigate management costs, leaving you in a far better position in terms of both service performance, reliability and support, and overall costs.
Some of us may have learnt during 2020 that there are simply some things that one cannot DIY without proper skills and expertise. Perhaps during the pandemic lockdown, your local hairdresser was closed, and you turned to a DIY YouTube tutorial and learnt this the hardest way of all. But, even if you survived 2020 without a fringe 2 inches too short, managing AWS services is a whole other ball game that requires years of training and dedicated skill to properly deploy, manage and keep expenses under control.
As powerful as AWS is, and as much as it can do for your business, it can be all-but impossible to do it right if you have never set foot in the AWS Management console before. AWS is complex, and requires expertise to truly get the most from it. While you may be able to perform basic provisioning tasks and perhaps get a service up and running, ensuring that that service is performing optimally and cost-efficiently is where professional AWS management can truly revolutionise your infrastructure strategy and budget.
Managed AWS services is one of the largest outsourced areas of the IT industry. According to a recent Gartner forecast, almost 19% of cloud budgets are spent on cloud management-related services, such as cloud consulting, implementation, migration and managed services – with this percentage expected to increase in the next few years (and for good reason). In this article we will delve into just a few of the reasons why you’re far better off putting your AWS management in the hands of experts.
Cost Savings
Wasted cloud spend is a very common occurrence within the cloud services industry, with many cloud users not optimising costs where they can. In a 2019 report from Flexera, they measured the actual waste of cloud spending at 35 percent.
One of the most beneficial things an AWS management service provider can offer your business is ensuring that you’re only paying for what your business needs. It may save your business significantly more money in the long run, even when factoring in management fees.
Free Up Your Time
You should focus on what you and your business do best. Sure, you could put in many hours to understand as much as possible and get up and running yourself, but many businesses find that time is much better spent on focussing on your core service offerings and leaving management to your managed service provider.
On top of the initial learning curve, there is also the time investment needed for ongoing training as new AWS cloud services are released and new management tools are developed. Best practice changes very frequently, and it can be a significant undertaking to try and keep your finger on the pulse while simultaneously trying to handle every other area of your business.
Proactive Management
Ensuring that your business leverages AWS’ ability to scale and adjust depending on your current needs is essential. An AWS partner and managed service provider can help you understand your businesses needs, and adjust course as necessary to meet each new scenario.
A good example of scaling to meet current needs is the COVID-19 pandemic. The cloud services industry has seen significant growth during 2020 due to its ability to rapidly scale and support sudden growth. For example, web traffic and bandwidth requirements skyrocketed in 2020 with more people turning to eCommerce to acquire their everyday household items as well as remotely attend school and work.
Avoiding Downtime and Increasing Stability
Any number of things can happen to your hosted services, and when they do, it’s crucial that you have an experienced team on hand to tackle whatever comes your way. There’s nothing worse than hosting your mission-critical services on AWS and not having the experience to get services up and running as soon as possible when things go wrong.
A qualified AWS management team will also put best practice measures into place to improve the resilience of your configuration, and minimise the chance of anything going wrong in the first place.
Conclusion
When deciding what is the best course of action for your business, it’s imperative to ensure that your mission-critical cloud services are in good hands. It can be shown that in many cases, having AWS experts handle your businesses cloud needs can more than repay the associated management fees, leaving you better off both in terms of support and costs.
If you’re looking for advice on AWS cloud migration best practices, don’t hesitate to get in touch with one of our expert cloud architects today.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.