In this blog post, we wanted to highlight some ways that Cloudflare and IBM Cloud work together to help drive product innovation and deliver services that address the needs of our mutual customers. On our blog, we often discuss exciting new product developments and how we are solving real-world problems in our effort to make the internet better and many of our customers and partners play an important role.
IBM Cloud and Cloudflare have been working together since 2018 to integrate Cloudflare application security and performance products natively into IBM Cloud. IBM Cloud Internet Services (CIS) has customers across a wide range of industry verticals and geographic regions but they also have several specialist groups building unique service offerings.
The IBM Cloud team specializes in serving clients in highly regulated industries, aiming to ensure their resiliency, performance, security and compliance needs are met. One group that we’ve been working with recently is IBM Cloud for Financial Services. This group extends the capabilities of IBM Cloud to help serve the complex security and compliance needs of banks, financial institutions and fintech companies.
Bot Management
As malicious bot attacks get more sophisticated and manual mitigations become more onerous, a dynamic and adaptive solution is required for enterprises running Internet facing workloads. With Cloudflare Bot Management on IBM Cloud Internet Services, we aim to help IBM clients protect their Internet properties from targeted application abuse such as account takeover attacks, inventory hoarding, carding abuse and more. Bot Management will be available in the second quarter of 2023.
Threat actors specifically target financial services entities with Account Takeover Attacks, and this is where Cloudflare can help. As much as 71% of login requests we see come from bots (Source: Cloudflare Data) Cloudflare’s Bot Management is powered by a global machine learning model that analyses an average of 45 million HTTP requests a second to track botnets across our network. Cloudflare’s Bot Management solution has the potential to benefit all IBM CIS customers.
Supporting banks, financial institutions, and fintechs
IBM Cloud has been a leader when it comes to providing solutions for the financial services industry and has developed several key management solutions that are designed so clients only need to store their private keys in custom built devices.
The IBM CIS team wants to incorporate the right mix of security and performance, which necessitates the use of cloud-based DDoS, WAF, and Bot Management. Specifically, they wanted to incorporate the powerful security tools that were offered through IBM’s Enterprise-level Cloud Internet Services offerings. When using a cloud solution, it is necessary to proxy traffic which can create a potential challenge when it comes to managing private keys. While Cloudflare adopts strict controls to protect these keys, organizations in highly regulated industries may have security policies and compliance requirements that prevent them from sharing these private keys.
Cloudflare built Keyless SSL to allow customers to have total control over exactly where private keys are stored. With Keyless SSL and IBM’s key storage solutions, we aim to help enterprises benefit from the robust application protections available through Cloudflare’s WAF, including Cloudflare Bot Management, while still retaining control of their private keys.
“We aim to ensure our clients meet their resiliency, performance, security and compliance needs. The introduction of Keyless SSL and Bot Management security capabilities can further our collaborative accomplishments with Cloudflare and help enterprises, including those in regulated industries, to leverage cloud-native security and adaptive threat mitigation tools.” — Zane Adam, Vice President, IBM Cloud.
“Through our collaboration with IBM Cloud Internet Services, we get to draw on the knowledge and experience of IBM teams, such as the IBM Cloud for Financial Services team, and combine it with our incredible ability to innovate, resulting in exciting new product and service offerings.” — David McClure, Global Alliance Manager, Strategic Partnerships
ROSA is a fully managed service, jointly supported by AWS and Red Hat. It is managed by Red Hat Site Reliability Engineers and provides a pay-as-you-go pricing model, as well as a unified billing experience on AWS.
With this, customers do not manage the lifecycle of Red Hat OpenShift Container Platform clusters. Instead, they are free to focus on developing new solutions and innovating faster, using IBM’s integrated data and artificial intelligence platform on AWS, to differentiate their business and meet their ever-changing enterprise needs.
CP4D can also be deployed from the AWS Marketplace with self-managed OpenShift clusters. This is ideal for customers with requirements, like Red Hat OpenShift Data Foundation software defined storage, or who prefer to manage their OpenShift clusters.
In this post, we discuss how to deploy CP4D on ROSA using IBM-provided Terraform automation.
Cloud Pak for data architecture
Here, we install CP4D in a highly available ROSA cluster across three availability zones (AZs); with three master nodes, three infrastructure nodes, and three worker nodes.
This is a public ROSA cluster, accessible from the internet via port 443. When deploying CP4D in your AWS account, consider using a private cluster (Figure 1).
Next, let’s create an IAM user from the AWS IAM console, which will be used for the CP4D installation: a. Specify a name, like ibm-cp4d-bastion. b. Set the credential type to Access key – Programmatic access. c. Attach the IAM policy created in Step 3. d. Download the .csv credentials file.
Launch an Amazon EC2 instance from which the CP4D installer is launched: a. Specify a name, like ibm-cp4d-bastion. b. Select an instance type, such as t3.medium. c. Select the EC2 key pair created in Step 4. d. Select the Red Hat Enterprise Linux 8 (HVM), SSD Volume Type for 64-bit (x86)Amazon Machine Image. e. Create a security group with an inbound rule that allows connection. Restrict access to your own IP address or an IP range from your organization. f. Leave all other values as default.
Connect to the EC2 instance via SSH using its public IP address. The remaining installation steps will be initiated from it.
$ cd ~/cp4d-deployment/managed-openshift/aws/terraform/
For the purpose of this post, we enabled Watson Machine Learning, Watson Studio, and Db2 OLTP services on CP4D. Use the example in this step to create a Terraform variables file for CP4D installation. Enable CP4D services required for your use case:
The installation runs for 4 or more hours. Once installation is complete, the output includes (as in Figure 3): a. Commands to get the CP4D URL and the admin user password b. CP4D admin user c. Login command for the ROSA cluster
Figure 3. CP4D installation output
Validation steps
Let’s verify the installation!
Log in to your ROSA cluster using your cluster-admin credentials.
Initiate the following command to get the cluster’s console URL (Figure 4):
$ oc whoami --show-console
Figure 4. ROSA console URL
Run the commands in this step to retrieve the CP4D URL and admin user password (Figure 5).
$ oc extract secret/admin-user-details \
--keys=initial_admin_password --to=- -n zen
$ oc get routes -n zen
Figure 5. Retrieve the CP4D admin user password and URL
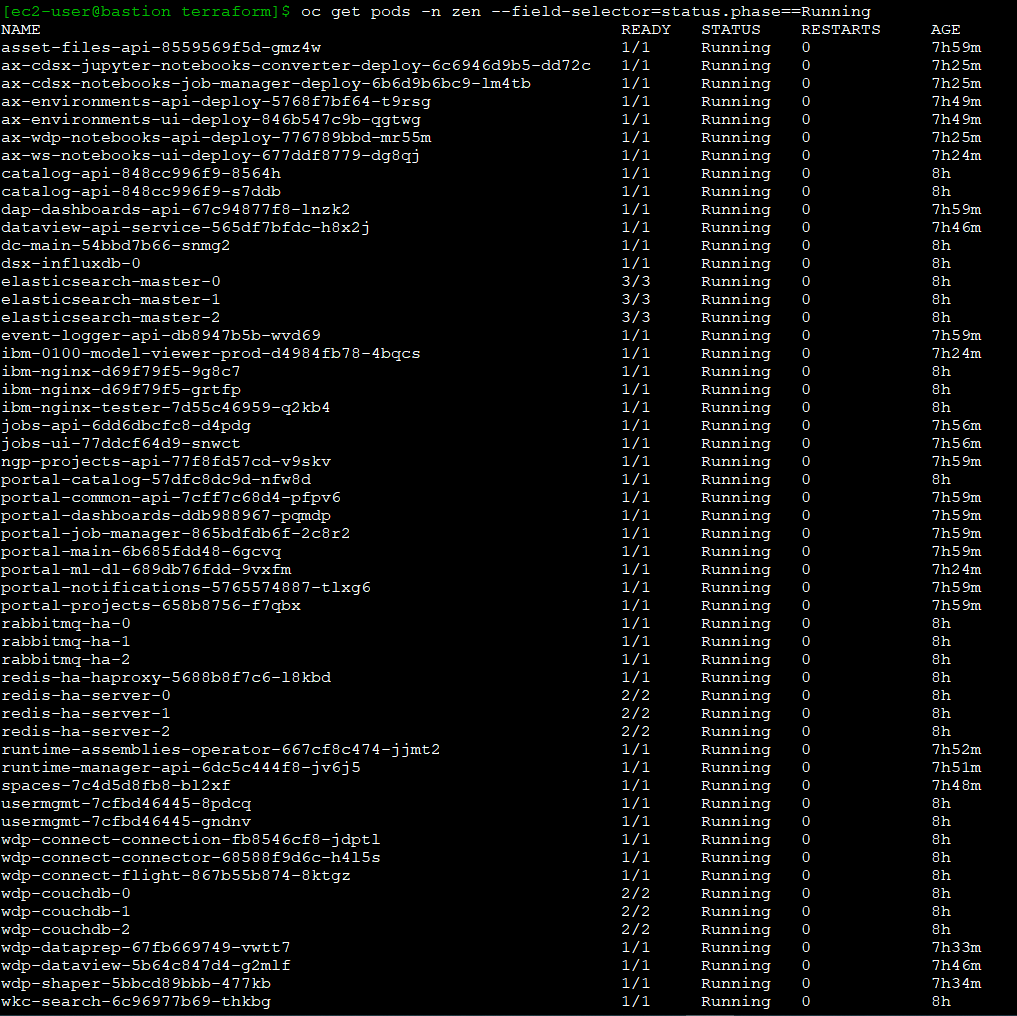
Initiate the following commands to have the CP4D workloads in your ROSA cluster (Figure 6):
$ oc get pods -n zen
$ oc get deployments -n zen
$ oc get svc -n zen
$ oc get pods -n ibm-common-services
$ oc get deployments -n ibm-common-services
$ oc get svc -n ibm-common-services
$ oc get subs -n ibm-common-services
Figure 6. Checking the CP4D pods running on ROSA
Log in to your CP4D web console using its URL and your admin password.
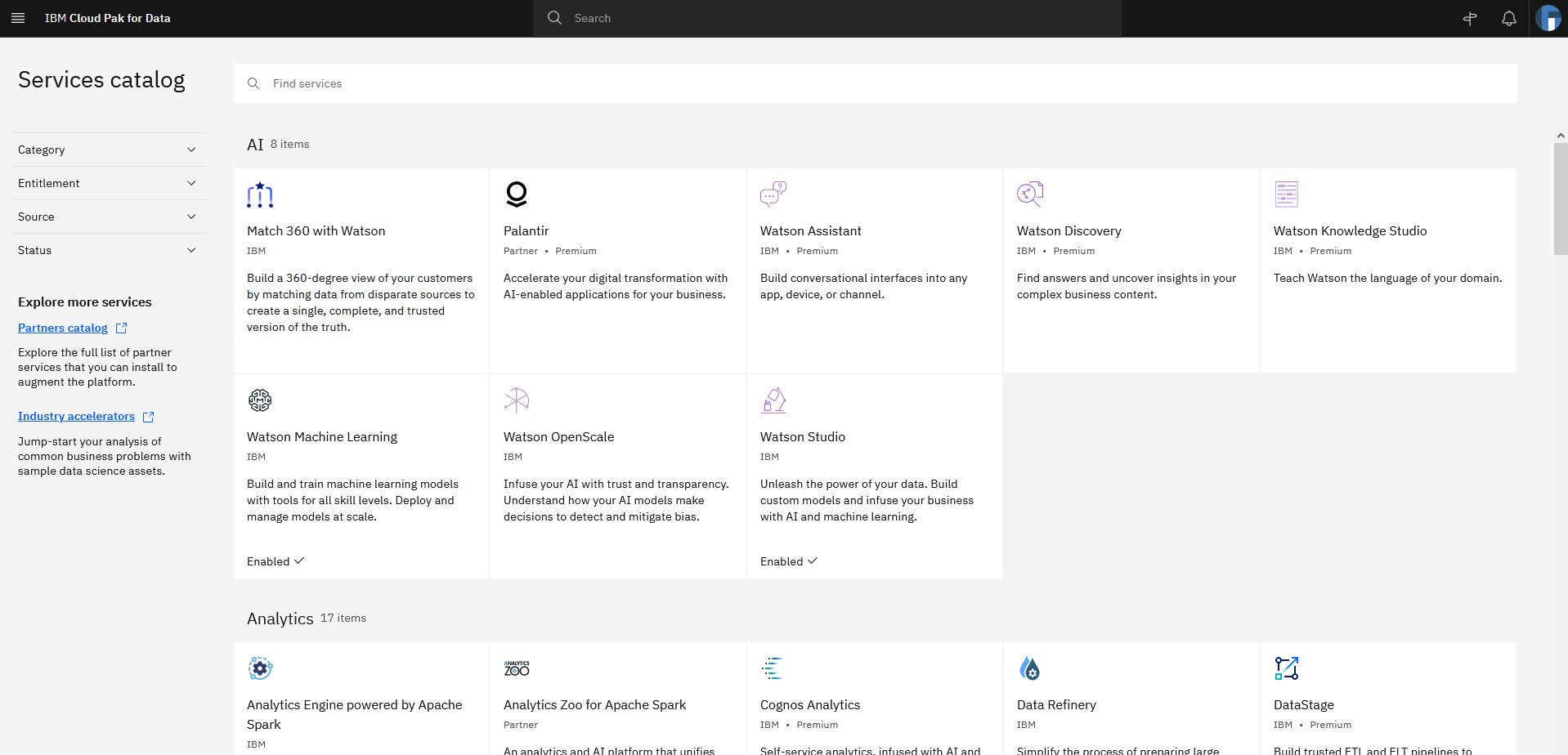
Expand the navigation menu. Navigate to Services > Services catalog for the available services (Figure 7).
Figure 7. Navigating to the CP4D services catalog
Notice that the services set as “enabled” correspond with your Terraform definitions (Figure 8).
Figure 8. Services enabled in your CP4D catalog
Congratulations! You have successfully deployed IBM CP4D on Red Hat OpenShift on AWS.
Post installation
Refer to the IBM documentation on setting up services, if you need to enable additional services on CP4D.
Connect to your bastion host, and run the following steps to delete the CP4D installation, including ROSA. This step avoids incurring future charges on your AWS account.
$ cd ~/cp4d-deployment/managed-openshift/aws/terraform/
$ terraform destroy -var-file="cp4d-rosa-3az-new-vpc.tfvars"
If you’ve experienced any failures during the CP4D installation, run these next steps:
In summary, we explored how customers can take advantage of a fully managed OpenShift service on AWS to run IBM CP4D. With this implementation, customers can focus on what is important to them, their workloads, and their customers, and less on managing the day-to-day operations of managing OpenShift to run CP4D.
Researchers have calculated the quantum computer size necessary to break 256-bit elliptic curve public-key cryptography:
Finally, we calculate the number of physical qubits required to break the 256-bit elliptic curve encryption of keys in the Bitcoin network within the small available time frame in which it would actually pose a threat to do so. It would require 317 × 106 physical qubits to break the encryption within one hour using the surface code, a code cycle time of 1 μs, a reaction time of 10 μs, and a physical gate error of 10-3. To instead break the encryption within one day, it would require 13 × 106 physical qubits.
With Intel attempting to get into 3D gaming graphics again, Custom PC’s Ben Hardwidge looks at the time it failed to take on 3dfx in the late 1990s.
Back in the late 1990s, I worked at a computer shop in Derby, where we sold components over the counter, while pointing to a sign that said ‘components are sold on the basis that the customer is competent to fit it themselves’. There were often compatibility issues between components, but there were two cards I’d always try to steer customers away from, as they nearly always came back to the shop, accompanied by a tired, angry face and colourful vocabulary.
One was a PCI soft modem that required an MMX CPU and refused to cooperate with Freeserve, Dixons’ free ISP that was taking the UK by storm. The other was Express 3D graphics card, based on Intel’s 740 gaming chip.
This was before Nvidia had coined the term ‘GPU’ for its first GeForce cards, which could take the burden of transform and lighting calculations away from the CPU. The CPU was still expected to do a fair bit of work in the 3D pipeline, but you bought a 3D card to speed up the process and make games look much smoother than software rendering.
However, unlike the 3dfx Voodoo and VideoLogic PowerVR cards at the time, which required a 2D card to output to a monitor, the i740 wasn’t a sole 3D card – it could function as a 2D and a 3D card in one unit, and at £30 it was also cheap. You can see why people were drawn to it.
Another factor in its popularity was being made by Intel; thanks to the company’s relentless marketing campaigns, this meant people assumed it would just work without problems. It also used the brand-new Accelerated Graphics Port (AGP) interface, which people often assumed meant it would be faster than the PCI-based 3D accelerator cards.
The problem for us was that people who wanted cheap graphics cards usually also wanted cheap CPUs and motherboards, which meant going for an AMD K6 or Cyrix 6×86 CPU and a non-Intel motherboard chipset. The i740 didn’t like the AGP implementation on non-Intel chipsets very much, and it particularly didn’t like the ALi Aladdin chipset on which our most popular Super Socket 7 motherboards were based.
If you wanted the i740 to run properly, you really needed a Pentium II CPU and Intel 440LX or 440BX motherboard, and they were expensive. Then, once you’d paired your cheap graphics card with your expensive foundation gear, the i740 wasn’t actually that great, with comparably poor performance and still a load of compatibility issues. However, it had some interesting tech and history behind it that’s worth revisiting.
Aerospace beginnings
Intel didn’t have much in the way of graphics tech in the 1990s, but it had spotted a big market for 3D acceleration. The ATX motherboards for its latest Pentium II CPUs also came with an AGP slot, and a 3D AGP graphics card could potentially encourage people to upgrade (more on this later).
With little 3D accelerator expertise in house, Intel teamed up with US aerospace company Lockheed Martin to develop a consumer graphics card. That might seem a bit left field, but Lockheed Martin had acquired a variety of assets through various mergers and takeovers. In 1993, GE Aerospace was sold to Martin Marietta, and in 1995, Martin Marietta merged with Lockheed to form Lockheed Martin.
GE Aerospace was a division of General Electric, and its main business was providing systems and electronic gear to the aerospace and military industries, including simulators. In 1994, it started to branch out, working with Sega to produce the hardware for its Model 2 arcade machines, including 3D graphics tech for texture-mapped polygons and texture filtering. It was used for titles such as Daytona USA and Virtua Fighter 2.
In 1995, Lockheed Martin created a spin-off dedicated to consumer 3D graphics tech called Real3D, mostly using employees from GE Aerospace. Real3D worked with Sega on the 3D graphics hardware in its Model 3 cabinet, which was released in 1996, and then later began working with Intel to produce a consumer 3D graphics card, codenamed ‘Auburn’, which would become the 740.
An AGP showcase?
Intel had clear aims for the i740 when it was released in 1998 – it needed to be cheap and it needed to showcase the new AGP interface featured on the latest Pentium II motherboards. AGP had huge potential.
Although AGP was mainly based on the existing PCI interface, it had a direct connection to the CPU, as opposed to sharing the PCI bus with other cards. This not only freed up bandwidth, but also meant the AGP bus could run at a higher clock speed than the PCI bus.
Real3D’s PCI i740 card was often faster than the AGP equivalent, as it didn’t rely on system memory. Photo credit: vgamuseum.ru
Another one of its benefits was sideband addressing via a dedicated bus, meaning that all the usual address/data lines could be used solely for data throughput rather than both addressing and data functions, with the sideband bus handling address requests.
This massively increased the speed at which an AGP card could read from system memory compared with a PCI card, and meant an AGP card could practically use system memory as well as its on-board memory. You may remember the ‘AGP aperture’ setting in old motherboard BIOS screens – that was the amount of system memory you could allocate to your graphics card.
Most 3D cards didn’t rely on this feature, instead being piled with fast on-board memory to maximise performance, but Intel decided to go all out on it with the i740. The result was a card that only used its on-board memory as a frame buffer, with textures being stored in system memory.
This meant Intel could save money on memory (the cheapest i740 cards only came with 2MB compared to 8MB on the cheapest Voodoo2 cards), while also ensuring the cards required the new AGP interface.
The first problem, of course, was that using system memory and its interface wasn’t anywhere near as fast as using on-board graphics memory. The other problem was that the need for the graphics card to constantly access system memory ended up starving the CPU of memory bandwidth.
That was a big problem at a time when the CPU was still doing a fair bit of the work in the 3D pipeline. The growing use of larger textures in 3D games to improve detail made the situation even worse. What’s more, as I mentioned earlier, the AGP implementations on most Super Socket 7 motherboards just weren’t designed with a card such as the i740 in mind.
It also didn’t help that some board makers (including Real3D under the Starfighter brand) started making PCI versions of the i740 with a bridge chip and more on-board memory, and these cards were usually faster than the AGP equivalents, as they didn’t rely on system memory for texture storage.
Curtains for the i740
What seems bizarre now is that, at the time, I remember a lot of discussion before the launch about how Intel’s work with Real3D was going to result in Intel having a monopoly on 3D graphics, and putting the likes of ATi, 3dfx and VideoLogic out of business.
Intel had access to huge silicon manufacturing facilities, it had a massive research and development budget, and it had the proven expertise of Real3D at its disposal. In reality, the i740 was soon cancelled and almost completely forgotten by the end of 1999.
Custom PC #218 out NOW!
Get your hands on the latest issue of Custom PC at your usual outlet, or online from the Raspberry Pi Press store.
Ben Hardwidge travels back to August 1981, when IBM released its Personal Computer 5150 and the PC was born.
A big ape had only just started lobbing barrels at a pixelated Mario in Donkey Kong arcade machines, Duran Duran’s very first album had just rolled off the vinyl presses and Roger Federer was just four days old. In this time, the UK was even capable of winning Eurovision with Bucks Fizz. It’s August 1981, and IBM has just released the foundation for the PCs we know and love today, the PC 5150.
IBM’s 5150 PC
‘By the late 1970s the personal computer market was maturing rapidly from the many build-it-yourself hobbyist kits to more serious players like Apple, Commodore and Tandy,’ retired IBM veteran Peter Short tells us. ‘As people realised the greater potential for personal computers in business as well as at home, pressure grew on IBM to enter the market with their own PC.’
Short is now a volunteer at IBM’s computer museum in Hursley, which holds a huge archive of the company’s computing machines and documentation, from Victorian punch card machines to the company’s personal computers. We ask him if it felt like the beginning of a new era when the PC was first launched 40 years ago. ‘Yes,’ he says, ‘but probably not the beginning of something so huge that its legacy lives on today.’
At this time, the home computer market was really starting to take off, with primitive 8-bit computers, such as the Sinclair ZX80 and Commodore VIC-20, enabling people at home to get a basic computer that plugged into their TV. At the other end of the scale, large businesses had huge mainframe machines that took up entire rooms, connected to dumb terminals.
There was clearly room for a middle ground. IBM was going to continue producing mainframes and terminals for many years yet, but it also wanted to create a powerful, independent machine that didn’t need a mainframe behind it, and that didn’t cost an exorbitant amount of money.
IBM’s System 23 Datamaster, pictured here at the IBM Hursley Museum, cost $9,000 US
The PC 5150’s launch price of $1,565 US (around £885 ex VAT) for the base spec in 1981 equates to around £3,469 ex VAT in today’s money. That’s still very far from what we’d call cheap, but it was a colossal price drop compared with IBM’s System/23 Datamaster, an all-in-one computer (including screen) that had launched earlier the same year for $9,000 US – six times the price. And even that was massively cheaper than some of IBM’s previous microcomputer designs, such as the 5100, which cost up to $20,000 US in 1975.
IBM needed to act quickly. Commodore had already got a foothold in this market several years earlier with the PET, for example, and IBM realised that it couldn’t spend its usual long development time on the project. The race was on, with the project given a one-year time frame for completion.
‘At the time, IBM was more geared up to its traditional, longer-term development processes,’ explains Short. ‘But it eventually realised that, with a solid reputation in the marketplace, it was time to look for a way to do fast-track development that would not produce a machine three, four or five years behind its competitors.’
Processors and coprocessors
We opened up a PC 5150 for this feature, so we could have a good look at the insides and see how it compares with PCs today. It’s hugely different from the gaming rigs we see now, but there are still some similarities. For starters, the floppy drive connects to the PSU with a 4-pin Molex connector, still seen on PC PSU cables today. The PC was also clearly geared towards expansion from the start.
An AMD 4.77MHz 8088 DIP CPU sits in the bottom socket, with an optional IBM 8087 coprocessor sitting above it for floating point operations
The ticking heart of the box is a 4.77MHz 8088 CPU made by AMD – Intel had given the company a licence to produce clones of its chips so that supply could keep up with demand. It’s for this reason that AMD still has its x86 licence and can produce CPUs for PCs today, but at this point, the two companies weren’t really competitors in the way they are now. To all intents and purposes, an AMD 8088 was exactly the same as an Intel one, and PCs generally came with whichever one was in best supply at the time of the machine’s manufacture.
The CPU itself is an interesting choice. It’s a cut-down version of Intel’s 8086 CPU that it had launched in 1978. The 8088 has the same execution unit design as the 8086, but has an 8-bit external data bus, compared with the 8086’s 16-bit one. As with today’s PCs, the CPU is also removable and replaceable, but in the case of the PC 5150, it’s in a long dual in-line package (DIP) with silver pins, rather than a square socket.
Immediately above the CPU sits another DIP socket for an optional coprocessor. At this point in time, the CPU was only an integer unit with no floating point processor. This was generally fine in an era when most software didn’t overly deal with decimal points, but you had the option to add an 8087 coprocessor underneath it. This worked as an extension of the 8088 CPU. ‘Adding the 8087 allowed numeric calculations to run faster for those users who needed this feature,’ explains Short.
The floppy drive connects to a 4-pin Molex connector on the PSU – a plug that’s still sometimes used in today’s PCs
The decision to use a CPU based on Intel’s x86 instruction set laid the machine code foundation for future PCs, and hasn’t changed since. Comparatively, Apple’s Mac line-up has had a variety of instruction sets, including PowerPC, x86 and now Arm. Nvidia might be making big noises about the future of Arm in the PC, but the x86 instruction set has stood its ground on the PC for 40 years now.
IBM itself has also dabbled with different instruction sets, including its own 801 RISC processor. Why did it go with Intel’s CISC 8088 CPU for the first PC? The answer, according to Short, is mainly down to time and a need to maintain compatibility with industry standards at the time.
‘The first prototype IBM computer using RISC architecture only arrived in 1980 and required a compatible processor,’ he explains. ‘In order to complete the 5150 development in the assigned one-year time frame, IBM had already decided to go with industry-standard components, and there was existing experience with the 8088 from development by GSD (General Systems Division) of the System/23. RISC required the IBM 801 processor, but the decision was made to go with industry standard components.’
Expansion slots
In addition to the ability to add a coprocessor, the IBM PC 5150’s motherboard also contains five expansion slots, with backplate mounts at the back of the case, just like today’s PCs. Three of the slots in our sample were also filled.
The IBM PC 5150 had five 8-bit ISA slots for expansion cards
One card is actually two PCBs sandwiched together – it’s a dual-monitor video card with the ability to output to both an MDA screen and a CGA screen simultaneously (more on these standards later) – each standard required a separate PCB on this card – there’s a composite TV output in addition to the pair of 9-pin monitor outputs as well. Bizarrely, this card also doubles as a parallel port controller, with a ribbon cable providing a 25-pin port. It’s typical of the Wacky Races vibe seen on cards at the time, with multiple features shoehorned into one expansion slot.
Similarly, there’s also a 384KB memory expansion card, which also doubles as a serial I/O card, with a 25-pin port on the backplate. The final card is an MFM storage controller for the 5.25in floppy drive at the front of the machine.
Although the PC was clearly built with expansion in mind, Short points out that ‘IBM was not the first to introduce expansion slots. As far back as 1976, Altair produced the 8800b with an 18-slot backplane, the Apple II also featured slots from 1977 and there was also an expansion bus on the BBC Micro from 1981. No doubt market research and competitive analysis showed that this approach would provide additional flexibility and options without having to redesign the motherboard’.
A raw ISA card at the Hursley museum, designed for hobbyists to make their own expansion cards
Interestingly, though, Short also says IBM was keeping an ‘eye on the hobby market. A standard bus with expansion slots would allow users to create their own peripherals. IBM even announced a Prototyping Card, with an area for standard bus interface components and a larger area for building your own design’. It’s a far cry from the heavily populated PCI-E cards with complex machine soldering that we see today.
Memory
That 384KB memory card shows a very different approach to memory expansion than the tidy modules we have today. Believe it or not, at launch, the PC 5150 base spec came with just 16KB of memory (a millionth of the amount of memory in today’s 16GB machines), which was supplied in the form of DRAM chips on the bottom right corner of the motherboard.
A 5.25in floppy drive was the standard storage system for the 5150, with no hard drive option at launch
The top spec at launch increased that amount to 64KB, although you could theoretically also install the DRAM chips yourself if you could get hold of exactly the right spec of chips and set it up properly. The chips on the motherboard are split into four banks, each with nine chips (eight bits and one parity bit). In the original spec, the 16KB configuration filled one bank, while the 64KB configuration filled all four banks with 16KB of memory each.
A later revision of the motherboard expanded this to 64KB as the base spec with one bank filled, and 256KB with all four banks filled (this is the spec in our sample). If you then added a 384KB memory card, such as the one in our sample, you ended up with 640KB of memory – the maximum base memory addressable by PCs at this time.
The memory is organised in four banks in the bottom right corner of the motherboard – in this case there are four 64KB banks, adding up to a total of 256KB
Graphics and displays
As we previously mentioned, our PC 5150 sample has a dual-monitor card, which supports both the display standards available to the IBM PC at launch. A Mono Display Adaptor (MDA) card could only output text with no graphics, while a Color Graphics Adaptor (CGA) card could output up to four colours (from a palette of 16) at 320 x 200, or output monochrome graphics at 640 x 200.
However, as Short notes, ‘the PC was announced with the mono 5151 display in 1981. The CGA 5153 was not released until 1983’. Even if you had a CGA card in your PC 5150, if you used the original monitor, you wouldn’t be able to see your graphics in colour. Seeing colour graphics either required you to use the composite output or a third-party monitor.
IBM’s colour 5153 monitor didn’t come out until 1983, shown here with an IBM PC XT at Hursley, with Alley Cat in full CGA glory
‘Once the colour monitor became available,’ says Short, ‘it could either be attached as the sole display with its own adaptor card, or equipped with both a mono and colour adaptor card, and could be attached together with a mono screen. Now you could run your spreadsheet on the mono monitor and display output graphics in colour.’
There’s an interesting connection with the first PC monitors and the legacy of IBM’s computing history too. When we interviewed the Hursley Museum’s curator Terry Muldoon (who has now sadly passed away) in 2011, he told us the reason why the first PC monitors had 80 columns. ‘It’s because it’s the same as punch cards,’ he said. ‘All green-screen terminals had 80 columns, because they were basically emulating a punch card.’
Storage
Storage is another area where the PC is at a crossroads between new tech. As standard, the PC 5150 came with a single 5.25in double-density floppy drive, with 360KB of storage space on each disk. There was the option to add a second floppy drive in the empty drive bay, but there was no hard drive at launch.
DOS running on an IBM PC 5150 with a monochrome green screen at Hursley
‘The first hard drive for microcomputers did not arrive until 1980 – the Seagate ST506 with a capacity of 5MB,’ explains Short. ‘By that time, the PC specifications had already been agreed and the hardware development team in Boca Raton was in full swing. The requirement was for a single machine developed within a one-year time frame.
‘A small company called Microsoft was also developing the first version of DOS under sub-contract. The 5150 BIOS therefore had no hard disk support – DOS 1.0 and 1.1 are the same. The power supply selected for the 5150 wasn’t beefy enough at 63W to power the 5150 and a hard drive.’
Later versions of the 5150, such as our sample, came with a 165W PSU, and future DOS versions enabled you to run a hard drive, but it wasn’t until the IBM PC 5160 XT in 1983 that there was a hard drive option with an IBM PC as standard.
You flip the big red switch (BRS) on the side to power the PC 5150 up or down
The PSU also connects to a massive red switch power switch on the side, which is very different from the delicate touch-buttons we have today. You had to literally flip a switch to power on the first PCs. This was another legacy of IBM’s past – a time when, if a machine needed to be shut down drastically, you would ‘BRS it’ – BRS stands for big red switch.
The back of the PC 5150 also alludes to another form of storage. There are two DIN sockets on the back, one of which is labelled for the keyboard – the other is labelled ‘cassette’. ‘It was common at the time to provide software on cassette tapes, which could also be used to store user written programmes,’ says Short. ‘My own Radio Shack TRS80 in 1979 used this method. A standard cassette tape machine such as the Philips could be connected through this socket.’
Software support
This brings us neatly to the subject of software support. We’re now used to graphical user interfaces such as Windows as standard, but in 1981 Microsoft was a small company, which had developed a popular version of the BASIC programming language.
‘Microsoft Basic was already very much an industry standard by 1980,’ says Short. ‘It was Microsoft’s first product. This fitted with the concept of using industry standard components. IBM chose to sub-contract its operating system development to Microsoft, perhaps for this reason. Again, the compressed development schedule influenced these decisions.’
The IBM Personal Computer laid the foundation for the PCs we know and love today
Terry Muldoon gave us some more insight into the development of the PC’s first operating system, IBM PC DOS 1.0, when we spoke to him in 2011. ‘The story I heard is that basically IBM needed an operating system,’ he said, ‘and IBM didn’t have time to write one – that’s the story. So they went out to various people, including Digital Research for CPM, but Digital Research didn’t return the call. Bill Gates did, but he didn’t have an operating system, so he went down the street and bought QDOS.
‘The original DOS was a tarted-up QDOS, supplied to IBM as IBM Personal Computer DOS, and Gates was allowed to sell Microsoft DOS (MS-DOS). And they carried on for many years with exactly the same numbers, so 1.1 was DOS 1 but with support for us foreigners, then we went to DOS 2 with support for hard disks, DOS 2.1 for the Junior, DOS 3 for the PC80 and so on.’
You can have a play with DOS 1.0 on an emulated PC 5150 at custompc.co.uk/5150, and it’s a very basic affair. Even if you’ve used later versions of DOS, there are some notable absences, such as the inability to add ‘/w’ to ‘dir’ to spread out the directory of your A drive across the screen, rather than list all the files in a single column.
What’s also striking is the number of BASIC files supplied as standard, which can be run on the supplied Microsoft BASIC. One example is DONKEY.BAS, a primitive top-down game programmed by Bill Gates and Neil Konzen, where you move a car from left to right to avoid donkeys in the road (really). What’s more, this game specifically requires your PC to have a CGA card and to run BASIC in advanced mode – you couldn’t run it on the base spec.
A future standard
With its keen pricing compared with previous business computers, the IBM PC 5150 was well received in the USA, paving the way for a launch in the UK in 1983, along with DOS 1.1 and the option for a colour CGA monitor. Clone machines from companies such as Compaq soon followed, claiming (usually, but not always, rightly) to be ‘IBM PC compatible’, and the PC started to become the widespread open standard that it is today. Was this intentional on IBM’s part?
‘Industry standard components, an expansion bus and a prototyping card would naturally lead to an open standard,’ says Short. ‘Not publishing the hardware circuitry would make it difficult to capture the imagination of “home” developers. Open architecture was part of the original plan.’
Muldoon wasn’t so sure when we asked him back in 2011. ‘Now where did IBM make the mistake with DOS?’ He asked. ‘This is personal opinion, but IBM allowed Bill Gates to retain the intellectual property. So we’ve now got an Intel processor – the bus was tied to Intel – and another guy owns the operating system, so you’ve already lost control of all of your machine in about 1981. The rest is history.
‘The only bit that IBM owned in the IBM PC was the BIOS, which was copyright. So, to make a computer 100 per cent IBM compatible, you had to have a BIOS. There were loads of software interrupts in that BIOS that people used, such as the timer tick, which were really useful. You get that timer tick and you can get things to happen, so you have to be able to produce something that hits the timer tick, because the software needs it.’
Rival computer makers could circumvent the copyright of the BIOS by examining what it did and attempting to reverse-engineer it. Muldoon explained the process to us.
‘The way people did it is: with one group of people, say: “this is what it does”, and another group of people take that specification, don’t talk to them, and then write some code to make it do that – that’s called “clean room”. So one person documents what it does, and another person now writes code to do it – in other words, nobody has copied IBM code, and there’s a Chinese wall between these two people.
‘What some of the clone manufacturers did is, because we published the BIOS, they just copied it. Now, the BIOS had bugs in it, and we knew they’d copied our BIOS because they’d copied the bugs as well. This was only the small companies that came and went. Phoenix produced a clean room BIOS, so if you used a Phoenix chip in your clones, you were clean.’
Of course, any self-contained personal computer can technically be called a PC. Peter Short describes a PC as a machine that ‘can be operated directly by an end user, from beginning to end, and is general enough in its capabilities’. It doesn’t require an x86 CPU or a Microsoft OS. In fact, there was and still is a variety of operating systems available to x86 PCs, from Gem and OS/2 in the early days, through to the many Linux distributions available now.
However, the PC as we generally know it, with its x86 instruction set and Microsoft OS, started with the PC 5150 in 1981. Storage and memory capacities have hugely increased, as have CPU clock frequencies, but the basic idea of a self-contained box with a proper CPU, enough memory for software to run, its own storage and a display output, as well as room to expand with extra cards, started here. Thank you, IBM.
Custom PC issue 217 out NOW!
You can read more features like this one in Custom PC issue 217, available directly from Raspberry Pi Press — we deliver worldwide.
And if you’d like a handy digital version of the magazine, you can also download issue 217 for free in PDF format.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.