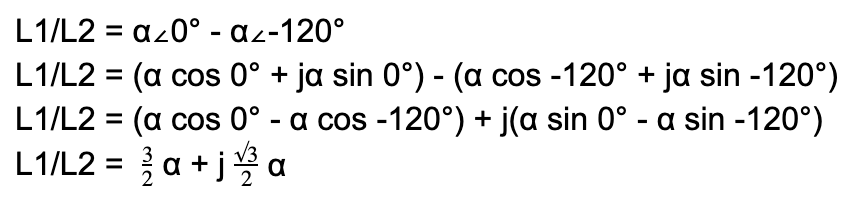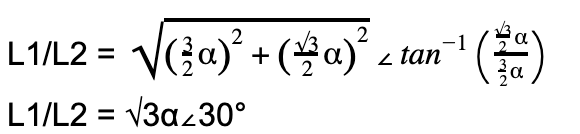Having fast Internet properties means being as few milliseconds as possible away from our customers and their users, no matter where they are on Earth. And because of the design of Cloudflare’s network we don’t just make Internet properties faster by being closer, we bring our Zero Trust services closer too. So whether you’re connecting to a public API, a website, a SaaS application, or your company’s internal applications, we’re close by.
This is possible by adding new cities, partners, capacity, and cables. And we have seen over and over again how making the Internet faster in a region also can have a clear impact on traffic: if the experience is quicker, people usually do more online.
Cloudflare’s network keeps increasing, and its global footprint does so accordingly. In April 2022 we announced that the Cloudflare network now spans 275 cities and the number keeps growing.
In this blog post we highlight the deployment of our data center in Hagatna, Guam.
Why a blog about Guam?
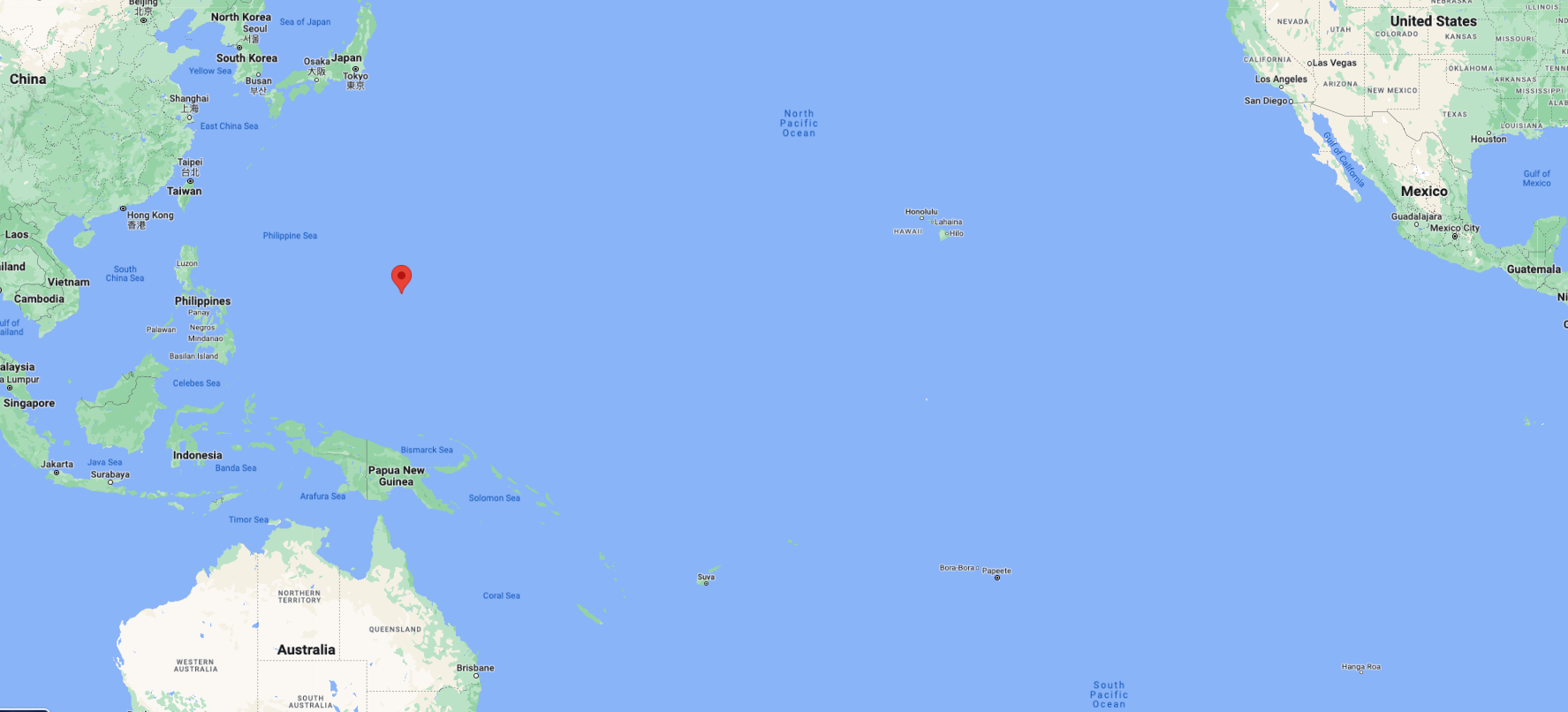
Guam is about 2,400 km from both Tokyo in the north and Manila in the west, and about 6,100 km from Honolulu in the east. Honolulu itself is the most remote major city in the US and one of the most remote in the world, the closest major city from it being San Francisco, California at 3,700 km. From here one can derive how far Guam is from the US to the west and from Asia to the east.
Figure 1: Guam Geographical Location.
Why is this relevant? As explained here, latency is the time it takes for data to pass from one point on a network to another. And one of the main reasons behind network latency is the distance between client devices — like a browser on a mobile phone — making requests and the servers responding to those requests. So, if we consider where Guam is geographically, we get a good picture about how Guam’s residents can be affected by the long distances their Internet requests, and responses, have to travel.
This is why every time Cloudflare adds a new location, we help make the Internet a bit faster. The reason is that every new location brings Cloudflare’s services closer to the users requested them. As part of Cloudflare’s mission, the Guam deployment is a perfect example of how we are going from being the most global network on Earth to the most local one as well.
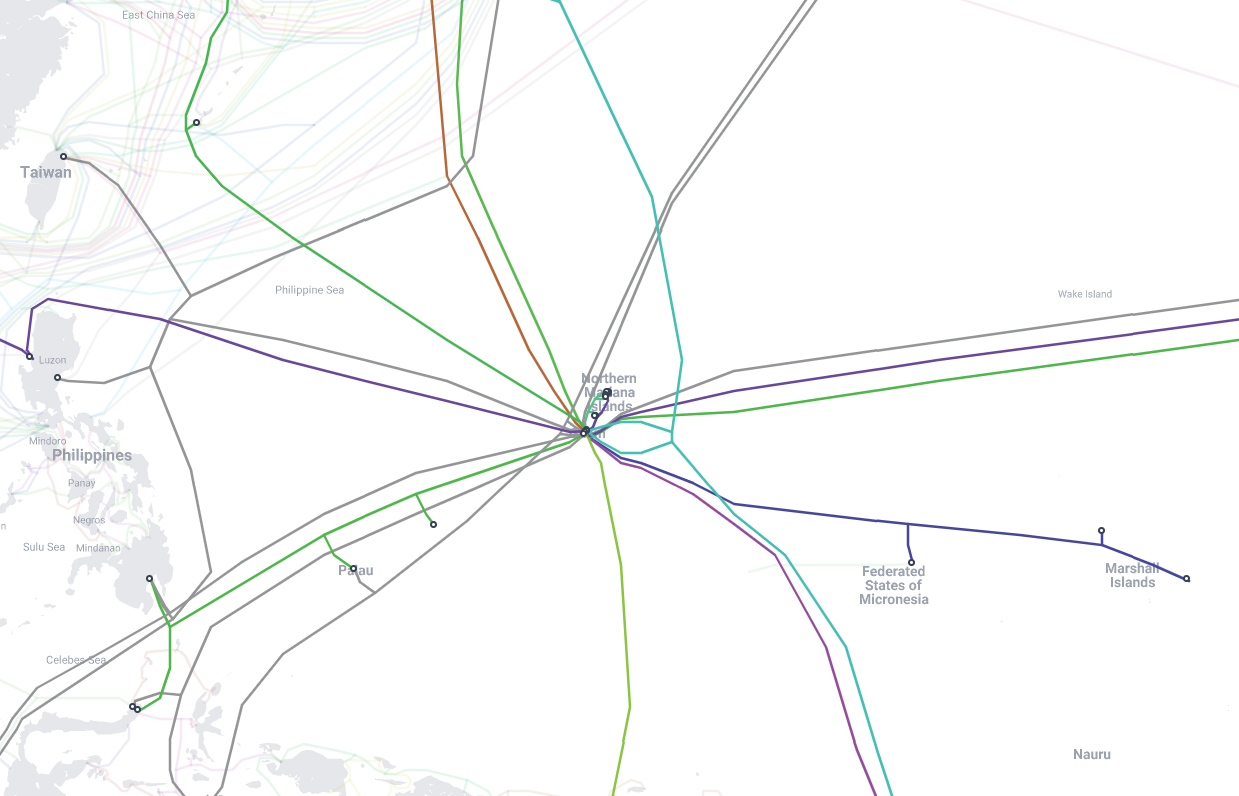
A closer look at specific submarine cables landing in Guam show us that the region is actually well served in terms of submarine cables, with several connections to the mainland such as Japan, Taiwan, Philippines, Australia, Indonesia and Hawaii, therefore making Guam more resilient to matters such as the one that affected Tonga in January 2022 due to the impact of a volcanic eruption on submarine cables – we wrote about it here.
The picture above also shows the relevance of Guam for other even more remote locations, such as the Federated States of Micronesia (FSM) or the Marshall Islands, which have an ‘extra-hop’ to cover when trying to reach the rest of the Internet. Palau also relies on Guam but, from a resilience point of view, has alternatives to locations such as the Philippines or to Australia.
As there are multiple participants, these are being added gradually. The first was AS 7131, being served from April 2022, and the latest addition is AS 9246, from July 2022.
As some of these ASNs or ASs (autonomous systems — large networks or group of networks) have their own downstream customers, further ASs can leverage Cloudflare’s deployment at Guam, examples being AS 17893 – Palau National Communications Corp – or AS 21996 – Guam Cell.
Therefore, the Cloudflare deployment brings not only a better (and generally faster) Internet to Guam’s residents, but also to residents in nearby archipelagos that are anchored on Guam. In May 2022, according to UN’s forecasts, the covered resident population in the main areas in the region stands around 171k in Guam, 105k in FSM and 60k in the Marshall Islands.
For this deployment, Cloudflare worked with the skilled MARIIX personnel for the physical installations, provisioning and services turn-up. Despite the geographical distance and time zone differences (Hagatna is 9 hours ahead of GMT but only two hours ahead of the Cloudflare office in Singapore, so the time difference wasn’t a big challenge), all the logistics involved and communications went smoothly. A recent blog posted by APNIC, where we can see some personnel with whom Cloudflare worked, reiterates the valuable work being done locally and the increasing importance of Guam in the region.
Performance impact for local/regional habitants
Before Cloudflare’s deployment in Guam, customers of local ASs trying to reach Internet properties via Cloudflare’s network were redirected mainly to Cloudflare’s deployments in Tokyo and Seattle. This is due to the anycast routing used by Cloudflare — as described here; anycast typically routes incoming traffic to the nearest data center. In the case of Guam, and as previously described, these large distances to the nearest locations represents a distance of thousands of kilometers or, in other words, high latency thus affecting user experience badly.
With Cloudflare’s deployment in Guam, Guam’s and nearby archipelagos’ residents are no longer redirected to those faraway locations, instead they are served locally by the new Cloudflare servers. Although a decrease of a few milliseconds may not seem a lot, it actually represents a significant boost in user experience as latency is dramatically reduced. As the total distance between users and servers is reduced, load time is reduced as well. And as users very often quit waiting for a site to load when the load time is high, the opposite occurs as well, i.e., users are more willing to stay within a site if loading times are good. This improvement represents both a better user experience and higher use of the Internet.
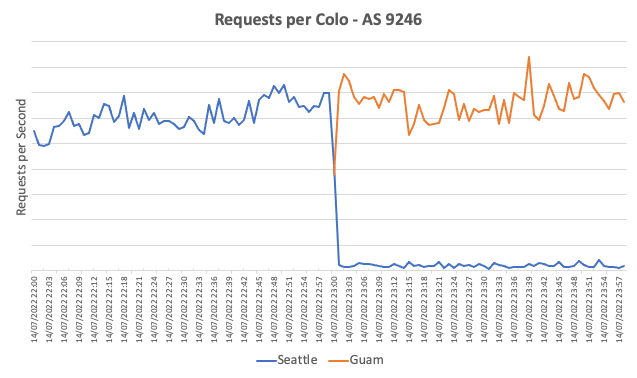
In the case of Guam, we use AS 9246 as an example as it was previously served by Seattle but since around 23h00 UTC 14/July/2022 is served by Guam, as illustrated below:
Figure 3: Requests per Colo for AS 9246 Before vs After Cloudflare Deployment at Guam.
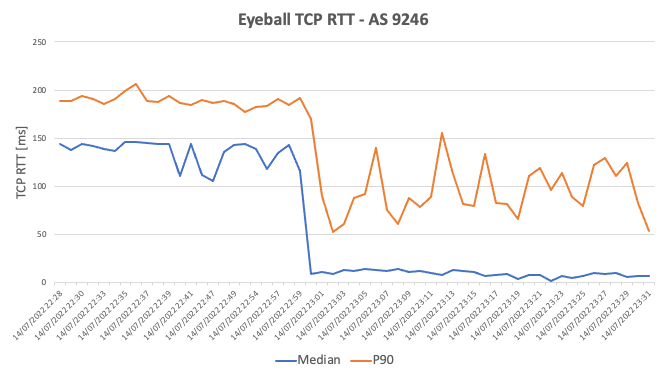
The following chart displays the median and the 90th percentile of the eyeball TCP RTT for AS 9246 immediately before and after AS 9246 users started to use the Guam deployment:
Figure 4: Eyeball TCP RTT for AS 9246 Before vs After Cloudflare Deployment at Guam.
From the chart above we can derive that the overall reduction for the eyeball TCP RTT immediately before and after Guam’s deployment was:
Median decreased from 136.3ms to 9.3ms, a 93.2% reduction;
P90 decreased from 188.7ms to 97.0ms, a 48.5% reduction.
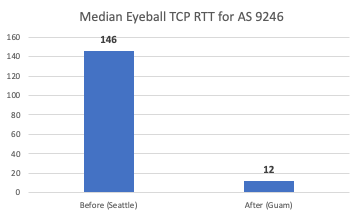
When comparing the [12h00 ; 13h00] UTC period of the 14/July/2022 (therefore, AS 9246 still served by Seattle) vs the same hour but for the 15th/July/2022 (thus AS9246 already served by Guam), the differences are also clear. We pick this period as this is a busy hour period locally since local time equals UTC plus 10 hours:
Figure 5 – Median Eyeball TCP RTT for AS 9246 from Seattle vs Guam.
The median eyeball TCP RTT decreased from 146ms to 12ms, i.e., a massive 91.8% reduction and perhaps, due to already mentioned geographical specificities, one of Cloudflare’s deployments representing a larger reduction in latency for the local end users.
Impact on Internet traffic
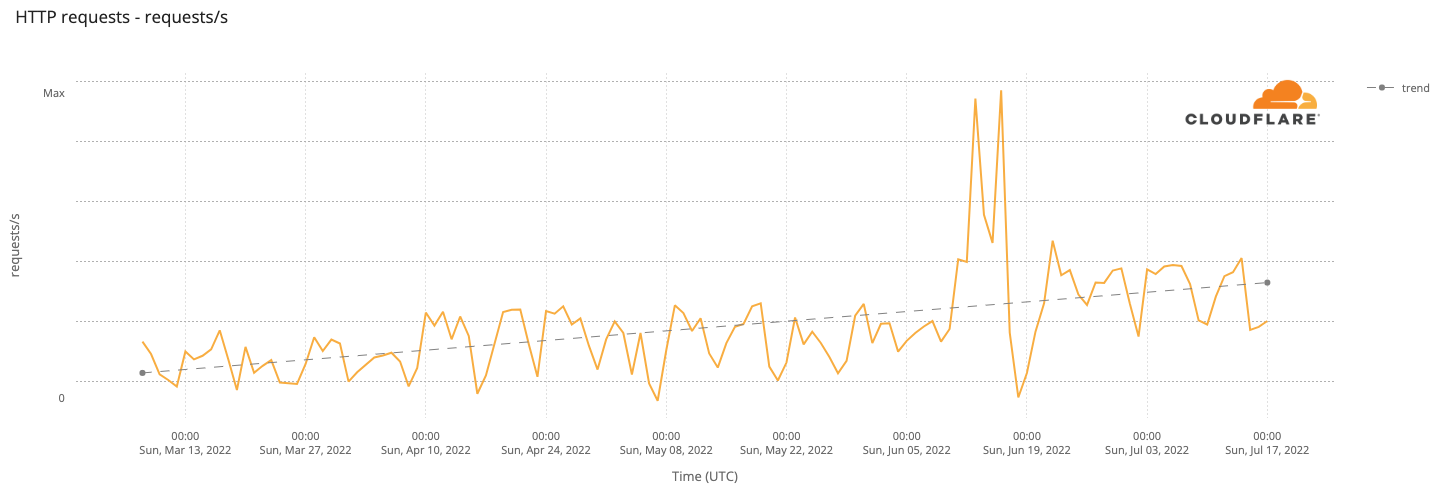
We can actually see an increase in HTTP requests in Guam since early April, right when we were setting up our Guam data center. The impact of the deployment was more clear after mid-April, with a further step up in mid-June. Comparing March 8 with July 17, there was an 11.5% increase in requests, as illustrated below:
Figure 6: Trend in HTTP Requests per Second in Guam.
Edge Partnership Program
If you’re an ISP that is interested in hosting a Cloudflare cache to improve performance and reduce backhaul, get in touch on our Edge Partnership Program page. And if you’re a software, data, or network engineer – or just the type of person who is curious and wants to help make the Internet better – consider joining our team.
Cloudflare’s network keeps growing, and that growth doesn’t just come from building new data centers in new cities. We’re also upgrading the capacity of existing data centers by adding newer generations of servers — a process that makes our network safer, faster, and more reliable for our users.
Connecting new Cloudflare servers to our network has always been complex, in large part because of the amount of manual effort that used to be required. Members of our Data Center and Infrastructure Operations, Network Operations, and Site Reliability Engineering teams had to carefully follow steps in an extremely detailed standard operating procedure (SOP) document, often copying command-line snippets directly from the document and pasting them into terminal windows.
But such a manual process can only scale so far, and we knew must be a way to automate the installation of new servers.
Here’s how we tackled that challenge by building our own Provisioning-as-a-Service (PraaS) platform and cut by 90% the amount of time our team spent on mundane operational tasks.
Choosing and using an automation framework
When we began our automation efforts, we quickly realized it made sense to replace each of these manual SOP steps with an API-call equivalent and to present them in a self-service web-based portal.
To organize these new automatic steps, we chose Apache Airflow, an open-source workflow management platform. Airflow is built around directed acyclic graphs, or DAGs, which are collections of all the tasks you want to run, organized in a way that reflects their relationships and dependencies.
In this new system, each SOP step is implemented as a task in the DAG. The majority of these tasks are API calls to Salt — software which automates the management and configuration of any infrastructure or application, and which we use to manage our servers, switches, and routers. Other DAG tasks are calls to query Prometheus (systems monitoring and alerting toolkit), Thanos (a highly available Prometheus setup with long-term storage capabilities), Google Chat webhooks, JIRA, and other internal systems.
Here is an example of one of these tasks. In the original SOP, SREs were given the following instructions to enable anycast:
Login to a remote system.
Copy and Paste the command in the terminal.
Replace the router placeholder in the command snippet with the actual value.
Execute the command.
MeanwhileIn our new workflow, this step becomes a single task in the DAG named “enable_anycast”:
As you can see, automation eliminates the need for a human operator to login to a remote system, and to figure out the router that will be used to replace the placeholder in the command to be executed.
In Airflow, a task is an implementation of an Operator. The Operator in the automated step is the “AsyncSaltAPIOperator”, a custom operator built in-house. This extensibility is one of the many reasons that made us decide to use Apache Airflow. It allowed us to extend its functionality by writing custom operators that suit our needs.
SREs from various teams have written quite a lot of custom Airflow Operators that integrate with Salt, Prometheus, Bitbucket, Google Chat, JIRA, PagerDuty, among others.
Manual SOP steps transformed into a feature-packed automation
The tasks that replaced steps in the SOP are marvelously feature-packed. Here are some highlights of what they are capable of, on top of just executing a command:
Failure Handling When a task fails for whatever reason, it automatically retries until it exhausts its maximum retry limit that we set for the task. We employ various retry strategies, including instructing tasks to not retry at all, especially when it’s impractical to retry, or when we deliberately do not want it to retry at all regardless of whether there are any retry attempts remaining, such as when an exception is encountered or a condition that is unlikely to change for the better.
Logging Each task provides a comprehensive log during executions. We’ve written our tasks to ensure that we log as much information as possible that would help us audit and troubleshoot issues.
Notifications We’ve written our tasks to send a notification with information such as the name of the DAG, the name of the task, its task state, the number of attempts it took to reach a certain state, and a link to view the task logs.
When a task fails, we definitely want to be notified, so we also set tasks to additionally provide information such as the number of retry attempts and links to view relevant wiki pages or Grafana dashboards.
Depending on the criticality of the failure, we can also instruct it to page the relevant on-call person on the provisioning shift, should it require immediate attention.
Jinja Templating Jinja templating allows providing dynamic content using code to otherwise static objects such as strings. We use this in combination with macros wherein we provide parameters that can change during the execution, since macros are evaluated while the task gets run.
Macros Macros are used to pass dynamic information into task instances at runtime. Macros are a way to expose objects to templates. In other words, macros are functions that take input, modify that input, and give the modified output.
Adapting tasks for preconditions and human intervention
There are a few steps in the SOP that require certain preconditions to be met. We use sensors to set dependencies between these tasks, and even between different DAGs, so that one does not run until the dependency has been met.
Below is an example of a sensor that waits until all nodes resolve to their assigned DNS records:
In addition, some of our tasks still require input from a human operator. In these circumstances, we use sensors as blocking tasks that prevent work from starting until certain preconditions are met. We use these to set dependencies between tasks and even DAGs so that one does not run until the dependency has finished successfully.
The code below is a simple example of a task that will send notifications to get the attention of a human operator, and waits until a Change Request ticket has been provided and verified:
verify_jira_input = builder.wrap_class(InputSensor)(
task_id='verify_jira_input',
var_key='jira',
prompt='Please provide the Change Request ticket.',
notify=True,
require_human=True)
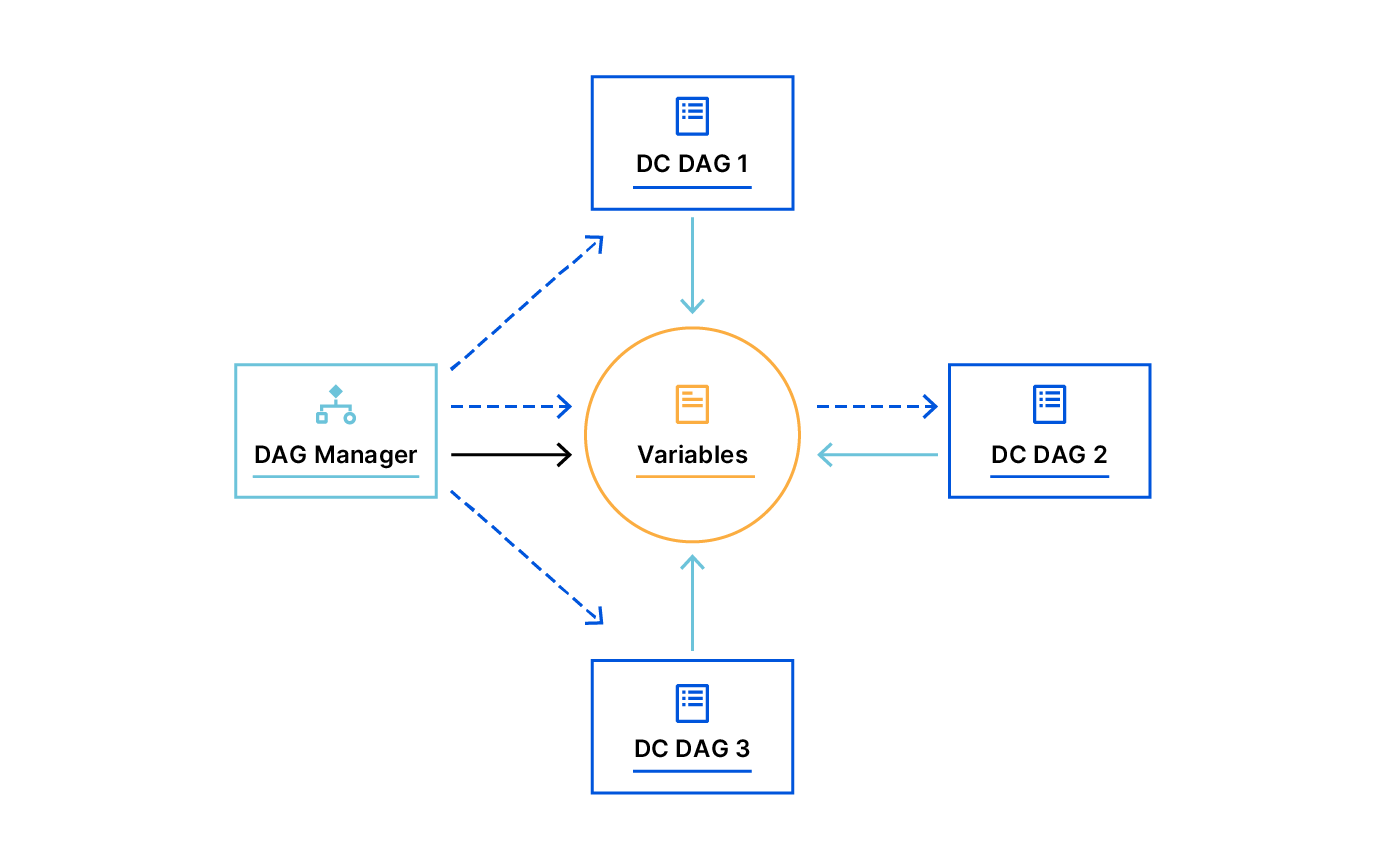
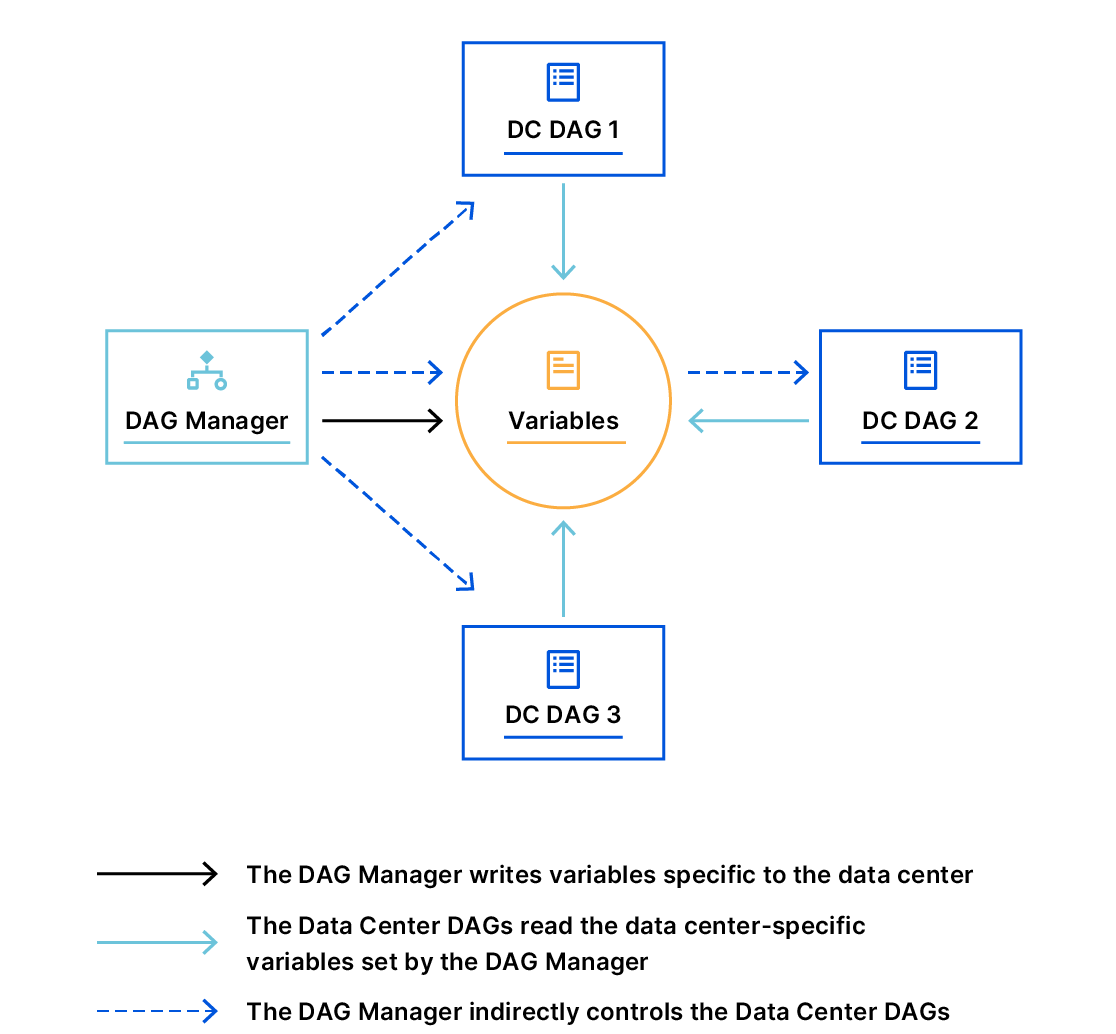
In order for PraaS to be able to accept human inputs, we’ve written a separate DAG we call our DAG Manager. Whenever we need to submit input back to a running expansion DAG, we simply trigger the DAG Manager and pass in our input as a JSON configuration, which will then be processed accordingly and submit the input back to the expansion DAG.
Managing Dependencies Between Tasks
Replacing SOP steps with DAG tasks was only the first part of our journey towards greater automation. We also had to define the dependencies between these tasks and construct the workflow accordingly.
Here’s an example of what this looks like in code:
With the bit shift operator, chaining multiple dependencies becomes concise.
By default, a downstream task will only run if its upstream has succeeded. For a more complex dependency setup, we set a trigger_rule which defines the rule by which the generated task gets triggered.
All operators have a trigger_rule argument. The Airflow scheduler decides whether to run the task or not depending on what rule was specified in the task. An example rule that we use a lot in PraaS is “one_success” — it fires as soon as at least one parent succeeds, and it does not wait for all parents to be done.
Solving Complex Workflows with Branching and Multi-DAGs
Having complex workflows means that we need a workflow to branch, or only go down a certain path, based on an arbitrary condition, which is typically related to something that happened in an upstream task. Branching is used to perform conditional logic, that is, execute a set of tasks based on a condition. We use BranchPythonOperator to achieve this.
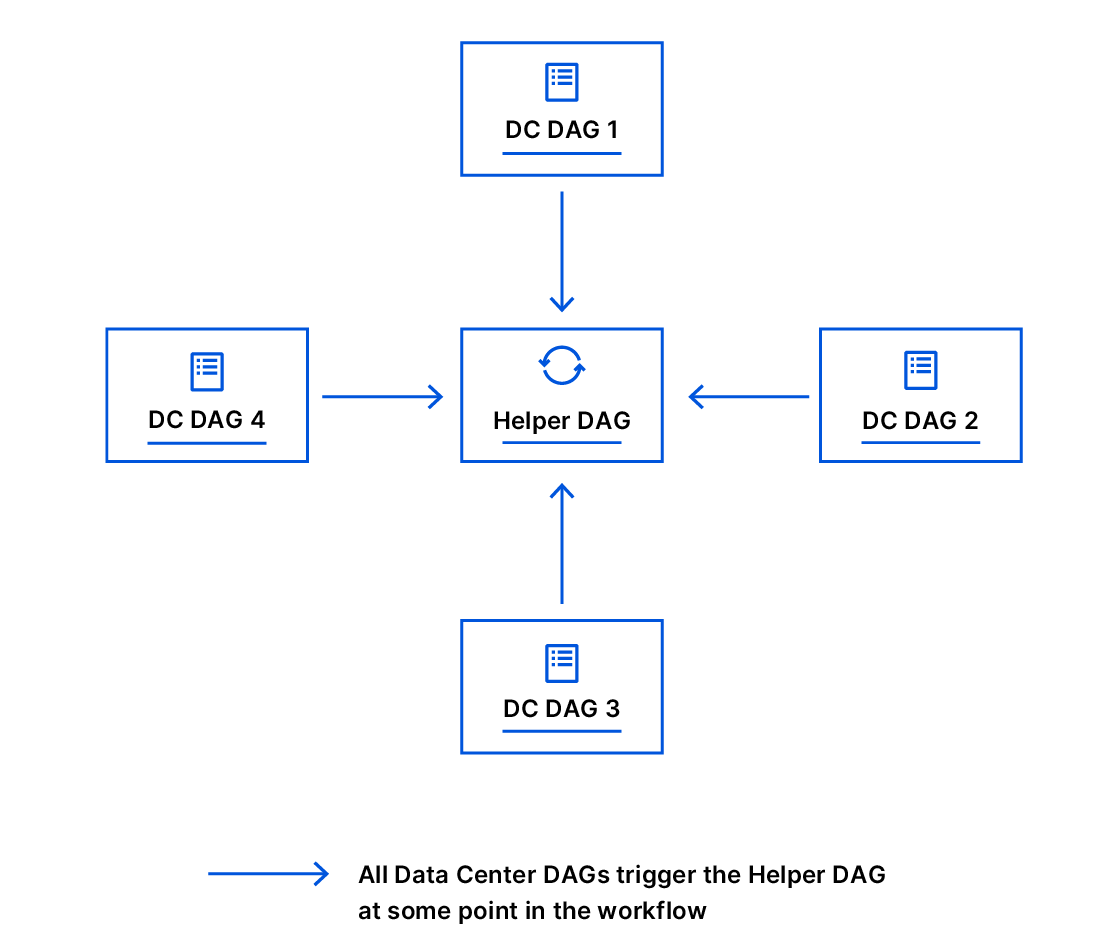
At some point in the workflow, our data center expansion DAGs trigger various external DAGs to accomplish complex tasks. This is why we have written our DAGs to be fully reusable. We did not try to incorporate all the logic into a single DAG; instead, we created other separable DAGs that are fully reusable and can be triggered on-demand manually by hand or programmatically — our DAG Manager and the “helper” DAG is an example of this.
The Helper DAG comprises logic that allows us to mimic a “for loop” by having the DAG respawn itself if needed, technically doing cycles. If you recall, a DAG is acyclic, but we have some tasks in our workflow that require us to do complex loops and are solved by using a helper DAG.
We designed reusable DAGs early on, which allowed us to build complex automation workflows from separable DAGs, each of which handles distinct and well-defined tasks. Each data center DAG could easily reuse other DAGs by triggering them programmatically.
Having separate DAGs that run independently, that are triggered by other DAGs, and that keep inter-dependencies between them, is a pattern we use a lot. It has allowed us to execute very complex workflows.
Creating DAGs that Scale and Executing Tasks at Scale
Data center expansions are done in two phases:
Phase 1 – this is the phase in which servers are powered on. It boots our custom Linux kernel, and begins the provisioning process.
Phase 2 – this is the phase in which newly provisioned servers are enabled in the cluster to receive production traffic.
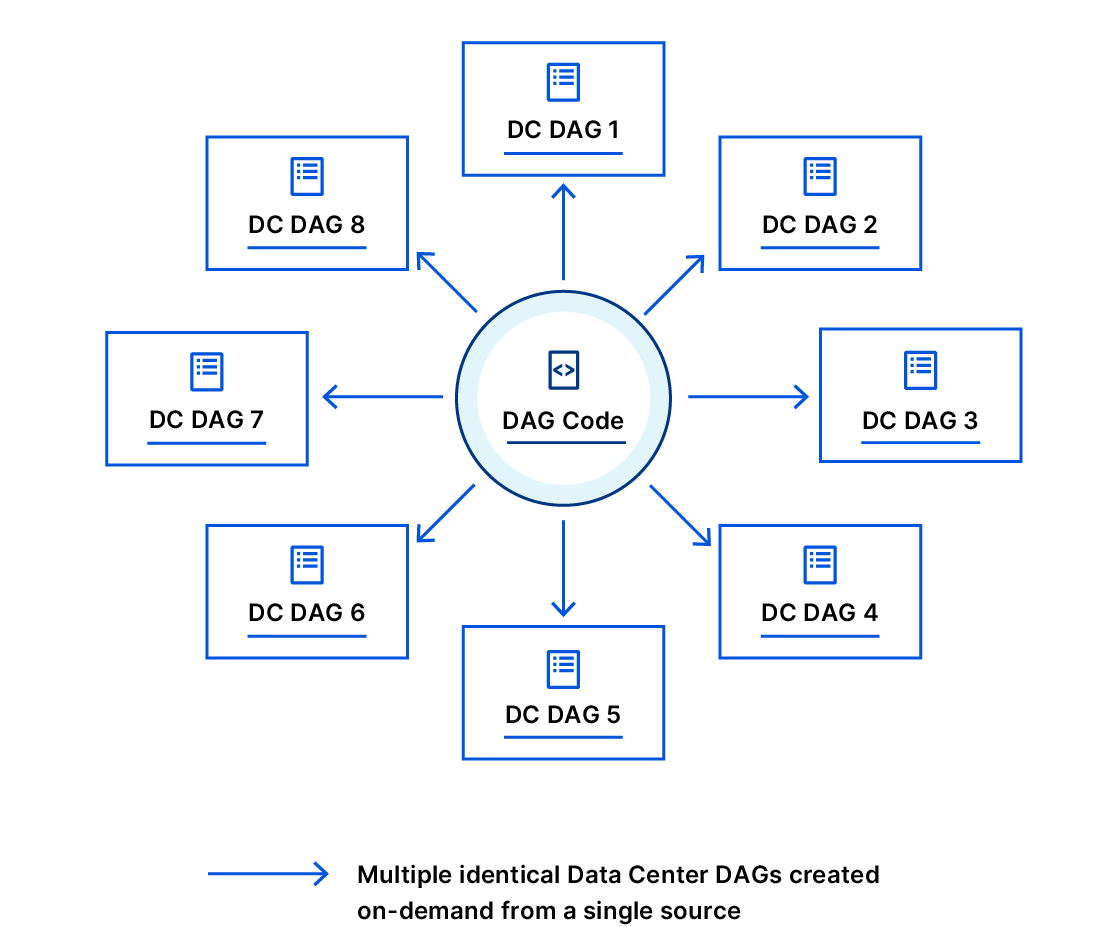
To reflect these phases in the automation workflow, we also wrote two separate DAGs, one for each phase. However, we have over 200 data centers, so if we were to write a pair of DAGs for each, we would end up writing and maintaining 400 files!
A viable option could be to parameterize our DAGs. At first glance, this approach sounds reasonable. However, it poses one major challenge: tracking the progress of DAG runs will be too difficult and confusing for the human operator using PraaS.
Following the software design principle called DRY (Don’t Repeat Yourself), and inspired by the Factory Method design pattern in programming, we’ve instead written both phase 1 and phase 2 DAGs in a way that allow them to dynamically create multiple different DAGs with exactly the same tasks, and to fully reuse the exact same code. As a result, we only maintain one code base, and as we add new data centers, we are also able to generate a DAG for each new data center instantly, without writing a single line of code.
And Airflow even made it easy to put a simple customized web UI on top of the process, which made it simple to use by more employees who didn’t have to understand all the details.
The death of SOPs?
We would like to think that all of this automation removes the need for our original SOP document. But this is not really the case. Automation can fail, the components in it can fail, and a particular task in the DAG may fail. When this happens, our SOPs will be used again to prevent provisioning and expansion activities from stopping completely.
Introducing automation paved the way for what we call an SOP-as-Code practice. We made sure that every task in the DAG had an equivalent manual step in the SOP that SREs can execute by hand, should the need arise, and that every change in the SOP has a corresponding pull request (PR) in the code.
What’s next for PraaS
Onboarding of the other provisioning activities into PraaS, such as decommissioning, is already ongoing.
For expansions, our ultimate goal is a fully autonomous system that monitors whether new servers have been racked in our edge data centers — and automatically triggers expansions — with no human intervention.
Our fleet of over 200 locations comprises various generations of servers and routers. And with the ever changing landscape of services and computing demands, it’s imperative that we manage power in our data centers right. This blog is a brief Electrical Engineering 101 session going over specifically how power distribution units (PDU) work, along with some good practices on how we use them. It appears to me that we could all use a bit more knowledge on this topic, and more love and appreciation of something that’s critical but usually taken for granted, like hot showers and opposable thumbs.
A PDU is a device used in data centers to distribute power to multiple rack-mounted machines. It’s an industrial grade power strip typically designed to power an average consumption of about seven US households. Advanced models have monitoring features and can be accessed via SSH or webGUI to turn on and off power outlets. How we choose a PDU depends on what country the data center is and what it provides in terms of voltage, phase, and plug type.
For each of our racks, all of our dual power-supply (PSU) servers are cabled to one of the two vertically mounted PDUs. As shown in the picture above, one PDU feeds a server’s PSU via a red cable, and the other PDU feeds that server’s other PSU via a blue cable. This is to ensure we have power redundancy maximizing our service uptime; in case one of the PDUs or server PSUs fail, the redundant power feed will be available keeping the server alive.
Faraday’s Law and Ohm’s Law
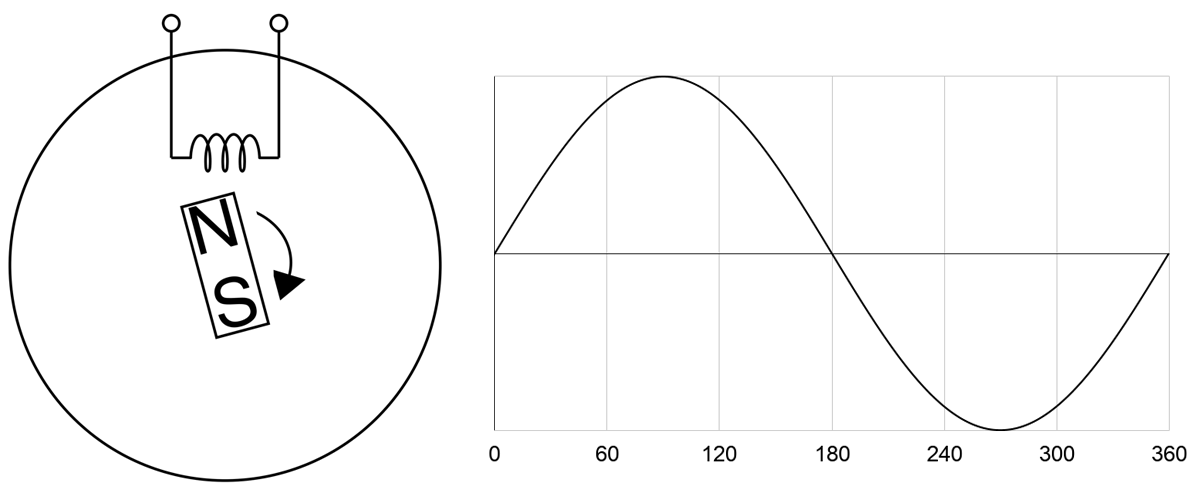
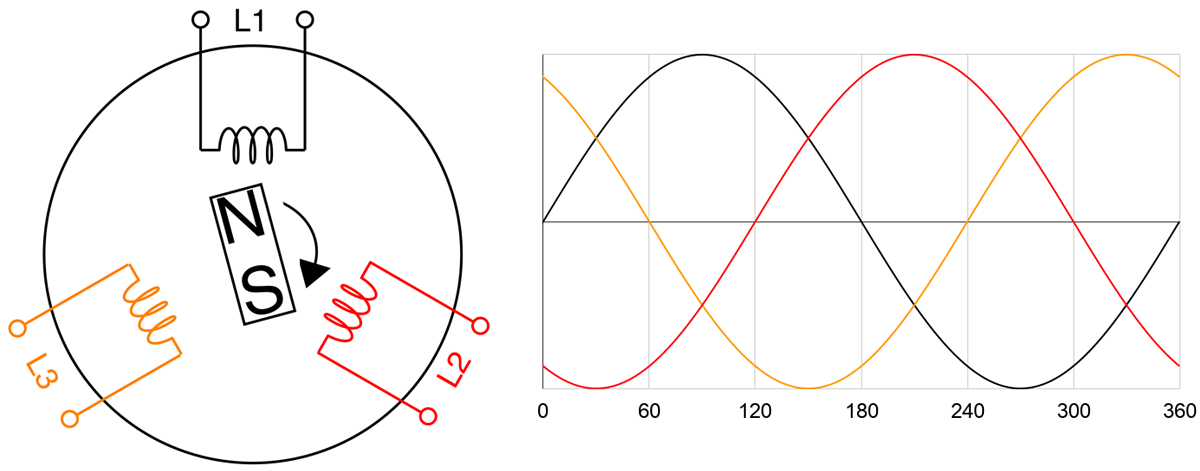
Like most high-voltage applications, PDUs and servers are designed to use AC power. Meaning voltage and current aren’t constant — they’re sine waves with magnitudes that can alternate between positive and negative at a certain frequency. For example, a voltage feed of 100V is not constantly at 100V, but it bounces between 100V and -100V like a sine wave. One complete sine wave cycle is one phase of 360 degrees, and running at 50Hz means there are 50 cycles per second.
The sine wave can be explained by Faraday’s Law and by looking at how an AC power generator works. Faraday’s Law tells us that a current is induced to flow due to a changing magnetic field. Below illustrates a simple generator with a permanent magnet rotating at constant speed and a coil coming in contact with the magnet’s magnetic field. Magnetic force is strongest at the North and South ends of the magnet. So as it rotates on itself near the coil, current flow fluctuates in the coil. One complete rotation of the magnet represents one phase. As the North end approaches the coil, current increases from zero. Once the North end leaves, current decreases to zero. The South end in turn approaches, now the current “increases” in the opposite direction. And finishing the phase, the South end leaves returning the current back to zero. Current alternates its direction at every half cycle, hence the naming of Alternating Current.
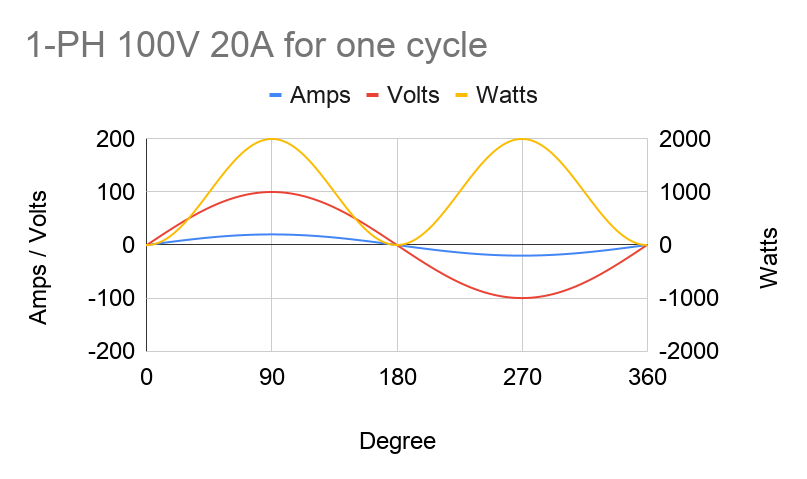
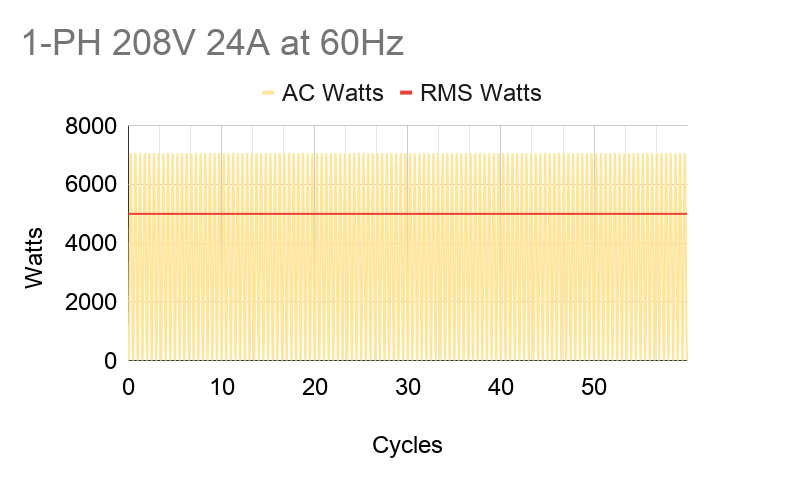
Current and voltage in AC power fluctuate in-phase, or “in tandem”, with each other. So by Ohm’s Law of Power = Voltage x Current, power will always be positive. Notice on the graph below that AC power (Watts) has two peaks per cycle. But for practical purposes, we’d like to use a constant power value. We do that by interpreting AC power into “DC” power using root-mean-square (RMS) averaging, which takes the max value and divides it by √2. For example, in the US, our conditions are 208V 24A at 60Hz. When we look at spec sheets, all of these values can be assumed as RMS’d into their constant DC equivalent values. When we say we’re fully utilizing a PDU’s max capacity of 5kW, it actually means that the power consumption of our machines bounces between 0 and 7.1kW (5kW x √2).
It’s also critical to figure out the sum of power our servers will need in a rack so that it falls under the PDU’s design max power capacity. For our US example, a PDU is typically 5kW (208 volts x 24 amps); therefore, we’re budgeting 5kW and fit as many machines as we can under that. If we need more machines and the total sum power goes above 5kW, we’d need to provision another power source. That would lead to possibly another set of PDUs and racks that we may not fully use depending on demand; e.g. more underutilized costs. All we can do is abide by P = V x I.
However there is a way we can increase the max power capacity economically — 3-phase PDU. Compared to single phase, its max capacity is √3 or 1.7 times higher. A 3-phase PDU of the same US specs above has a capacity of 8.6kW (5kW x √3), allowing us to power more machines under the same source. Using a 3-phase setup might mean it has thicker cables and bigger plug; but despite being more expensive than a 1-phase, its value is higher compared to two 1-phase rack setups for these reasons:
It’s more cost-effective, because there are fewer hardware resources to buy
Say the computing demand adds up to 215kW of hardware, we would need 25 3-phase racks compared to 43 1-phase racks.
Each rack needs two PDUs for power redundancy. Using the example above, we would need 50 3-phase PDUs compared to 86 1-phase PDUs to power 215kW worth of hardware.
That also means a smaller rack footprint and fewer power sources provided and charged by the data center, saving us up to √3 or 1.7 times in opex.
It’s more resilient, because there are more circuit breakers in a 3-phase PDU — one more than in a 1-phase. For example, a 48-outlet PDU that is 1-phase would be split into two circuits of 24 outlets. While a 3-phase one would be split into 3 circuits of 16 outlets. If a breaker tripped, we’d lose 16 outlets using a 3-phase PDU instead of 24.
The PDU shown above is a 3-phase model of 48 outlets. We can see three pairs of circuit breakers for the three branches that are intertwined with each other — white, grey, and black. Industry demands today pressure engineers to maximize compute performance and minimize physical footprint, making the 3-phase PDU a widely-used part of operating a data center.
What is 3-phase?
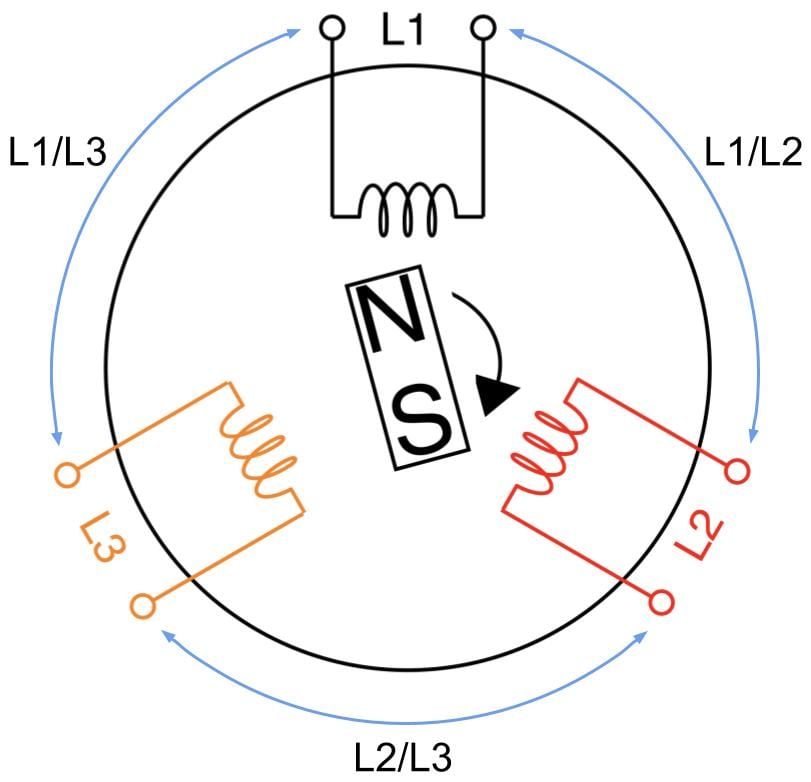
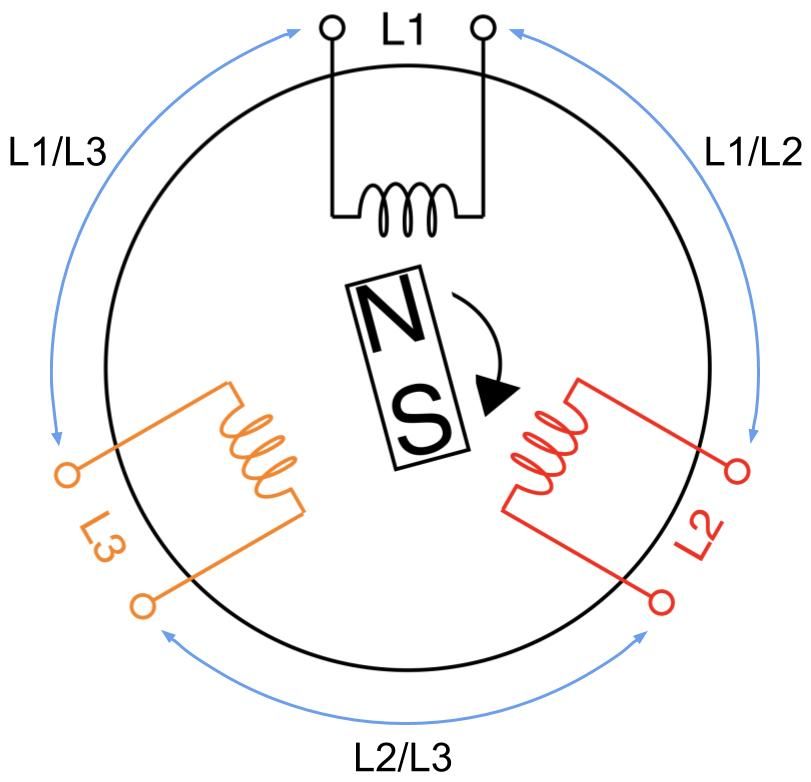
A 3-phase AC generator has three coils instead of one where the coils are 120 degrees apart inside the cylindrical core, as shown in the figure below. Just like the 1-phase generator, current flow is induced by the rotation of the magnet thus creating power from each coil sequentially at every one-third of the magnet’s rotation cycle. In other words, we’re generating three 1-phase power offset by 120 degrees.
A 3-phase feed is set up by joining any of its three coils into line pairs. L1, L2, and L3 coils are live wires with each on their own phase carrying their own phase voltage and phase current. Two phases joining together form one line carrying a common line voltage and line current. L1 and L2 phase voltages create the L1/L2 line voltage. L2 and L3 phase voltages create the L2/L3 line voltage. L1 and L3 phase voltages create the L1/L3 line voltage.
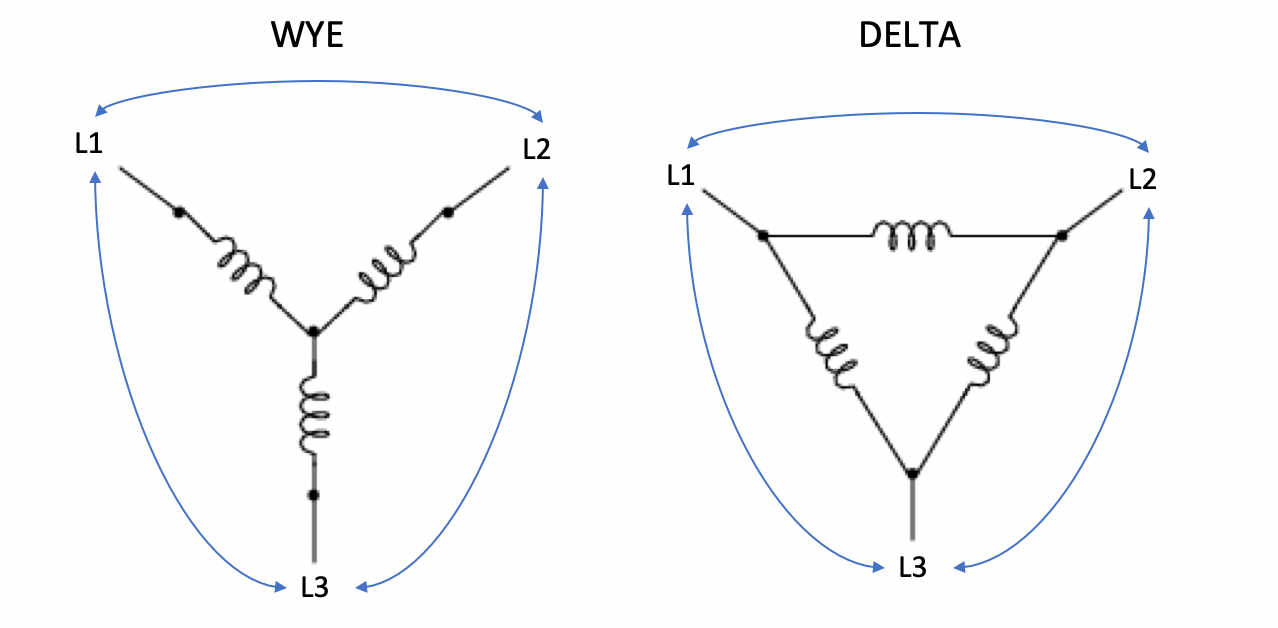
Let’s take a moment to clarify the terminology. Some other sources may refer to line voltage (or current) as line-to-line or phase-to-phase voltage (or current). It can get confusing, because line voltage is the same as phase voltage in 1-phase circuits, as there’s only one phase. Also, the magnitude of the line voltage is equal to the magnitude of the phase voltage in 3-phase Delta circuits, while the magnitude of the line current is equal to the magnitude of the phase current in 3-phase Wye circuits.
Conversely, the line current equals to phase current times √3 in Delta circuits. In Wye circuits, the line voltage equals to phase voltage times √3.
In Delta circuits:
Vline = Vphase
Iline = √3 x Iphase
In Wye circuits:
Vline = √3 x Vphase
Iline = Iphase
Delta and Wye circuits are the two methods that three wires can join together. This happens both at the power source with three coils and at the PDU end with three branches of outlets. Note that the generator and the PDU don’t need to match each other’s circuit types.
On PDUs, these phases join when we plug servers into the outlets. So we conceptually use the wirings of coils above and replace them with resistors to represent servers. Below is a simplified wiring diagram of a 3-phase Delta PDU showing the three line pairs as three modular branches. Each branch carries two phase currents and its own one common voltage drop.
And this one below is of a 3-phase Wye PDU. Note that Wye circuits have an additional line known as the neutral line where all three phases meet at one point. Here each branch carries one phase and a neutral line, therefore one common current. The neutral line isn’t considered as one of the phases.
Thanks to a neutral line, a Wye PDU can offer a second voltage source that is √3 times lower for smaller devices, like laptops or monitors. Common voltages for Wye PDUs are 230V/400V or 120V/208V, particularly in North America.
Where does the √3 come from?
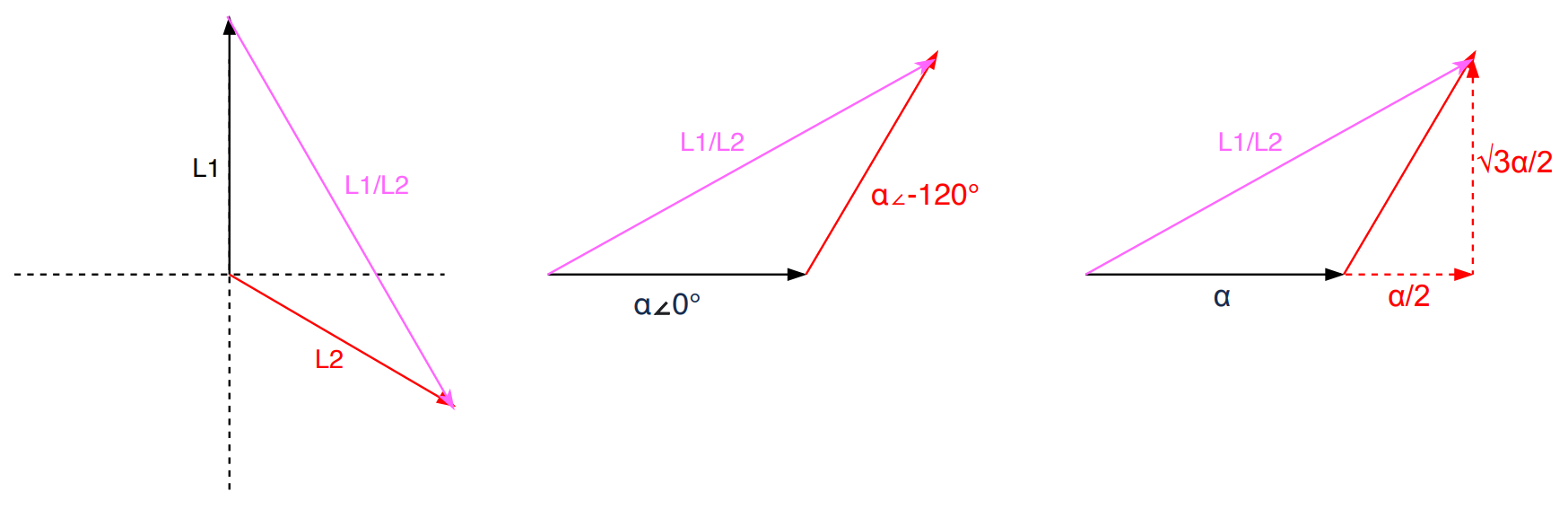
Why are we multiplying by √3? As the name implies, we are adding phasors. Phasors are complex numbers representing sine wave functions. Adding phasors is like adding vectors. Say your GPS tells you to walk 1 mile East (vector a), then walk a 1 mile North (vector b). You walked 2 miles, but you only moved by 1.4 miles NE from the original location (vector a+b). That 1.4 miles of “work” is what we want.
Let’s take in our application L1 and L2 in a Delta circuit. we add phases L1 and L2, we get a L1/L2 line. We assume the 2 coils are identical. Let’s say α represents the voltage magnitude for each phase. The 2 phases are 120 degrees offset as designed in the 3-phase power generator:
Since voltage is a scalar, we’re only interested in the “work”:
|L1/L2| = √3α
Given that α also applies for L3. This means for any of the three line pairs, we multiply the phase voltage by √3 to calculate the line voltage.
Vline = √3 x Vphase
Now with the three line powers being equal, we can add them all to get the overall effective power. The derivation below works for both Delta and Wye circuits.
Poverall = 3 x Pline
Poverall = 3 x (Vline x Iline)
Poverall = (3/√3) x (Vphase x Iphase)
Poverall = √3 x Vphase x Iphase
Using the US example, Vphase is 208V and Iphase is 24A. This leads to the overall 3-phase power to be 8646W (√3 x 208V x 24A) or 8.6kW. There lies the biggest advantage for using 3-phase systems. Adding 2 sets of coils and wires (ignoring the neutral wire), we’ve turned a generator that can produce √3 or 1.7 times more power!
Dealing with 3-phase
The derivation in the section above assumes that the magnitude at all three phases is equal, but we know in practice that’s not always the case. In fact, it’s barely ever. We rarely have servers and switches evenly distributed across all three branches on a PDU. Each machine may have different loads and different specs, so power could be wildly different, potentially causing a dramatic phase imbalance. Having a heavily imbalanced setup could potentially hinder the PDU’s available capacity.
A perfectly balanced and fully utilized PDU at 8.6kW means that each of its three branches has 2.88kW of power consumed by machines. Laid out simply, it’s spread 2.88 + 2.88 + 2.88. This is the best case scenario. If we were to take 1kW worth of machines out of one branch, spreading power to 2.88 + 1.88 + 2.88. Imbalance is introduced, the PDU is underutilized, but we’re fine. However, if we were to put back that 1kW into another branch — like 3.88 + 1.88 + 2.88 — the PDU is over capacity, even though the sum is still 8.6kW. In fact, it would be over capacity even if you just added 500W instead of 1kW on the wrong branch, thus reaching 3.18 + 1.88 + 2.88 (8.1kW).
That’s because a 8.6kW PDU is spec’d to have a maximum of 24A for each phase current. Overloading one of the branches can force phase currents to go over 24A. Theoretically, we can reach the PDU’s capacity by loading one branch until its current reaches 24A and leave the other two branches unused. That’ll render it into a 1-phase PDU, losing the benefit of the √3 multiplier. In reality, the branch would have fuses rated less than 24A (usually 20A) to ensure we won’t reach that high and cause overcurrent issues. Therefore the same 8.6kW PDU would have one of its branches tripped at 4.2kW (208V x 20A).
Loading up one branch is the easiest way to overload the PDU. Being heavily imbalanced significantly lowers PDU capacity and increases risk of failure. To help minimize that, we must:
Ensure that total power consumption of all machines is under the PDU’s max power capacity
Try to be as phase-balanced as possible by spreading cabling evenly across the three branches
Ensure that the sum of phase currents from powered machines at each branch is under the fuse rating at the circuit breaker.
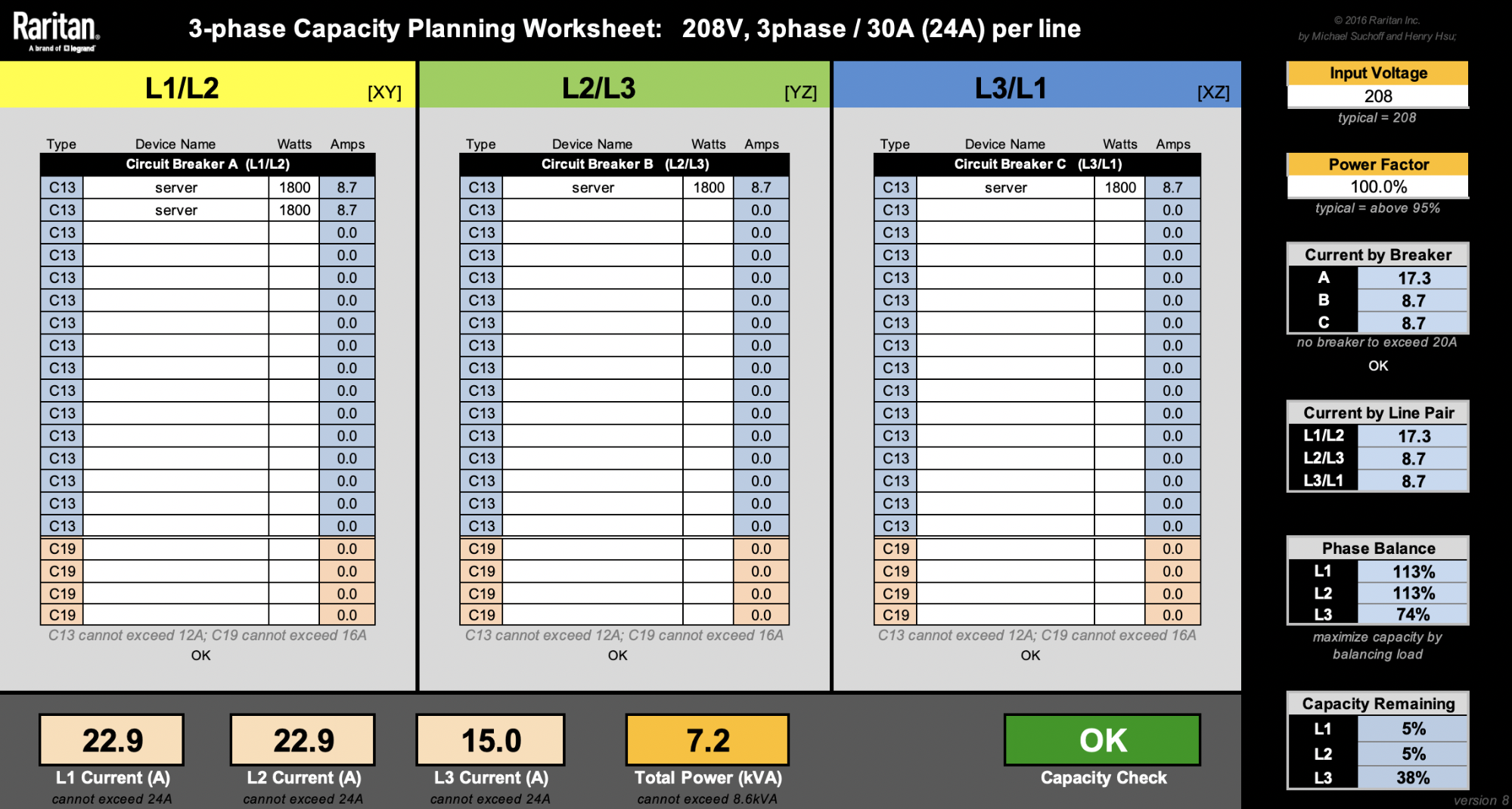
This spreadsheet from Raritan is very useful when designing racks.
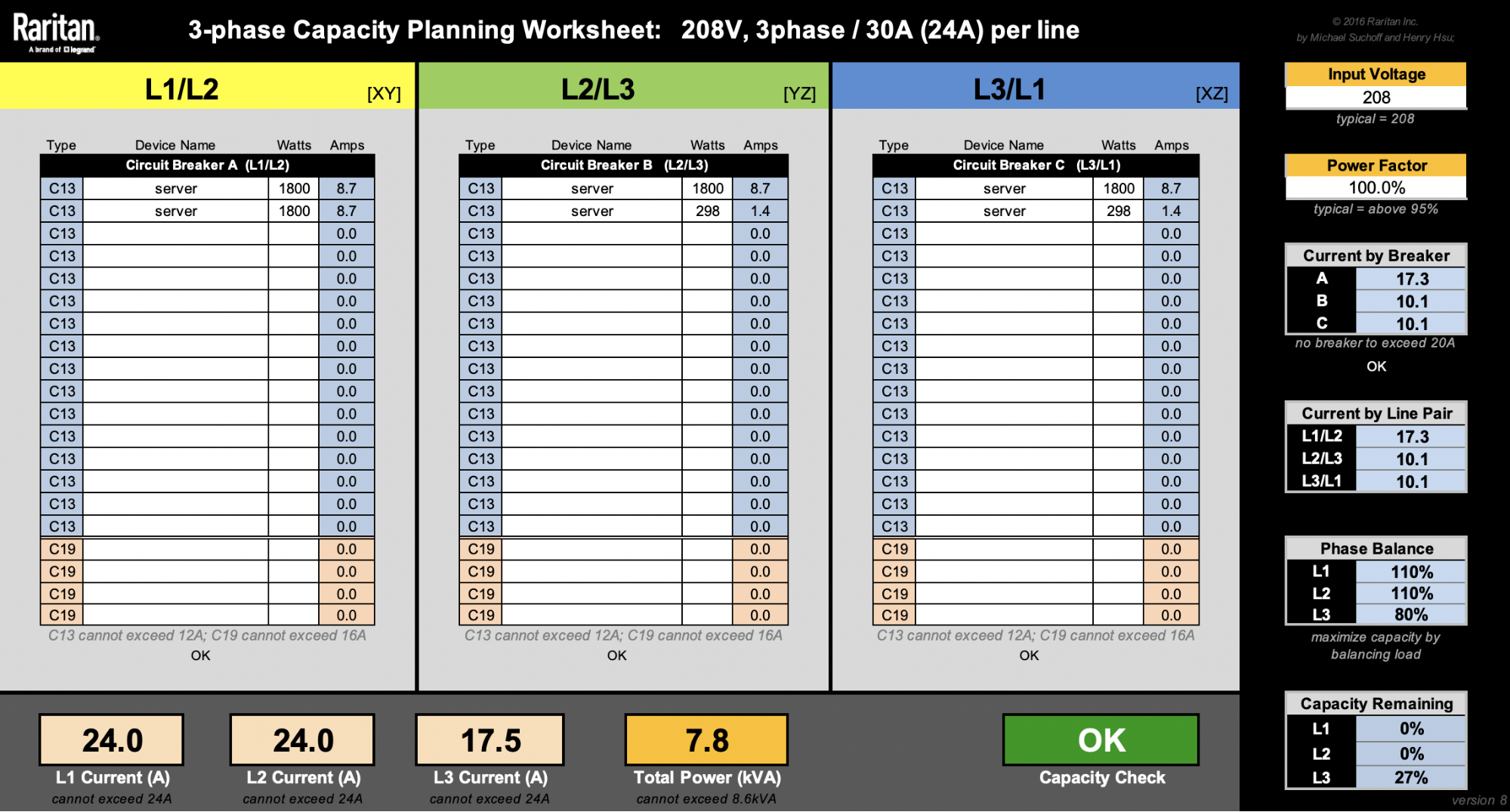
For the sake of simplicity, let’s ignore other machines like switches. Our latest 2U4N servers are rated at 1800W. That means we can only fit a maximum of four of these 2U4N chassis (8600W / 1800W = 4.7 chassis). Rounding them up to 5 would reach a total rack level power consumption of 9kW, so that’s a no-no.
Splitting 4 chassis into 3 branches evenly is impossible, and will force us to have one of the branches to have 2 chassis. That would lead to a non-ideal phase balancing:
Keeping phase currents under 24A, there’s only 1.1A (24A – 22.9A) to add on L1 or L2 before the PDU gets overloaded. Say we want to add as many machines as we can under the PDU’s power capacity. One solution is we can add up to 242W on the L1/L2 branch until both L1 and L2 currents reach their 24A limit.
Alternatively, we can add up to 298W on the L2/L3 branch until L2 current reaches 24A. Note we can also add another 298W on the L3/L1 branch until L1 current reaches 24A.
In the examples above, we can see that various solutions are possible. Adding two 298W machines each at L2/L3 and L3/L1 is the most phase balanced solution, given the parameters. Nonetheless, PDU capacity isn’t optimized at 7.8kW.
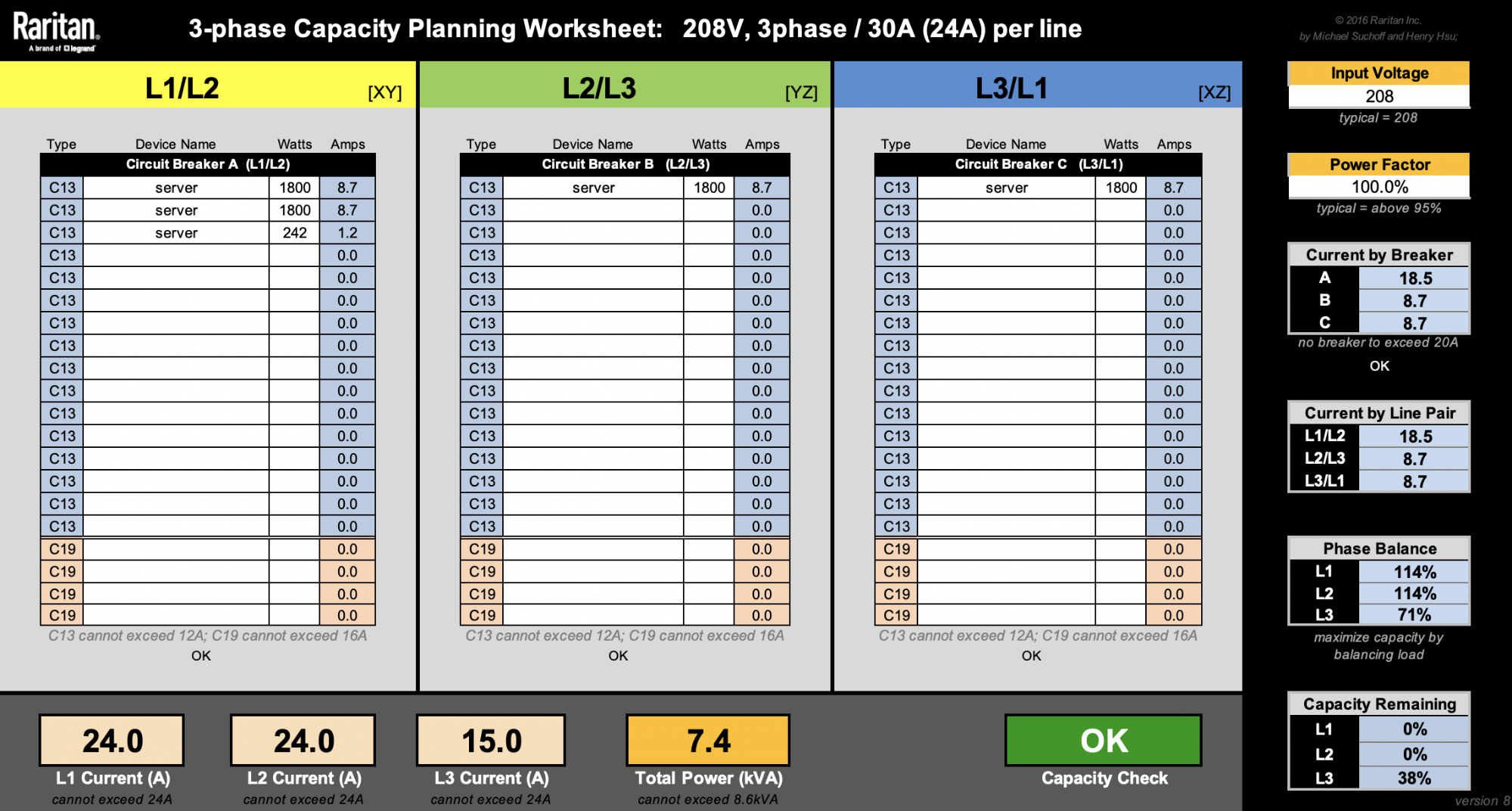
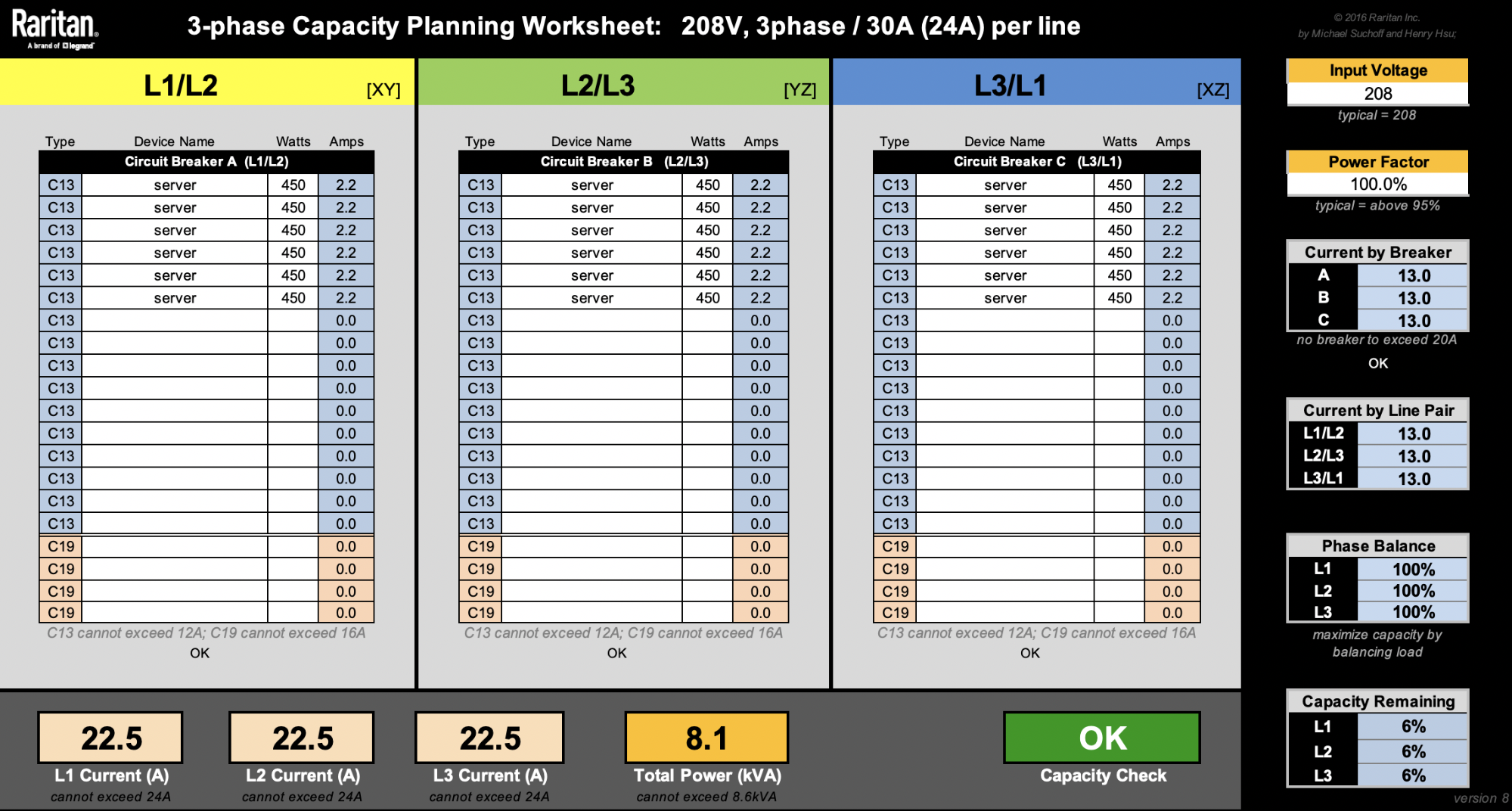
Dealing with a 1800W server is not ideal, because whichever branch we choose to power one would significantly swing the phase balance unfavorably. Thankfully, our Gen X servers take up less space and are more power efficient. Smaller footprint allows us to have more flexibility and fine-grained control over our racks in many of our diverse data centers. Assuming each 1U server is 450W, as if we physically split the 1800W 2U4N into fours each with their own power supplies, we’re now able to fit 18 nodes. That’s 2 more nodes than the four 2U4N setup:
Adding two more servers here means we’ve increased our value by 12.5%. While there are more factors not considered here to calculate the Total Cost of Ownership, this is still a great way to show we can be smarter with asset costs.
Cloudflare provides the back-end services so that our customers can enjoy the performance, reliability, security, and global scale of our edge network. Meanwhile, we manage all of our hardware in over 100 countries with various power standards and compliances, and ensure that our physical infrastructure is as reliable as it can be.
As a security company, we pride ourselves on finding innovative ways to protect our platform to, in turn, protect the data of our customers. Part of this approach is implementing progressive methods in protecting our hardware at scale. While we have blogged about how we address security threats from application to memory, the attacks on hardware, as well as firmware, have increased substantially. The data cataloged in the National Vulnerability Database (NVD) has shown the frequency of hardware and firmware-level vulnerabilities rising year after year.
Technologies like secure boot, common in desktops and laptops, have been ported over to the server industry as a method to combat firmware-level attacks and protect a device’s boot integrity. These technologies require that you create a trust ‘anchor’, an authoritative entity for which trust is assumed and not derived. A common trust anchor is the system Basic Input/Output System (BIOS) or the Unified Extensible Firmware Interface (UEFI) firmware.
While this ensures that the device boots only signed firmware and operating system bootloaders, does it protect the entire boot process? What protects the BIOS/UEFI firmware from attacks?
The Boot Process
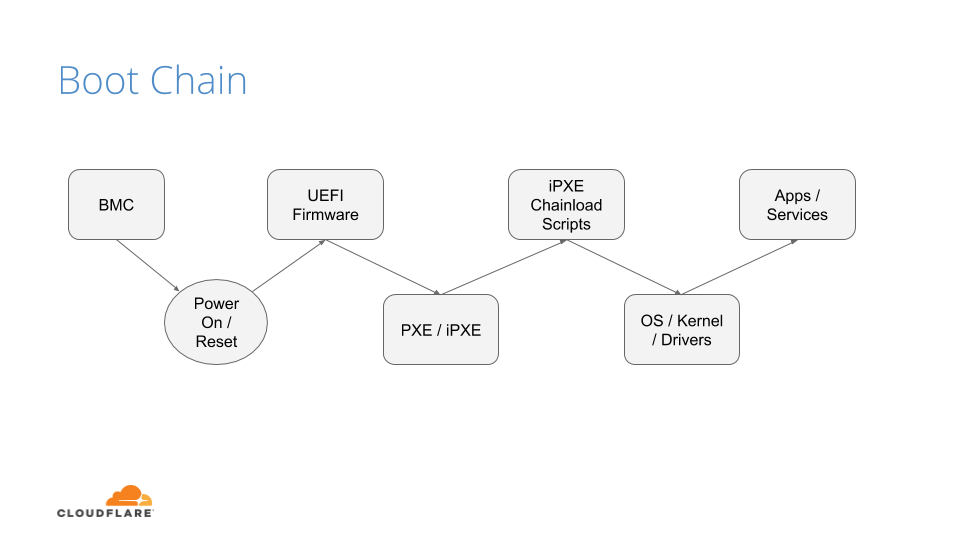
Before we discuss how we secure our boot process, we will first go over how we boot our machines.
The above image shows the following sequence of events:
After powering on the system (through a baseboard management controller (BMC) or physically pushing a button on the system), the system unconditionally executes the UEFI firmware residing on a flash chip on the motherboard.
UEFI performs some hardware and peripheral initialization and executes the Preboot Execution Environment (PXE) code, which is a small program that boots an image over the network and usually resides on a flash chip on the network card.
PXE sets up the network card, and downloads and executes a small program bootloader through an open source boot firmware called iPXE.
iPXE loads a script that automates a sequence of commands for the bootloader to know how to boot a specific operating system (sometimes several of them). In our case, it loads our Linux kernel, initrd (this contains device drivers which are not directly compiled into the kernel), and a standard Linux root filesystem. After loading these components, the bootloader executes and hands off the control to the kernel.
Finally, the Linux kernel loads any additional drivers it needs and starts applications and services.
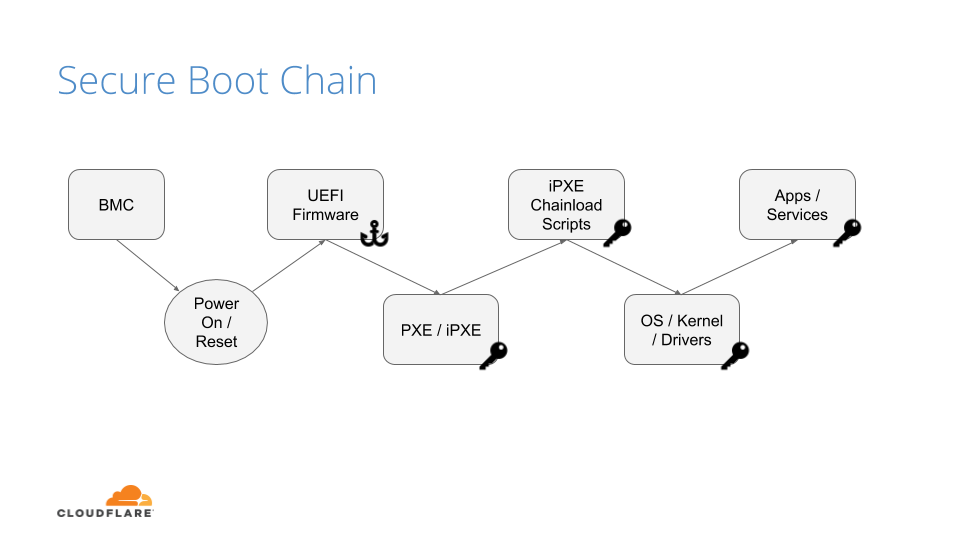
UEFI Secure Boot
Our UEFI secure boot process is fairly straightforward, albeit customized for our environments. After loading the UEFI firmware from the bootloader, an initialization script defines the following variables:
Platform Key (PK): It serves as the cryptographic root of trust for secure boot, giving capabilities to manipulate and/or validate the other components of the secure boot framework.
Trusted Database (DB): Contains a signed (by platform key) list of hashes of all PCI option ROMs, as well as a public key, which is used to verify the signature of the bootloader and the kernel on boot.
These variables are respectively the master platform public key, which is used to sign all other resources, and an allow list database, containing other certificates, binary file hashes, etc. In default secure boot scenarios, Microsoft keys are used by default. At Cloudflare we use our own, which makes us the root of trust for UEFI:
But, by setting our trust anchor in the UEFI firmware, what attack vectors still exist?
UEFI Attacks
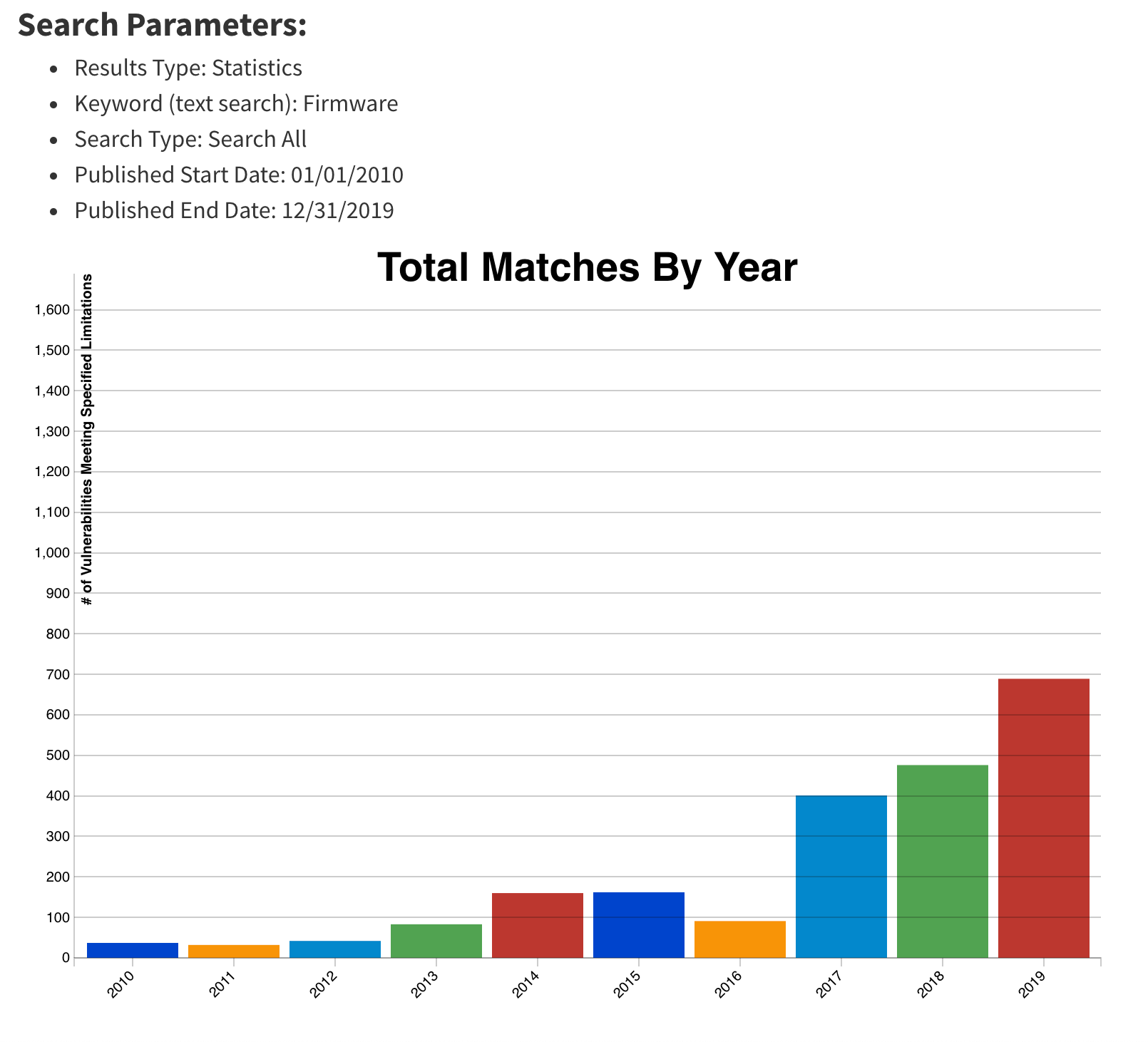
As stated previously, firmware and hardware attacks are on the rise. It is clear from the figure below that firmware-related vulnerabilities have increased significantly over the last 10 years, especially since 2017, when the hacker community started attacking the firmware on different platforms:
This upward trend, coupled with recent malware findings in UEFI, shows that trusting firmware is becoming increasingly problematic.
By tainting the UEFI firmware image, you poison the entire boot trust chain. The ability to trust firmware integrity is important beyond secure boot. For example, if you can’t trust the firmware not to be compromised, you can’t trust things like trusted platform module (TPM) measurements to be accurate, because the firmware is itself responsible for doing these measurements (e.g a TPM is not an on-path security mechanism, but instead it requires firmware to interact and cooperate with). Firmware may be crafted to extend measurements that are accepted by a remote attestor, but that don’t represent what’s being locally loaded. This could cause firmware to have a questionable measured boot and remote attestation procedure.
If we can’t trust firmware, then hardware becomes our last line of defense.
Hardware Root of Trust
Early this year, we made a series of blog posts on why we chose AMD EPYC processors for our Gen X servers. With security in mind, we started turning on features that were available to us and set forth the plan of using AMD silicon as a Hardware Root of Trust (HRoT).
Platform Secure Boot (PSB) is AMD’s implementation of hardware-rooted boot integrity. Why is it better than UEFI firmware-based root of trust? Because it is intended to assert, by a root of trust anchored in the hardware, the integrity and authenticity of the System ROM image before it can execute. It does so by performing the following actions:
Authenticates the first block of BIOS/UEFI prior to releasing x86 CPUs from reset.
Authenticates the System Read-Only Memory (ROM) contents on each boot, not just during updates.
Moves the UEFI Secure Boot trust chain to immutable hardware.
This is accomplished by the AMD Platform Security Processor (PSP), an ARM Cortex-A5 microcontroller that is an immutable part of the system on chip (SoC). The PSB consists of two components:
On-chip Boot ROM
Embeds a SHA384 hash of an AMD root signing key
Verifies and then loads the off-chip PSP bootloader located in the boot flash
Off-chip Bootloader
Locates the PSP directory table that allows the PSP to find and load various images
Authenticates first block of BIOS/UEFI code
Releases CPUs after successful authentication
The PSP secures the On-chip Boot ROM code, loads the off-chip PSP firmware into PSP static random access memory (SRAM) after authenticating the firmware, and passes control to it.
The Off-chip Bootloader (BL) loads and specifies applications in a specific order (whether or not the system goes into a debug state and then a secure EFI application binary interface to the BL)
The system continues initialization through each bootloader stage.
If each stage passes, then the UEFI image is loaded and the x86 cores are released.
Now that we know the booting steps, let’s build an image.
Build Process
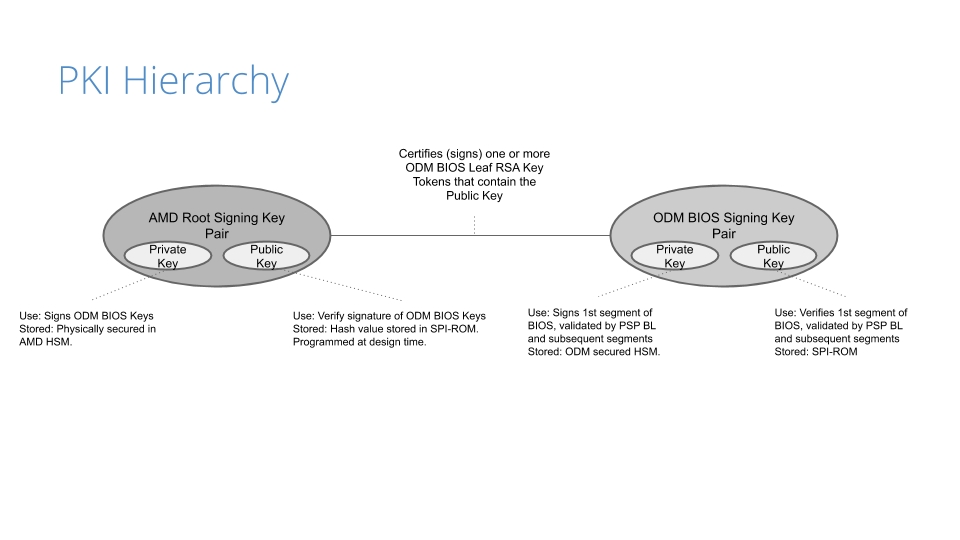
Public Key Infrastructure
Before the image gets built, a public key infrastructure (PKI) is created to generate the key pairs involved for signing and validating signatures:
Our original device manufacturer (ODM), as a trust extension, creates a key pair (public and private) that is used to sign the first segment of the BIOS (private key) and validates that segment on boot (public key).
On AMD’s side, they have a key pair that is used to sign (the AMD root signing private key) and certify the public key created by the ODM. This is validated by AMD’s root signing public key, which is stored as a hash value (RSASSA-PSS: SHA-384 with 4096-bit key is used as the hashing algorithm for both message and mask generation) in SPI-ROM.
Because of the way the PKI mechanisms are built, the system cannot be compromised if only one of the keys is leaked. This is an important piece of the trust hierarchy that is used for image signing.
Certificate Signing Request
Once the PKI infrastructure is established, a BIOS signing key pair is created, together with a certificate signing request (CSR). Creating the CSR uses known common name (CN) fields that many are familiar with:
countryName
stateOrProvinceName
localityName
organizationName
In addition to the fields above, the CSR will contain a serialNumber field, a 32-bit integer value represented in ASCII HEX format that encodes the following values:
PLATFORM_VENDOR_ID: An 8-bit integer value assigned by AMD for each ODM.
PLATFORM_MODEL_ID: A 4-bit integer value assigned to a platform by the ODM.
BIOS_KEY_REVISION_ID: is set by the ODM encoding a 4-bit key revision as unary counter value.
DISABLE_SECURE_DEBUG: Fuse bit that controls whether secure debug unlock feature is disabled permanently.
DISABLE_AMD_BIOS_KEY_USE: Fuse bit that controls if the BIOS, signed by an AMD key, (with vendor ID == 0) is permitted to boot on a CPU with non-zero Vendor ID.
DISABLE_BIOS_KEY_ANTI_ROLLBACK: Fuse bit that controls whether BIOS key anti-rollback feature is enabled.
Remember these values, as we’ll show how we use them in a bit. Any of the DISABLE values are optional, but recommended based on your security posture/comfort level.
AMD, upon processing the CSR, provides the public part of the BIOS signing key signed and certified by the AMD signing root key as a RSA Public Key Token file (.stkn) format.
Putting It All Together
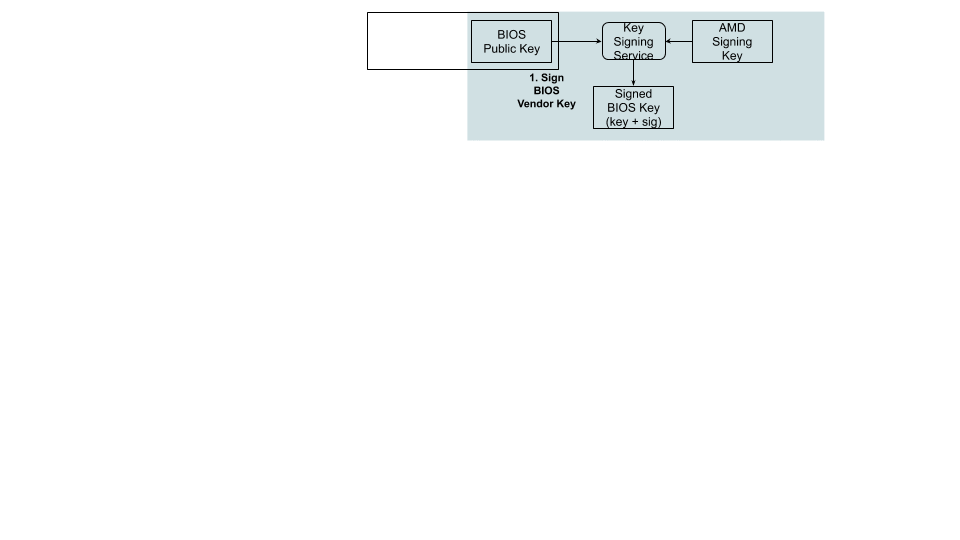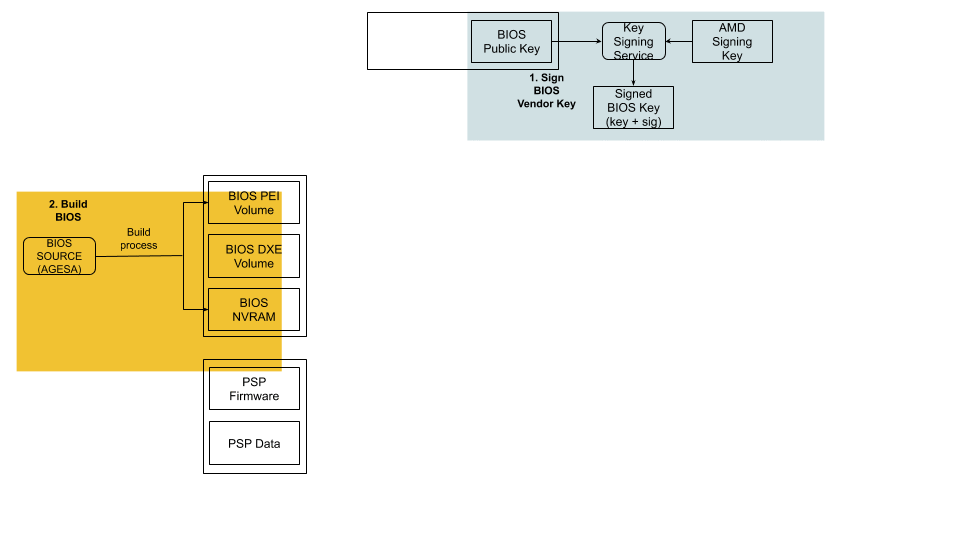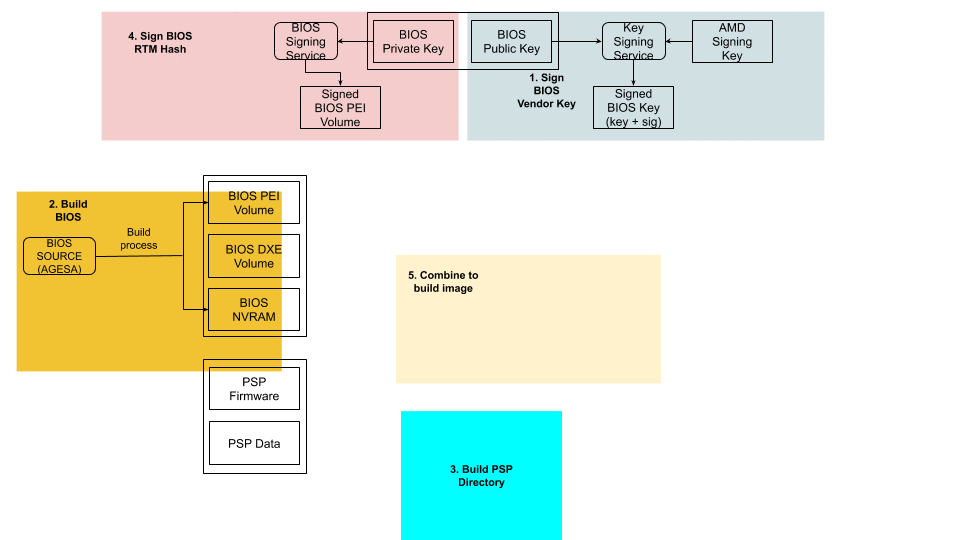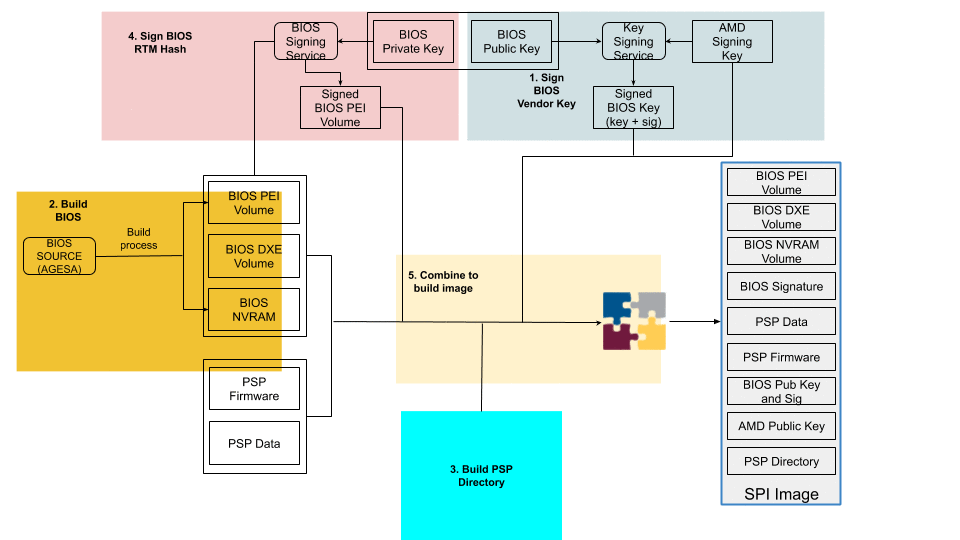
The following is a step-by-step illustration of how signed UEFI firmware is built:
The ODM submits their public key used for signing Cloudflare images to AMD.
AMD signs this key using their RSA private key and passes it back to ODM.
The AMD public key and the signed ODM public key are part of the final BIOS SPI image.
The BIOS source code is compiled and various BIOS components (PEI Volume, Driver eXecution Environment (DXE) volume, NVRAM storage, etc.) are built as usual.
The PSP directory and BIOS directory are built next. PSP directory and BIOS directory table points to the location of various firmware entities.
The ODM builds the signed BIOS Root of Trust Measurement (RTM) signature based on the blob of BIOS PEI volume concatenated with BIOS Directory header, and generates the digital signature of this using the private portion of ODM signing key. The SPI location for signed BIOS RTM code is finally updated with this signature blob.
Finally, the BIOS binaries, PSP directory, BIOS directory and various firmware binaries are combined to build the SPI BIOS image.
Enabling Platform Secure Boot
Platform Secure Boot is enabled at boot time with a PSB-ready firmware image. PSB is configured using a region of one-time programmable (OTP) fuses, specified for the customer. OTP fuses are on-chip non-volatile memory (NVM) that permits data to be written to memory only once. There is NO way to roll the fused CPU back to an unfused one.
Enabling PSB in the field will go through two steps: fusing and validating.
Fusing: Fuse the values assigned in the serialNumber field that was generated in the CSR
Validating: Validate the fused values and the status code registers
If validation is successful, the BIOS RTM signature is validated using the ODM BIOS signing key, PSB-specific registers (MP0_C2P_MSG_37 and MP0_C2P_MSG_38) are updated with the PSB status and fuse values, and the x86 cores are released
If validation fails, the registers above are updated with the PSB error status and fuse values, and the x86 cores stay in a locked state.
Let’s Boot!
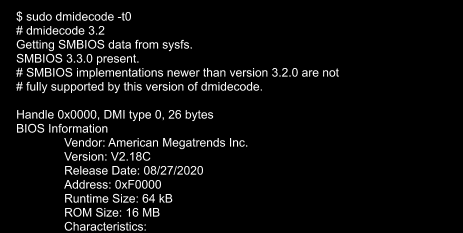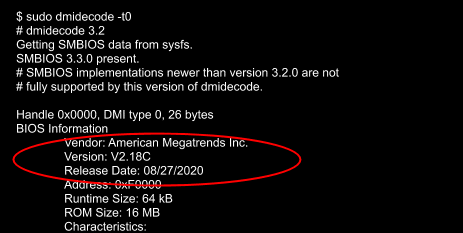
With a signed image in hand, we are ready to enable PSB on a machine. We chose to deploy this on a few machines that had an updated, unsigned AMI UEFI firmware image, in this case version 2.16. We use a couple of different firmware updatetools, so, after a quick script, we ran an update to change the firmware version from 2.16 to 2.18C (the signed image):
. $sudo ./UpdateAll.sh
Bin file name is ****.218C
BEGIN
+---------------------------------------------------------------------------+
| AMI Firmware Update Utility v5.11.03.1778 |
| Copyright (C)2018 American Megatrends Inc. |
| All Rights Reserved. |
+---------------------------------------------------------------------------+
Reading flash ............... done
FFS checksums ......... ok
Check RomLayout ........ ok.
Erasing Boot Block .......... done
Updating Boot Block ......... done
Verifying Boot Block ........ done
Erasing Main Block .......... done
Updating Main Block ......... done
Verifying Main Block ........ done
Erasing NVRAM Block ......... done
Updating NVRAM Block ........ done
Verifying NVRAM Block ....... done
Erasing NCB Block ........... done
Updating NCB Block .......... done
Verifying NCB Block ......... done
Process completed.
After the update completed, we rebooted:
After a successful install, we validated that the image was correct via the sysfs information provided in the dmidecode output:
Testing
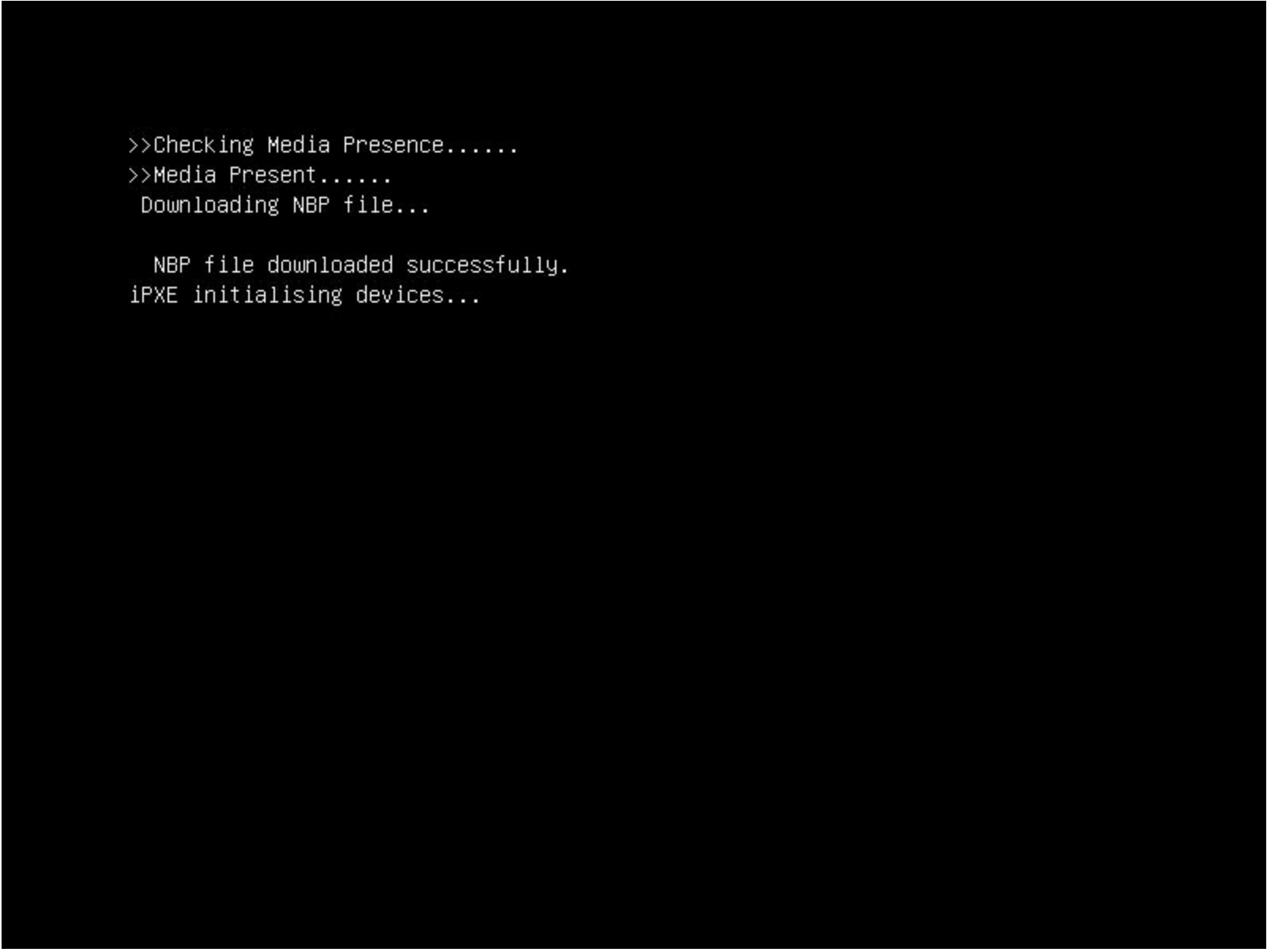
With a signed image installed, we wanted to test that it worked, meaning: what if an unauthorized user installed their own firmware image? We did this by downgrading the image back to an unsigned image, 2.16. In theory, the machine shouldn’t boot as the x86 cores should stay in a locked state. After downgrading, we rebooted and got the following:
This isn’t a powered down machine, but the result of booting with an unsigned image.
Flashing back to a signed image is done by running the same flashing utility through the BMC, so we weren’t bricked. Nonetheless, the results were successful.
Naming Convention
Our standard UEFI firmware images are alphanumeric, making it difficult to distinguish (by name) the difference between a signed and unsigned image (v2.16A vs v2.18C), for example. There isn’t a remote attestation capability (yet) to probe the PSB status registers or to store these values by means of a signature (e.g. TPM quote). As we transitioned to PSB, we wanted to make this easier to determine by adding a specific suffix: -sig that we could query in userspace. This would allow us to query this information via Prometheus. Changing the file name alone wouldn’t do it, so we had to make the following changes to reflect a new naming convention for signed images:
Update filename
Update BIOS version for setup menu
Update post message
Update SMBIOS type 0 (BIOS version string identifier)
Signed images now have a -sig suffix:
~$ sudo dmidecode -t0
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.
# SMBIOS implementations newer than version 3.2.0 are not
# fully supported by this version of dmidecode.
Handle 0x0000, DMI type 0, 26 bytes
BIOS Information
Vendor: American Megatrends Inc.
Version: V2.20-sig
Release Date: 09/29/2020
Address: 0xF0000
Runtime Size: 64 kB
ROM Size: 16 MB
Conclusion
Finding weaknesses in firmware is a challenge that many attackers have taken on. Attacks that physically manipulate the firmware used for performing hardware initialization during the booting process can invalidate many of the common secure boot features that are considered industry standard. By implementing a hardware root of trust that is used for code signing critical boot entities, your hardware becomes a ‘first line of defense’ in ensuring that your server hardware and software integrity can derive trust through cryptographic means.
What’s Next?
While this post discussed our current, AMD-based hardware platform, how will this affect our future hardware generations? One of the benefits of working with diverse vendors like AMD and Ampere (ARM) is that we can ensure they are baking in our desired platform security by default (which we’ll speak about in a future post), making our hardware security outlook that much brighter 😀.
The collective thoughts of the interwebz
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.