Law professor Dan Solove has a new article on privacy regulation. In his email to me, he writes: “I’ve been pondering privacy consent for more than a decade, and I think I finally made a breakthrough with this article.” His mini-abstract:
In this Article I argue that most of the time, privacy consent is fictitious. Instead of futile efforts to try to turn privacy consent from fiction to fact, the better approach is to lean into the fictions. The law can’t stop privacy consent from being a fairy tale, but the law can ensure that the story ends well. I argue that privacy consent should confer less legitimacy and power and that it be backstopped by a set of duties on organizations that process personal data based on consent.
Full abstract:
Consent plays a profound role in nearly all privacy laws. As Professor Heidi Hurd aptly said, consent works “moral magic”—it transforms things that would be illegal and immoral into lawful and legitimate activities. As to privacy, consent authorizes and legitimizes a wide range of data collection and processing.
There are generally two approaches to consent in privacy law. In the United States, the notice-and-choice approach predominates; organizations post a notice of their privacy practices and people are deemed to consent if they continue to do business with the organization or fail to opt out. In the European Union, the General Data Protection Regulation (GDPR) uses the express consent approach, where people must voluntarily and affirmatively consent.
Both approaches fail. The evidence of actual consent is non-existent under the notice-and-choice approach. Individuals are often pressured or manipulated, undermining the validity of their consent. The express consent approach also suffers from these problems people are ill-equipped to decide about their privacy, and even experts cannot fully understand what algorithms will do with personal data. Express consent also is highly impractical; it inundates individuals with consent requests from thousands of organizations. Express consent cannot scale.
In this Article, I contend that most of the time, privacy consent is fictitious. Privacy law should take a new approach to consent that I call “murky consent.” Traditionally, consent has been binary—an on/off switch—but murky consent exists in the shadowy middle ground between full consent and no consent. Murky consent embraces the fact that consent in privacy is largely a set of fictions and is at best highly dubious.
Because it conceptualizes consent as mostly fictional, murky consent recognizes its lack of legitimacy. To return to Hurd’s analogy, murky consent is consent without magic. Rather than provide extensive legitimacy and power, murky consent should authorize only a very restricted and weak license to use data. Murky consent should be subject to extensive regulatory oversight with an ever-present risk that it could be deemed invalid. Murky consent should rest on shaky ground. Because the law pretends people are consenting, the law’s goal should be to ensure that what people are consenting to is good. Doing so promotes the integrity of the fictions of consent. I propose four duties to achieve this end: (1) duty to obtain consent appropriately; (2) duty to avoid thwarting reasonable expectations; (3) duty of loyalty; and (4) duty to avoid unreasonable risk. The law can’t make the tale of privacy consent less fictional, but with these duties, the law can ensure the story ends well.
The US Cyber Safety Review Board released a report on the summer 2023 hack of Microsoft Exchange by China. It was a serious attack by the Chinese government that accessed the emails of senior US government officials.
From the executive summary:
The Board finds that this intrusion was preventable and should never have occurred. The Board also concludes that Microsoft’s security culture was inadequate and requires an overhaul, particularly in light of the company’s centrality in the technology ecosystem and the level of trust customers place in the company to protect their data and operations. The Board reaches this conclusion based on:
the cascade of Microsoft’s avoidable errors that allowed this intrusion to succeed;
Microsoft’s failure to detect the compromise of its cryptographic crown jewels on its own, relying instead on a customer to reach out to identify anomalies the customer had observed;
the Board’s assessment of security practices at other cloud service providers, which maintained security controls that Microsoft did not;
Microsoft’s failure to detect a compromise of an employee’s laptop from a recently acquired company prior to allowing it to connect to Microsoft’s corporate network in 2021;
Microsoft’s decision not to correct, in a timely manner, its inaccurate public statements about this incident, including a corporate statement that Microsoft believed it had determined the likely root cause of the intrusion when in fact, it still has not; even though Microsoft acknowledged to the Board in November 2023 that its September 6, 2023 blog post about the root cause was inaccurate, it did not update that post until March 12, 2024, as the Board was concluding its review and only after the Board’s repeated questioning about Microsoft’s plans to issue a correction;
the Board’s observation of a separate incident, disclosed by Microsoft in January 2024, the investigation of which was not in the purview of the Board’s review, which revealed a compromise that allowed a different nation-state actor to access highly-sensitive Microsoft corporate email accounts, source code repositories, and internal systems; and
how Microsoft’s ubiquitous and critical products, which underpin essential services that support national security, the foundations of our economy, and public health and safety, require the company to demonstrate the highest standards of security, accountability, and transparency.
The report includes a bunch of recommendations. It’s worth reading in its entirety.
The board was established in early 2022, modeled in spirit after the National Transportation Safety Board. This is their third report.
The ProtonMail people are accusing Microsoft’s new Outlook for Windows app of conducting extensive surveillance on its users. It shares data with advertisers, a lot of data:
The window informs users that Microsoft and those 801 third parties use their data for a number of purposes, including to:
Store and/or access information on the user’s device
Oh, how the mighty have fallen. A decade ago, social media was celebrated for sparking democratic uprisings in the Arab world and beyond. Now front pages are splashed with stories of social platforms’ role in misinformation, business conspiracy, malfeasance, and risks to mental health. In a 2022 survey, Americans blamed social media for the coarsening of our political discourse, the spread of misinformation, and the increase in partisan polarization.
Today, tech’s darling is artificial intelligence. Like social media, it has the potential to change the world in many ways, some favorable to democracy. But at the same time, it has the potential to do incredible damage to society.
There is a lot we can learn about social media’s unregulated evolution over the past decade that directly applies to AI companies and technologies. These lessons can help us avoid making the same mistakes with AI that we did with social media.
In particular, five fundamental attributes of social media have harmed society. AI also has those attributes. Note that they are not intrinsically evil. They are all double-edged swords, with the potential to do either good or ill. The danger comes from who wields the sword, and in what direction it is swung. This has been true for social media, and it will similarly hold true for AI. In both cases, the solution lies in limits on the technology’s use.
#1: Advertising
The role advertising plays in the internet arose more by accident than anything else. When commercialization first came to the internet, there was no easy way for users to make micropayments to do things like viewing a web page. Moreover, users were accustomed to free access and wouldn’t accept subscription models for services. Advertising was the obvious business model, if never the best one. And it’s the model that social media also relies on, which leads it to prioritize engagement over anything else.
Both Google and Facebook believe that AI will help them keep their stranglehold on an 11-figure online ad market (yep, 11 figures), and the tech giants that are traditionally less dependent on advertising, like Microsoft and Amazon, believe that AI will help them seize a bigger piece of that market.
Big Tech needs something to persuade advertisers to keep spending on their platforms. Despite bombastic claims about the effectiveness of targeted marketing, researchers have long struggled to demonstrate where and when online ads really have an impact. When major brands like Uber and Procter & Gamble recently slashed their digital ad spending by the hundreds of millions, they proclaimed that it made no dent at all in their sales.
AI-powered ads, industry leaders say, will be much better. Google assures you that AI can tweak your ad copy in response to what users search for, and that its AI algorithms will configure your campaigns to maximize success. Amazon wants you to use its image generation AI to make your toaster product pages look cooler. And IBM is confident its Watson AI will make your ads better.
These techniques border on the manipulative, but the biggest risk to users comes from advertising within AI chatbots. Just as Google and Meta embed ads in your search results and feeds, AI companies will be pressured to embed ads in conversations. And because those conversations will be relational and human-like, they could be more damaging. While many of us have gotten pretty good at scrolling past the ads in Amazon and Google results pages, it will be much harder to determine whether an AI chatbot is mentioning a product because it’s a good answer to your question or because the AI developer got a kickback from the manufacturer.
#2: Surveillance
Social media’s reliance on advertising as the primary way to monetize websites led to personalization, which led to ever-increasing surveillance. To convince advertisers that social platforms can tweak ads to be maximally appealing to individual people, the platforms must demonstrate that they can collect as much information about those people as possible.
It’s hard to exaggerate how much spying is going on. A recent analysis by Consumer Reports about Facebook—just Facebook—showed that every user has more than 2,200 different companies spying on their web activities on its behalf.
AI-powered platforms that are supported by advertisers will face all the same perverse and powerful market incentives that social platforms do. It’s easy to imagine that a chatbot operator could charge a premium if it were able to claim that its chatbot could target users on the basis of their location, preference data, or past chat history and persuade them to buy products.
The possibility of manipulation is only going to get greater as we rely on AI for personal services. One of the promises of generative AI is the prospect of creating a personal digital assistant advanced enough to act as your advocate with others and as a butler to you. This requires more intimacy than you have with your search engine, email provider, cloud storage system, or phone. You’re going to want it with you constantly, and to most effectively work on your behalf, it will need to know everything about you. It will act as a friend, and you are likely to treat it as such, mistakenly trusting its discretion.
Even if you choose not to willingly acquaint an AI assistant with your lifestyle and preferences, AI technology may make it easier for companies to learn about you. Early demonstrations illustrate how chatbots can be used to surreptitiously extract personal data by asking you mundane questions. And with chatbots increasingly being integrated with everything from customer service systems to basic search interfaces on websites, exposure to this kind of inferential data harvesting may become unavoidable.
#3: Virality
Social media allows any user to express any idea with the potential for instantaneous global reach. A great public speaker standing on a soapbox can spread ideas to maybe a few hundred people on a good night. A kid with the right amount of snark on Facebook can reach a few hundred million people within a few minutes.
A decade ago, technologists hoped this sort of virality would bring people together and guarantee access to suppressed truths. But as a structural matter, it is in a social network’s interest to show you the things you are most likely to click on and share, and the things that will keep you on the platform.
As it happens, this often means outrageous, lurid, and triggering content. Researchers have found that content expressing maximal animosity toward political opponents gets the most engagement on Facebook and Twitter. And this incentive for outrage drives and rewards misinformation.
As Jonathan Swift once wrote, “Falsehood flies, and the Truth comes limping after it.” Academics seem to have proved this in the case of social media; people are more likely to share false information—perhaps because it seems more novel and surprising. And unfortunately, this kind of viral misinformation has been pervasive.
AI has the potential to supercharge the problem because it makes content production and propagation easier, faster, and more automatic. Generative AI tools can fabricate unending numbers of falsehoods about any individual or theme, some of which go viral. And those lies could be propelled by social accounts controlled by AI bots, which can share and launder the original misinformation at any scale.
Remarkably powerful AI text generators and autonomous agents are already starting to make their presence felt in social media. In July, researchers at Indiana University revealed a botnet of more than 1,100 Twitter accounts that appeared to be operated using ChatGPT.
AI will help reinforce viral content that emerges from social media. It will be able to create websites and web content, user reviews, and smartphone apps. It will be able to simulate thousands, or even millions, of fake personas to give the mistaken impression that an idea, or a political position, or use of a product, is more common than it really is. What we might perceive to be vibrant political debate could be bots talking to bots. And these capabilities won’t be available just to those with money and power; the AI tools necessary for all of this will be easily available to us all.
#4: Lock-in
Social media companies spend a lot of effort making it hard for you to leave their platforms. It’s not just that you’ll miss out on conversations with your friends. They make it hard for you to take your saved data—connections, posts, photos—and port it to another platform. Every moment you invest in sharing a memory, reaching out to an acquaintance, or curating your follows on a social platform adds a brick to the wall you’d have to climb over to go to another platform.
This concept of lock-in isn’t unique to social media. Microsoft cultivated proprietary document formats for years to keep you using its flagship Office product. Your music service or e-book reader makes it hard for you to take the content you purchased to a rival service or reader. And if you switch from an iPhone to an Android device, your friends might mock you for sending text messages in green bubbles. But social media takes this to a new level. No matter how bad it is, it’s very hard to leave Facebook if all your friends are there. Coordinating everyone to leave for a new platform is impossibly hard, so no one does.
Similarly, companies creating AI-powered personal digital assistants will make it hard for users to transfer that personalization to another AI. If AI personal assistants succeed in becoming massively useful time-savers, it will be because they know the ins and outs of your life as well as a good human assistant; would you want to give that up to make a fresh start on another company’s service? In extreme examples, some people have formed close, perhaps even familial, bonds with AI chatbots. If you think of your AI as a friend or therapist, that can be a powerful form of lock-in.
Lock-in is an important concern because it results in products and services that are less responsive to customer demand. The harder it is for you to switch to a competitor, the more poorly a company can treat you. Absent any way to force interoperability, AI companies have less incentive to innovate in features or compete on price, and fewer qualms about engaging in surveillance or other bad behaviors.
#5: Monopolization
Social platforms often start off as great products, truly useful and revelatory for their consumers, before they eventually start monetizing and exploiting those users for the benefit of their business customers. Then the platforms claw back the value for themselves, turning their products into truly miserable experiences for everyone. This is a cycle that Cory Doctorow has powerfully written about and traced through the history of Facebook, Twitter, and more recently TikTok.
The reason for these outcomes is structural. The network effects of tech platforms push a few firms to become dominant, and lock-in ensures their continued dominance. The incentives in the tech sector are so spectacularly, blindingly powerful that they have enabled six megacorporations (Amazon, Apple, Google, Facebook parent Meta, Microsoft, and Nvidia) to command a trillion dollars each of market value—or more. These firms use their wealth to block any meaningful legislation that would curtail their power. And they sometimes collude with each other to grow yet fatter.
This cycle is clearly starting to repeat itself in AI. Look no further than the industry poster child OpenAI, whose leading offering, ChatGPT, continues to set marks for uptake and usage. Within a year of the product’s launch, OpenAI’s valuation had skyrocketed to about $90 billion.
OpenAI once seemed like an “open” alternative to the megacorps—a common carrier for AI services with a socially oriented nonprofit mission. But the Sam Altman firing-and-rehiring debacle at the end of 2023, and Microsoft’s central role in restoring Altman to the CEO seat, simply illustrated how venture funding from the familiar ranks of the tech elite pervades and controls corporate AI. In January 2024, OpenAI took a big step toward monetization of this user base by introducing its GPT Store, wherein one OpenAI customer can charge another for the use of its custom versions of OpenAI software; OpenAI, of course, collects revenue from both parties. This sets in motion the very cycle Doctorow warns about.
In the middle of this spiral of exploitation, little or no regard is paid to externalities visited upon the greater public—people who aren’t even using the platforms. Even after society has wrestled with their ill effects for years, the monopolistic social networks have virtually no incentive to control their products’ environmental impact, tendency to spread misinformation, or pernicious effects on mental health. And the government has applied virtually no regulation toward those ends.
Likewise, few or no guardrails are in place to limit the potential negative impact of AI. Facial recognition software that amounts to racial profiling, simulated public opinions supercharged by chatbots, fake videos in political ads—all of it persists in a legal gray area. Even clear violators of campaign advertising law might, some think, be let off the hook if they simply do it with AI.
Mitigating the risks
The risks that AI poses to society are strikingly familiar, but there is one big difference: it’s not too late. This time, we know it’s all coming. Fresh off our experience with the harms wrought by social media, we have all the warning we should need to avoid the same mistakes.
The biggest mistake we made with social media was leaving it as an unregulated space. Even now—after all the studies and revelations of social media’s negative effects on kids and mental health, after Cambridge Analytica, after the exposure of Russian intervention in our politics, after everything else—social media in the US remains largely an unregulated “weapon of mass destruction.” Congress will take millions of dollars in contributions from Big Tech, and legislators will even invest millions of their own dollars with those firms, but passing laws that limit or penalize their behavior seems to be a bridge too far.
We can’t afford to do the same thing with AI, because the stakes are even higher. The harm social media can do stems from how it affects our communication. AI will affect us in the same ways and many more besides. If Big Tech’s trajectory is any signal, AI tools will increasingly be involved in how we learn and how we express our thoughts. But these tools will also influence how we schedule our daily activities, how we design products, how we write laws, and even how we diagnose diseases. The expansive role of these technologies in our daily lives gives for-profit corporations opportunities to exert control over more aspects of society, and that exposes us to the risks arising from their incentives and decisions.
The good news is that we have a whole category of tools to modulate the risk that corporate actions pose for our lives, starting with regulation. Regulations can come in the form of restrictions on activity, such as limitations on what kinds of businesses and products are allowed to incorporate AI tools. They can come in the form of transparency rules, requiring disclosure of what data sets are used to train AI models or what new preproduction-phase models are being trained. And they can come in the form of oversight and accountability requirements, allowing for civil penalties in cases where companies disregard the rules.
The single biggest point of leverage governments have when it comes to tech companies is antitrust law. Despite what many lobbyists want you to think, one of the primary roles of regulation is to preserve competition—not to make life harder for businesses. It is not inevitable for OpenAI to become another Meta, an 800-pound gorilla whose user base and reach are several times those of its competitors. In addition to strengthening and enforcing antitrust law, we can introduce regulation that supports competition-enabling standards specific to the technology sector, such as data portability and device interoperability. This is another core strategy for resisting monopoly and corporate control.
Additionally, governments can enforce existing regulations on advertising. Just as the US regulates what media can and cannot host advertisements for sensitive products like cigarettes, and just as many other jurisdictions exercise strict control over the time and manner of politically sensitive advertising, so too could the US limit the engagement between AI providers and advertisers.
Lastly, we should recognize that developing and providing AI tools does not have to be the sovereign domain of corporations. We, the people and our government, can do this too. The proliferation of open-source AI development in 2023, successful to an extent that startled corporate players, is proof of this. And we can go further, calling on our government to build public-option AI tools developed with political oversight and accountability under our democratic system, where the dictatorship of the profit motive does not apply.
Which of these solutions is most practical, most important, or most urgently needed is up for debate. We should have a vibrant societal dialogue about whether and how to use each of these tools. There are lots of paths to a good outcome.
The problem is that this isn’t happening now, particularly in the US. And with a looming presidential election, conflict spreading alarmingly across Asia and Europe, and a global climate crisis, it’s easy to imagine that we won’t get our arms around AI any faster than we have (not) with social media. But it’s not too late. These are still the early years for practical consumer AI applications. We must and can do better.
This essay was written with Nathan Sanders, and was originally published in MIT Technology Review.
Modern cars are internet-enabled, allowing access to services like navigation, roadside assistance and car apps that drivers can connect to their vehicles to locate them or unlock them remotely. In recent years, automakers, including G.M., Honda, Kia and Hyundai, have started offering optional features in their connected-car apps that rate people’s driving. Some drivers may not realize that, if they turn on these features, the car companies then give information about how they drive to data brokers like LexisNexis [who then sell it to insurance companies].
Automakers and data brokers that have partnered to collect detailed driving data from millions of Americans say they have drivers’ permission to do so. But the existence of these partnerships is nearly invisible to drivers, whose consent is obtained in fine print and murky privacy policies that few read.
Cookies are small files of information that a web server generates and sends to a web browser. For example, a cookie stored in your browser will let a website know that you are already logged in, so instead of showing you a login page, you would be taken to your account page welcoming you back.
Though cookies are very useful, they are also used for tracking and advertising, sometimes with repercussions for user privacy. Cookies are a core tool, for example, for all advertising networks. To protect users, privacy laws may require website owners to clearly specify what cookies are being used and for what purposes, and, in many cases, to obtain a user’s consent before storing those cookies in the user’s browser. A key example of this is the ePrivacy Directive.
Herein lies the problem: often website administrators, developers, or compliance team members don’t know what cookies are being used by their website. A common approach for gaining a better understanding of cookie usage is to set up a scanner bot that crawls through each page, collecting cookies along the way. However, many websites requiring authentication or additional security measures do not allow for these scans, or require custom security settings to allow the scanner bot access.
To address these issues, we developed Page Shield Cookie Monitor, which provides a full single dashboard view of all first-party cookies being used by your websites. Over the next few weeks, we are rolling out Page Shield Cookie Monitor to all paid plans, no configuration or scanners required if Page Shield is enabled.
HTTP cookies
HTTP cookies are designed to allow persistence for the stateless HTTP protocol. A basic example of cookie usage is to identify a logged-in user. The browser submits the cookie back to the website whenever you access it again, letting the website know who you are, providing you a customized experience. Cookies are implemented as HTTP headers.
Cookies can be classified as first-party or third-party.
First-party cookies are normally set by the website owner1, and are used to track state against the given website. The logged in example above falls into this category. First party cookies are normally restricted and sent to the given website only and won’t be visible by other sites.
Third-party cookies, on the other hand, are often set by large advertising networks, social networks, or other large organizations that want to track user journeys across the web (across domains). For example, some websites load advertisement objects from a different domain that may set a third-party cookie associated with that advertising network.
Cookies are used for tracking
Growing concerns around user privacy has led browsers to start blocking third-party cookies by default. Led by Firefox and Safari a few years back, Google Chrome, which currently has the largest browser market share, and whose parent company owns Google Ads, the dominant advertising network, started restricting third-party cookies beginning in January of this year.
However, this does not mean the end of tracking users for advertising purposes; the technology has advanced allowing tracking to continue based on first-party cookies. Facebook Pixel, for example, started offering to set first-party cookies alongside third-party cookies in 2018 when being embedded in a website, in order “to be more accurate in measurement and reporting”.
Scanning for cookies?
To inventory all the cookies used when your website is accessed, you can open up any modern browser’s developer console and review which cookie is being set and sent back per HTTP request. However, collecting cookies with this approach won’t be practical unless your website is rather static, containing few external snippets.
Screen capture of Chrome’s developer console listing cookies being set and sent back when visiting a website.
To resolve this, a cookie scanner can be used to automate cookie collection. Depending on your security setup, additional configurations are sometimes required in order to let the scanner bots pass through protection and/or authentication. This may open up a potential attack surface, which isn’t ideal.
Introducing Page Shield Cookie Monitor
With Page Shield enabled, all the first-party cookies, whether set by your website or by external snippets, are collected and displayed in one place, no scanner required. With the click of a button, the full list can be exported in CSV format for further inventory processing.
If you run multiple websites like a marketing website and an admin console that require different cookie strategies, you can simply filter the list based on either domain or path, under the same view. This includes the websites that require authentication such as the admin console.
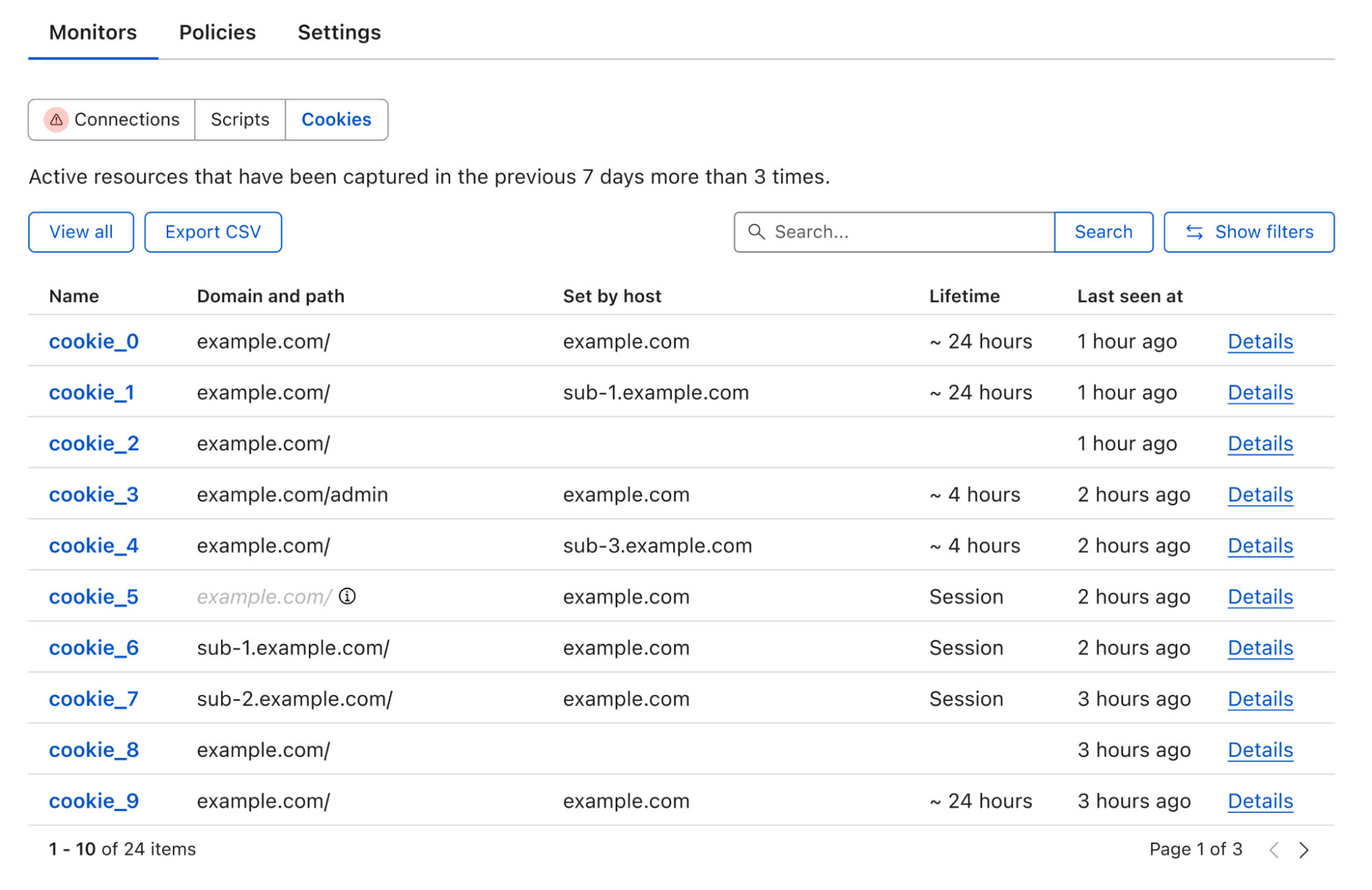
Dashboard showing a table of cookies seen, including key details such as cookie name, domain and path, and which host set the cookie.
To examine a particular cookie, clicking on its name takes you to a dedicated page that includes all the cookie attributes. Furthermore, similar to Script Monitor and Connection Monitor, we collect the first seen and last seen time and pages for easier tracking of your website’s behavior.
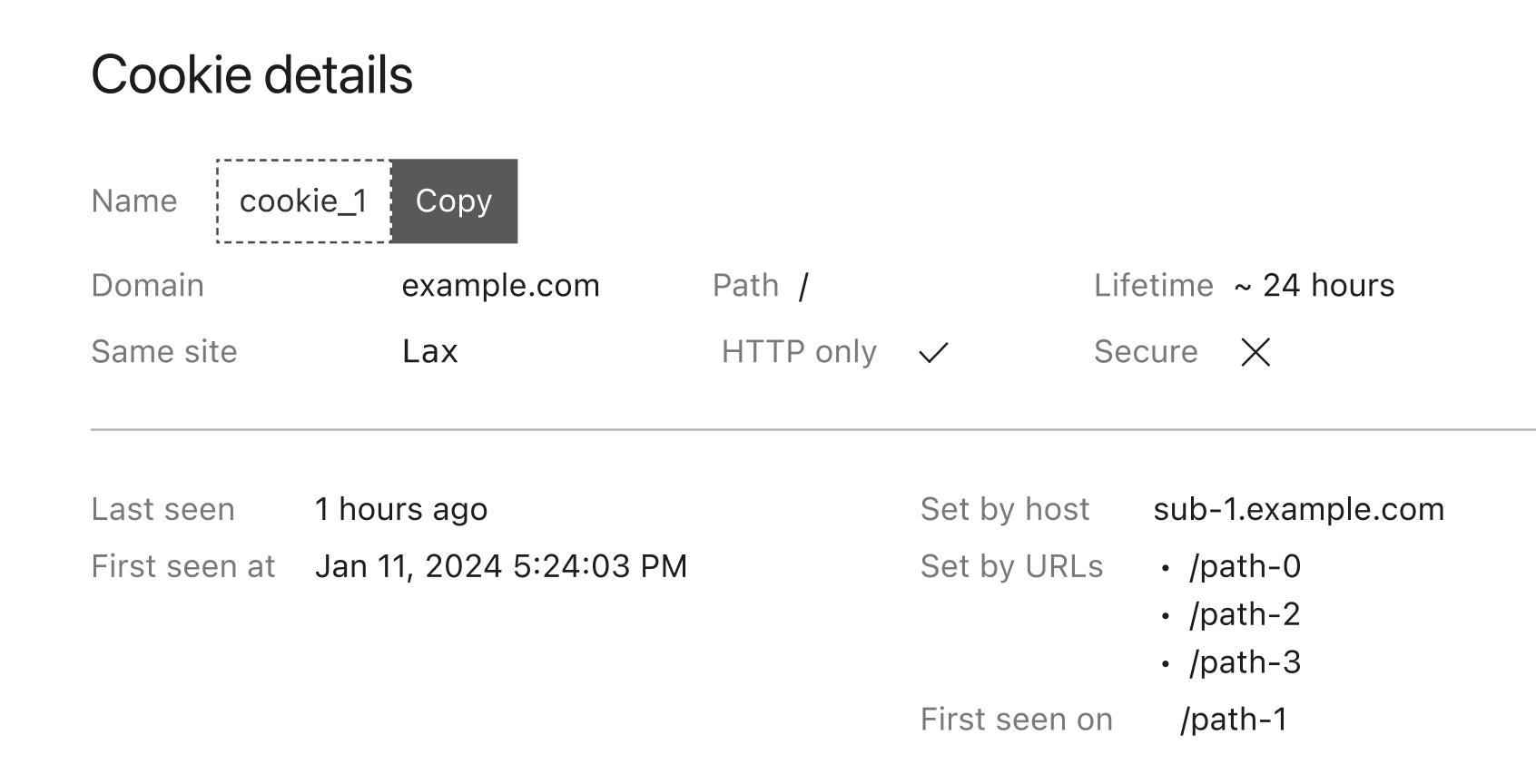
Detailed view of a captured cookie in the dashboard, including all cookie attributes as well as under which host and path this cookie has been set.
Last but not least, we are adding one more alert type specifically for newly seen cookies. When subscribed to this alert, we will notify you through either email or webhook as soon as a new cookie is detected with all the details mentioned above. This allows you to trigger any workflow required, such as inventorying this new cookie for compliance.
How Cookie Monitor works
Let’s imagine you run an e-commerce website example.com. When a user logs in to view their ongoing orders, your website would send a header with key Set-Cookie, and value to identify each user’s login activity:
login_id=ABC123; Domain=.example.com
To analyze visitor behaviors, you make use of Google Analytics that requires embedding a code snippet in all web pages. This snippet will set two more cookies after the pages are loaded in the browser:
_ga=GA1.2; Domain=.example.com;
_ga_ABC=GS1.3; Domain=.example.com;
As these two cookies from Google Analytics are considered first-party given their domain attribute, they are automatically included together with the logged-in cookie sent back to your website. The final cookie sent back for a logged-in user would be Cookie: login_id=ABC123; _ga=GA1.2; _ga_ABC=GS1.3 with three cookies concatenated into one string, even though only one of them is directly consumed by your website.
If your website happens to be proxied through Cloudflare already, we will observe oneSet-Cookie header with cookie name of login_id during response, while receiving three cookies back: login_id, _ga, and _ga_ABC. Comparing one cookie set with three returned cookies, the overlapping login_id cookie is then tagged as set by your website directly. The same principle applies to all the requests passing through Cloudflare, allowing us to build an overview of all the first-party cookies used by your websites.
All cookies in one jar
Inventorying all cookies set through using your websites is a first step towards protecting your users’ privacy, and Page Shield makes this step just one click away. Sign up now to be notified when Page Shield Cookie Monitor becomes available!
…
1Technically, a first-party cookie is a cookie scoped to the given domain only (so not cross domain). Such a cookie can also be set by a third party snippet used by the website to the given domain.
In June 2023, we told you that we were building a new protocol, MASQUE, into WARP. MASQUE is a fascinating protocol that extends the capabilities of HTTP/3 and leverages the unique properties of the QUIC transport protocol to efficiently proxy IP and UDP traffic without sacrificing performance or privacy
At the same time, we’ve seen a rising demand from Zero Trust customers for features and solutions that only MASQUE can deliver. All customers want WARP traffic to look like HTTPS to avoid detection and blocking by firewalls, while a significant number of customers also require FIPS-compliant encryption. We have something good here, and it’s been proven elsewhere (more on that below), so we are building MASQUE into Zero Trust WARP and will be making it available to all of our Zero Trust customers — at WARP speed!
This blog post highlights some of the key benefits our Cloudflare One customers will realize with MASQUE.
Before the MASQUE
Cloudflare is on a mission to help build a better Internet. And it is a journey we’ve been on with our device client and WARP for almost five years. The precursor to WARP was the 2018 launch of 1.1.1.1, the Internet’s fastest, privacy-first consumer DNS service. WARP was introduced in 2019 with the announcement of the 1.1.1.1 service with WARP, a high performance and secure consumer DNS and VPN solution. Then in 2020, we introduced Cloudflare’s Zero Trust platform and the Zero Trust version of WARP to help any IT organization secure their environment, featuring a suite of tools we first built to protect our own IT systems. Zero Trust WARP with MASQUE is the next step in our journey.
The current state of WireGuard
WireGuard was the perfect choice for the 1.1.1.1 with WARP service in 2019. WireGuard is fast, simple, and secure. It was exactly what we needed at the time to guarantee our users’ privacy, and it has met all of our expectations. If we went back in time to do it all over again, we would make the same choice.
But the other side of the simplicity coin is a certain rigidity. We find ourselves wanting to extend WireGuard to deliver more capabilities to our Zero Trust customers, but WireGuard is not easily extended. Capabilities such as better session management, advanced congestion control, or simply the ability to use FIPS-compliant cipher suites are not options within WireGuard; these capabilities would have to be added on as proprietary extensions, if it was even possible to do so.
Plus, while WireGuard is popular in VPN solutions, it is not standards-based, and therefore not treated like a first class citizen in the world of the Internet, where non-standard traffic can be blocked, sometimes intentionally, sometimes not. WireGuard uses a non-standard port, port 51820, by default. Zero Trust WARP changes this to use port 2408 for the WireGuard tunnel, but it’s still a non-standard port. For our customers who control their own firewalls, this is not an issue; they simply allow that traffic. But many of the large number of public Wi-Fi locations, or the approximately 7,000 ISPs in the world, don’t know anything about WireGuard and block these ports. We’ve also faced situations where the ISP does know what WireGuard is and blocks it intentionally.
This can play havoc for roaming Zero Trust WARP users at their local coffee shop, in hotels, on planes, or other places where there are captive portals or public Wi-Fi access, and even sometimes with their local ISP. The user is expecting reliable access with Zero Trust WARP, and is frustrated when their device is blocked from connecting to Cloudflare’s global network.
Now we have another proven technology — MASQUE — which uses and extends HTTP/3 and QUIC. Let’s do a quick review of these to better understand why Cloudflare believes MASQUE is the future.
Unpacking the acronyms
HTTP/3 and QUIC are among the most recent advancements in the evolution of the Internet, enabling faster, more reliable, and more secure connections to endpoints like websites and APIs. Cloudflare worked closely with industry peers through the Internet Engineering Task Force on the development of RFC 9000 for QUIC and RFC 9114 for HTTP/3. The technical background on the basic benefits of HTTP/3 and QUIC are reviewed in our 2019 blog post where we announced QUIC and HTTP/3 availability on Cloudflare’s global network.
Most relevant for Zero Trust WARP, QUIC delivers better performance on low-latency or high packet loss networks thanks to packet coalescing and multiplexing. QUIC packets in separate contexts during the handshake can be coalesced into the same UDP datagram, thus reducing the number of receive and system interrupts. With multiplexing, QUIC can carry multiple HTTP sessions within the same UDP connection. Zero Trust WARP also benefits from QUIC’s high level of privacy, with TLS 1.3 designed into the protocol.
MASQUE unlocks QUIC’s potential for proxying by providing the application layer building blocks to support efficient tunneling of TCP and UDP traffic. In Zero Trust WARP, MASQUE will be used to establish a tunnel over HTTP/3, delivering the same capability as WireGuard tunneling does today. In the future, we’ll be in position to add more value using MASQUE, leveraging Cloudflare’s ongoing participation in the MASQUE Working Group. This blog post is a good read for those interested in digging deeper into MASQUE.
OK, so Cloudflare is going to use MASQUE for WARP. What does that mean to you, the Zero Trust customer?
Proven reliability at scale
Cloudflare’s network today spans more than 310 cities in over 120 countries, and interconnects with over 13,000 networks globally. HTTP/3 and QUIC were introduced to the Cloudflare network in 2019, the HTTP/3 standard was finalized in 2022, and represented about 30% of all HTTP traffic on our network in 2023.
We are also using MASQUE for iCloud Private Relay and other Privacy Proxy partners. The services that power these partnerships, from our Rust-based proxy framework to our open source QUIC implementation, are already deployed globally in our network and have proven to be fast, resilient, and reliable.
Cloudflare is already operating MASQUE, HTTP/3, and QUIC reliably at scale. So we want you, our Zero Trust WARP users and Cloudflare One customers, to benefit from that same reliability and scale.
Connect from anywhere
Employees need to be able to connect from anywhere that has an Internet connection. But that can be a challenge as many security engineers will configure firewalls and other networking devices to block all ports by default, and only open the most well-known and common ports. As we pointed out earlier, this can be frustrating for the roaming Zero Trust WARP user.
We want to fix that for our users, and remove that frustration. HTTP/3 and QUIC deliver the perfect solution. QUIC is carried on top of UDP (protocol number 17), while HTTP/3 uses port 443 for encrypted traffic. Both of these are well known, widely used, and are very unlikely to be blocked.
We want our Zero Trust WARP users to reliably connect wherever they might be.
Compliant cipher suites
MASQUE leverages TLS 1.3 with QUIC, which provides a number of cipher suite choices. WireGuard also uses standard cipher suites. But some standards are more, let’s say, standard than others.
NIST, the National Institute of Standards and Technology and part of the US Department of Commerce, does a tremendous amount of work across the technology landscape. Of interest to us is the NIST research into network security that results in FIPS 140-2 and similar publications. NIST studies individual cipher suites and publishes lists of those they recommend for use, recommendations that become requirements for US Government entities. Many other customers, both government and commercial, use these same recommendations as requirements.
Our first MASQUE implementation for Zero Trust WARP will use TLS 1.3 and FIPS compliant cipher suites.
How can I get Zero Trust WARP with MASQUE?
Cloudflare engineers are hard at work implementing MASQUE for the mobile apps, the desktop clients, and the Cloudflare network. Progress has been good, and we will open this up for beta testing early in the second quarter of 2024 for Cloudflare One customers. Your account team will be reaching out with participation details.
Continuing the journey with Zero Trust WARP
Cloudflare launched WARP five years ago, and we’ve come a long way since. This introduction of MASQUE to Zero Trust WARP is a big step, one that will immediately deliver the benefits noted above. But there will be more — we believe MASQUE opens up new opportunities to leverage the capabilities of QUIC and HTTP/3 to build innovative Zero Trust solutions. And we’re also continuing to work on other new capabilities for our Zero Trust customers. Cloudflare is committed to continuing our mission to help build a better Internet, one that is more private and secure, scalable, reliable, and fast. And if you would like to join us in this exciting journey, check out our open positions.
The Washington Post is reporting on the FBI’s increasing use of push notification data—”push tokens”—to identify people. The police can request this data from companies like Apple and Google without a warrant.
The investigative technique goes back years. Court orders that were issued in 2019 to Apple and Google demanded that the companies hand over information on accounts identified by push tokens linked to alleged supporters of the Islamic State terrorist group.
But the practice was not widely understood until December, when Sen. Ron Wyden (D-Ore.), in a letter to Attorney General Merrick Garland, said an investigation had revealed that the Justice Department had prohibited Apple and Google from discussing the technique.
[…]
Unlike normal app notifications, push alerts, as their name suggests, have the power to jolt a phone awake—a feature that makes them useful for the urgent pings of everyday use. Many apps offer push-alert functionality because it gives users a fast, battery-saving way to stay updated, and few users think twice before turning them on.
But to send that notification, Apple and Google require the apps to first create a token that tells the company how to find a user’s device. Those tokens are then saved on Apple’s and Google’s servers, out of the users’ reach.
The article discusses their use by the FBI, primarily in child sexual abuse cases. But we all know how the story goes:
“This is how any new surveillance method starts out: The government says we’re only going to use this in the most extreme cases, to stop terrorists and child predators, and everyone can get behind that,” said Cooper Quintin, a technologist at the advocacy group Electronic Frontier Foundation.
“But these things always end up rolling downhill. Maybe a state attorney general one day decides, hey, maybe I can use this to catch people having an abortion,” Quintin added. “Even if you trust the U.S. right now to use this, you might not trust a new administration to use it in a way you deem ethical.”
Cloudflare is committed to providing our customers with industry-leading network security solutions. At the same time, we recognize that establishing robust security measures involves identifying potential threats by using processes that may involve scrutinizing sensitive or personal data, which in turn can pose a risk to privacy. As a result, we work hard to balance privacy and security by building privacy-first security solutions that we offer to our customers and use for our own network.
In this post, we’ll walk through how we deployed Cloudflare products like Access and our Zero Trust Agent in a privacy-focused way for employees who use the Cloudflare network. Even though global legal regimes generally afford employees a lower level of privacy protection on corporate networks, we work hard to make sure our employees understand their privacy choices because Cloudflare has a strong culture and history of respecting and furthering user privacy on the Internet. We’ve found that many of our customers feel similarly about ensuring that they are protecting privacy while also securing their networks.
So how do we balance our commitment to privacy with ensuring the security of our internal corporate environment using Cloudflare products and services? We start with the basics: We only retain the minimum amount of data needed, we de-identify personal data where we can, we communicate transparently with employees about the security measures we have in place on corporate systems and their privacy choices, and we retain necessary information for the shortest time period needed.
How we secure Cloudflare using Cloudflare
We take a comprehensive approach to securing our globally distributed hybrid workforce with both organizational controls and technological solutions. Our organizational approach includes a number of measures, such as a company-wide Acceptable Use Policy, employee privacy notices tailored by jurisdiction, required annual and new-hire privacy and security trainings, role-based access controls (RBAC), and least privilege principles. These organizational controls allow us to communicate expectations for both the company and the employees that we can implement with technological controls and that we enforce through logging and other mechanisms.
Our technological controls are rooted in Zero Trust best practices and start with a focus on our Cloudflare One services to secure our workforce as described below.
Securing access to applications
Cloudflare secures access to self-hosted and SaaS applications for our workforce, whether remote or in-office, using our own Zero Trust Network Access (ZTNA) service, Cloudflare Access, to verify identity, enforce multi-factor authentication with security keys, and evaluate device posture using the Zero Trust client for every request. This approach evolved over several years and has enabled Cloudflare to more effectively protect our growing workforce.
As we have evolved our hybrid work and office configurations, our security teams have benefited from additional controls and visibility for forward-proxied Internet traffic, including:
Granular HTTP controls: Our security teams inspect HTTPS traffic to block access to specific websites identified as malicious by our security team, conduct antivirus scanning, and apply identity-aware browsing policies.
Selectively isolating Internet browsing: With remote browser isolated (RBI) sessions, all web code is run on Cloudflare’s network far from local devices, insulating users from any untrusted and malicious content. Today, Cloudflare isolates social media, news outlets, personal email, and other potentially risky Internet categories, and we have set up feedback loops for our employees to help us fine-tune these categories.
Geography-based logging: Seeing where outbound requests originate helps our security teams understand the geographic distribution of our workforce, including our presence in high-risk areas.
Data Loss Prevention: To keep sensitive data inside our corporate network, this tool allows us to identify data we’ve flagged as sensitive in outbound HTTP/S traffic and prevent it from leaving the network.
Cloud Access Security Broker: This tool allows us to monitor our SaaS apps for misconfigurations and sensitive data that is potentially exposed or shared too broadly.
Protecting inboxes with cloud email security
Additionally, we have deployed our Cloud Email Security solution to protect our workforce from increased phishing and business email compromise attacks that we have not only seen directed against our employees, but that are plaguing organizations globally. One key feature we use is email link isolation, which uses RBI and email security functionality to open potentially suspicious links in an isolated browser. This allows us to be slightly more relaxed with blocking suspicious links without compromising security. This is a big win for productivity for our employees and the security team, as both sets of employees aren’t having to deal with large volumes of false positives.
The very nature of these powerful security technologies Cloudflare has created and deployed underscores the responsibility we have to use privacy-first principles in handling this data, and to recognize that the data should be respected and protected at all times.
The journey to respecting privacy starts with the products themselves. We develop products that have privacy controls built in at their foundation. To achieve this, our product teams work closely with Cloudflare’s product and privacy counsels to practice privacy by design. A great example of this collaboration is the ability to manage personally identifiable information (PII) in the Secure Web Gateway logs. You can choose to exclude PII from Gateway logs entirely or redact PII from the logs and gain granular control over access to PII with the Zero Trust PII Role.
In addition to building privacy-first security products, we are also committed to communicating transparently with Cloudflare employees about how these security products work and what they can – and can’t – see about traffic on our internal systems. This empowers employees to see themselves as part of the security solution, rather than set up an “us vs. them” mentality around employee use of company systems.
For example, while our employee privacy policies and our Acceptable Use Policy provide broad notice to our employees about what happens to data when they use the company’s systems, we thought it was important to provide even more detail. As a result, our security team collaborated with our privacy team to create an internal wiki page that plainly explains the data our security tools collect and why. We also describe the privacy choices available to our employees. This is particularly important for the “bring your own device” (BYOD) employees who have opted for the convenience of using their personal mobile device for work. BYOD employees must install endpoint management (provided by a third party) and Cloudflare’s Zero trust client on their devices if they want to access Cloudflare systems. We described clearly to our employees what this means about what traffic on their devices can be seen by Cloudflare teams, and we explained how they can take steps to protect their privacy when they are using their devices for purely personal purposes.
For the teams that develop for and support our Zero Trust services, we ensure that data is available only on a strict, need-to-know basis and is restricted to Cloudflare team members that require access as an essential part of their job. The set of people with access are required to take training that reminds them of their responsibility to respect this data and provides them with best practices for handling sensitive data. Additionally, to ensure we have full auditability, we log all the queries run against this database and by whom they are run.
Cloudflare has also made it easy for our employees to express any concerns they may have about how their data is handled or what it is used for. We have mechanisms in place that allow employees to ask questions or express concerns about the use of Zero Trust Security on Cloudflare’s network.
In addition, we make it easy for employees to reach out directly to the leaders responsible for these tools. All of these efforts have helped our employees better understand what information we collect and why. This has helped to expand our strong foundation for security and privacy at Cloudflare.
Encouraging privacy-first security for all
We believe firmly that great security is critical for ensuring data privacy, and that privacy and security can co-exist harmoniously. We also know that it is possible to secure a corporate network in a way that respects the employees using those systems.
For anyone looking to secure a corporate network, we encourage focusing on network security products and solutions that build in personal data protections, like our Zero Trust suite of products. If you are curious to explore how to implement these Cloudflare services in your own organizations, request a consultation here.
We also urge organizations to make sure they communicate clearly with their users. In addition to making sure company policies are transparent and accessible, it is important to help employees understand their privacy choices. Under the laws of almost every jurisdiction globally, individuals have a lower level of privacy on a company device or a company’s systems than they do on their own personal accounts or devices, so it’s important to communicate clearly to help employees understand the difference. If an organization has privacy champions, works councils, or other employee representation groups, it is critical to communicate early and often with these groups to help employees understand what controls they can exercise over their data.
In July, 2023, we announced that Zaraz was transitioning out of beta and becoming available to all Cloudflare users. Zaraz helps users manage and optimize the ever-growing number of third-party tools on their websites — analytics, marketing pixels, chatbots, and more — without compromising on speed, privacy, or security. Soon after the announcement went online, we received feedback from users who were concerned about the new pricing system. We discovered that in some scenarios the proposed pricing could cause high charges, which was not the intention, and so we promised to look into it. Since then, we have iterated over different pricing options, talked with customers of different sizes, and finally reached a new pricing system that we believe is affordable, predictable, and simple. The new pricing for Zaraz will take effect on April 15, 2024, and is described below.
Introducing Zaraz Events
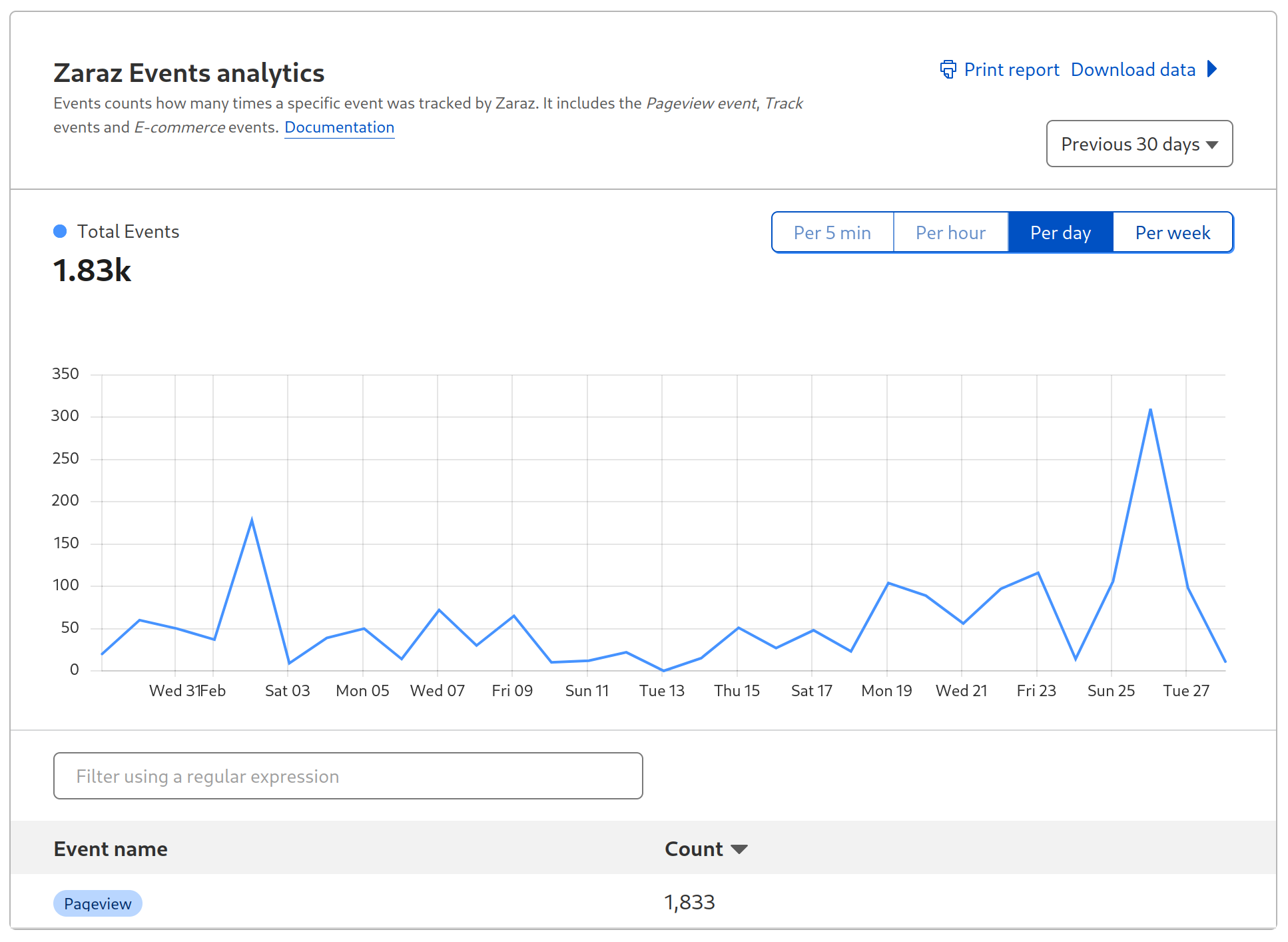
One of the biggest changes we made was changing the metric we used for pricing Zaraz. One Zaraz Event is an event you’re sending to Zaraz, whether that’s a pageview, a zaraz.track event, or similar. You can easily see the total number of Zaraz Events you’re currently using under the Monitoring section in the Cloudflare Zaraz Dashboard. Every Cloudflare account can use 1,000,000 Zaraz Events completely for free, every month.
The Zaraz Monitoring page shows exactly how many Zaraz Events your website is using
We believe that Zaraz Events are a better representation of the usage of Zaraz. As the web progresses and as Single-Page-Applications are becoming more and more popular, the definition of a “pageview”, which was used for the old pricing system, is becoming more and more vague. Zaraz Events are agnostic to different tech stacks, and work the same when using the Zaraz HTTP API. It’s a simpler metric that should better reflect the way Zaraz is used.
Predictable costs for high volume websites
With the new Zaraz pricing model, every Cloudflare account gets 1,000,000 Zaraz Events per month for free. If your account needs more than that, every additional 1,000,000 Zaraz Events are only $5 USD, with volume discounting available for Enterprise accounts. Compared with other third-party managers and tag management software, this new pricing model makes Zaraz an affordable and user-friendly solution for server-side loading of tools and tags.
Available for all
We also decided that all Zaraz features should be available for everyone. We want users to make the most of Zaraz, no matter how big or small their website is. This means that advanced features like making custom HTTP requests, using the Consent Management API, loading custom Managed Components, configuring custom endpoints, using the Preview & Publish Workflow, and even using the Zaraz Ecommerce features are now available on all plans, from Free to Enterprise.
Try it out
We’re announcing this new affordable price for Zaraz while retaining all the features that make it the perfect solution for managing third-party tools on your website. Zaraz is a one-click installation that requires no server, and it’s lightning fast thanks to Cloudflare’s network, which is within 50 milliseconds of approximately 95% of the Internet-connected population. Zaraz is extremely extensible using the Open Source format of Managed Components, allowing you to change tools and create your own, and it’s transparent about what information is shared with tools on your website, allowing you to control and improve the privacy of your website visitors.
Zaraz recently completed the migration of all tools to Managed Components. This makes tools on your website more like apps on your phone, allowing you to granularly decide what permissions to grant tools. For example, it allows you to prevent a tool from making client-side network requests or storing cookies. With the Zaraz Context Enricher you can create custom data manipulation processes in a Cloudflare Worker, and do things like attach extra information to payloads from your internal CRM, or automatically remove and mask personally-identifiable information (PII) like email addresses before it reaches your providers.
We would like to thank all the users that provided us with their feedback. We acknowledge that the previous pricing might have caused some to think twice about choosing Zaraz, and we hope that this will encourage them to reconsider. Cloudflare Zaraz is a tool that is meant first and foremost to serve the people building websites on the Internet, and we thank everyone for sharing their feedback to help us get to a better product in the end.
The new pricing for Zaraz will take effect starting April 15, 2024.
Consumer Reports is reporting that Facebook has built a massive surveillance network:
Using a panel of 709 volunteers who shared archives of their Facebook data, Consumer Reports found that a total of 186,892 companies sent data about them to the social network. On average, each participant in the study had their data sent to Facebook by 2,230 companies. That number varied significantly, with some panelists’ data listing over 7,000 companies providing their data. The Markup helped Consumer Reports recruit participants for the study. Participants downloaded an archive of the previous three years of their data from their Facebook settings, then provided it to Consumer Reports.
This isn’t data about your use of Facebook. This data about your interactions with other companies, all of which is correlated and analyzed by Facebook. It constantly amazes me that we willingly allow these monopoly companies that kind of surveillance power.
Here’s the Consumer Reports study. It includes policy recommendations:
Many consumers will rightly be concerned about the extent to which their activity is tracked by Facebook and other companies, and may want to take action to counteract consistent surveillance. Based on our analysis of the sample data, consumers need interventions that will:
Reduce the overall amount of tracking.
Improve the ability for consumers to take advantage of their right to opt out under state privacy laws.
Empower social media platform users and researchers to review who and what exactly is being advertised on Facebook.
Improve the transparency of Facebook’s existing tools.
In October, the Consumer Financial Protection Bureau (CFPB) proposed a set of rules that if implemented would transform how financial institutions handle personal data about their customers. The rules put control of that data back in the hands of ordinary Americans, while at the same time undermining the data broker economy and increasing customer choice and competition. Beyond these economic effects, the rules have important data security benefits.
The CFPB’s rules align with a key security idea: the decoupling principle. By separating which companies see what parts of our data, and in what contexts, we can gain control over data about ourselves (improving privacy) and harden cloud infrastructure against hacks (improving security). Officials at the CFPB have described the new rules as an attempt to accelerate a shift toward “open banking,” and after an initial comment period on the new rules closed late last year, Rohit Chopra, the CFPB’s director, has said he would like to see the rule finalized by this fall.
Right now, uncountably many data brokers keep tabs on your buying habits. When you purchase something with a credit card, that transaction is shared with unknown third parties. When you get a car loan or a house mortgage, that information, along with your Social Security number and other sensitive data, is also shared with unknown third parties. You have no choice in the matter. The companies will freely tell you this in their disclaimers about personal information sharing: that you cannot opt-out of data sharing with “affiliate” companies. Since most of us can’t reasonably avoid getting a loan or using a credit card, we’re forced to share our data. Worse still, you don’t have a right to even see your data or vet it for accuracy, let alone limit its spread.
The CFPB’s simple and practical rules would fix this. The rules would ensure people can obtain their own financial data at no cost, control who it’s shared with and choose who they do business with in the financial industry. This would change the economics of consumer finance and the illicit data economy that exists today.
The best way for financial services firms to meet the CFPB’s rules would be to apply the decoupling principle broadly. Data is a toxic asset, and in the long run they’ll find that it’s better to not be sitting on a mountain of poorly secured financial data. Deleting the data is better for their users and reduces the chance they’ll incur expenses from a ransomware attack or breach settlement. As it stands, the collection and sale of consumer data is too lucrative for companies to say no to participating in the data broker economy, and the CFPB’s rules may help eliminate the incentive for companies to buy and sell these toxic assets. Moreover, in a free market for financial services, users will have the option to choose more responsible companies that also may be less expensive, thanks to savings from improved security.
Credit agencies and data brokers currently make money both from lenders requesting reports and from consumers requesting their data and seeking services that protect against data misuse. The CFPB’s new rules—and the technical changes necessary to comply with them—would eliminate many of those income streams. These companies have many roles, some of which we want and some we don’t, but as consumers we don’t have any choice in whether we participate in the buying and selling of our data. Giving people rights to their financial information would reduce the job of credit agencies to their core function: assessing risk of borrowers.
A free and properly regulated market for financial services also means choice and competition, something the industry is sorely in need of. Equifax, Transunion and Experian make up a longstanding oligopoly for credit reporting. Despite being responsible for one of the biggest data breaches of all time in 2017, the credit bureau Equifax is still around—illustrating that the oligopolistic nature of this market means that companies face few consequences for misbehavior.
On the banking side, the steady consolidation of the banking sector has resulted in a small number of very large banks holding most deposits and thus most financial data. Behind the scenes, a variety of financial data clearinghouses—companies most of us have never heard of—get breached all the time, losing our personal data to scammers, identity thieves and foreign governments.
The CFPB’s new rules would require institutions that deal with financial data to provide simple but essential functions to consumers that stand to deliver security benefits. This would include the use of application programming interfaces (APIs) for software, eliminating the barrier to interoperability presented by today’s baroque, non-standard and non-programmatic interfaces to access data. Each such interface would allow for interoperability and potential competition. The CFPB notes that some companies have tried to claim that their current systems provide security by being difficult to use. As security experts, we disagree: Such aging financial systems are notoriously insecure and simply rely upon security through obscurity.
Furthermore, greater standardization and openness in financial data with mechanisms for consumer privacy and control means fewer gatekeepers. The CFPB notes that a small number of data aggregators have emerged by virtue of the complexity and opaqueness of today’s systems. These aggregators provide little economic value to the country as a whole; they extract value from us all while hindering competition and dynamism. The few new entrants in this space have realized how valuable it is for them to present standard APIs for these systems while managing the ugly plumbing behind the scenes.
In addition, by eliminating the opacity of the current financial data ecosystem, the CFPB is able to add a new requirement of data traceability and certification: Companies can only use consumers’ data when absolutely necessary for providing a service the consumer wants. This would be another big win for consumer financial data privacy.
It might seem surprising that a set of rules designed to improve competition also improves security and privacy, but it shouldn’t. When companies can make business decisions without worrying about losing customers, security and privacy always suffer. Centralization of data also means centralization of control and economic power and a decline of competition.
If this rule is implemented it will represent an important, overdue step to improve competition, privacy and security. But there’s more that can and needs to be done. In time, we hope to see more regulatory frameworks that give consumers greater control of their data and increased adoption of the technology and architecture of decoupling to secure all of our personal data, wherever it may be.
This essay was written with Barath Raghavan, and was originally published in Cyberscoop.
Enabling anonymous access to the web with privacy-preserving cryptography
The challenge of telling humans and bots apart is almost as old as the web itself. From online ticket vendors to dating apps, to ecommerce and finance — there are many legitimate reasons why you’d want to know if it’s a person or a machine knocking on the front door of your website.
Unfortunately, the tools for the web have traditionally been clunky and sometimes involved a bad user experience. None more so than the CAPTCHA — an irksome solution that humanity wastes a staggering amount of time on. A more subtle but intrusive approach is IP tracking, which uses IP addresses to identify and take action on suspicious traffic, but that too can come with unforeseen consequences.
And yet, the problem of distinguishing legitimate human requests from automated bots remains as vital as ever. This is why for years Cloudflare has invested in the Privacy Pass protocol — a novel approach to establishing a user’s identity by relying on cryptography, rather than crude puzzles — all while providing a streamlined, privacy-preserving, and often frictionless experience to end users.
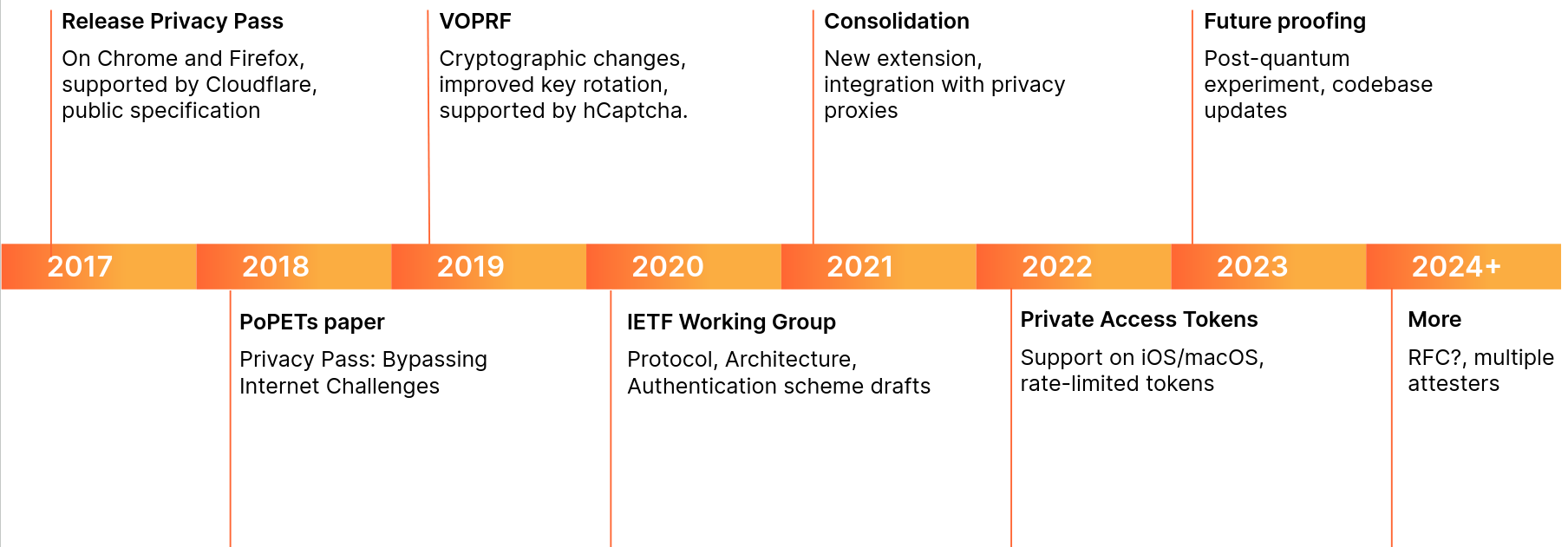
Cloudflare began supporting Privacy Pass in 2017, with the release of browser extensions for Chrome and Firefox. Web admins with their sites on Cloudflare would have Privacy Pass enabled in the Cloudflare Dash; users who installed the extension in their browsers would see fewer CAPTCHAs on websites they visited that had Privacy Pass enabled.
Since then, Cloudflare stopped issuing CAPTCHAs, and Privacy Pass has come a long way. Apple uses a version of Privacy Pass for its Private Access Tokens system which works in tandem with a device’s secure enclave to attest to a user’s humanity. And Cloudflare uses Privacy Pass as an important signal in our Web Application Firewall and Bot Management products — which means millions of websites natively offer Privacy Pass.
In this post, we explore the latest changes to Privacy Pass protocol. We are also excited to introduce a public implementation of the latest IETF draft of the Privacy Pass protocol — including a set of open-source templates that can be used to implement Privacy Pass Origins, Issuers, and Attesters. These are based on Cloudflare Workers, and are the easiest way to get started with a new deployment of Privacy Pass.
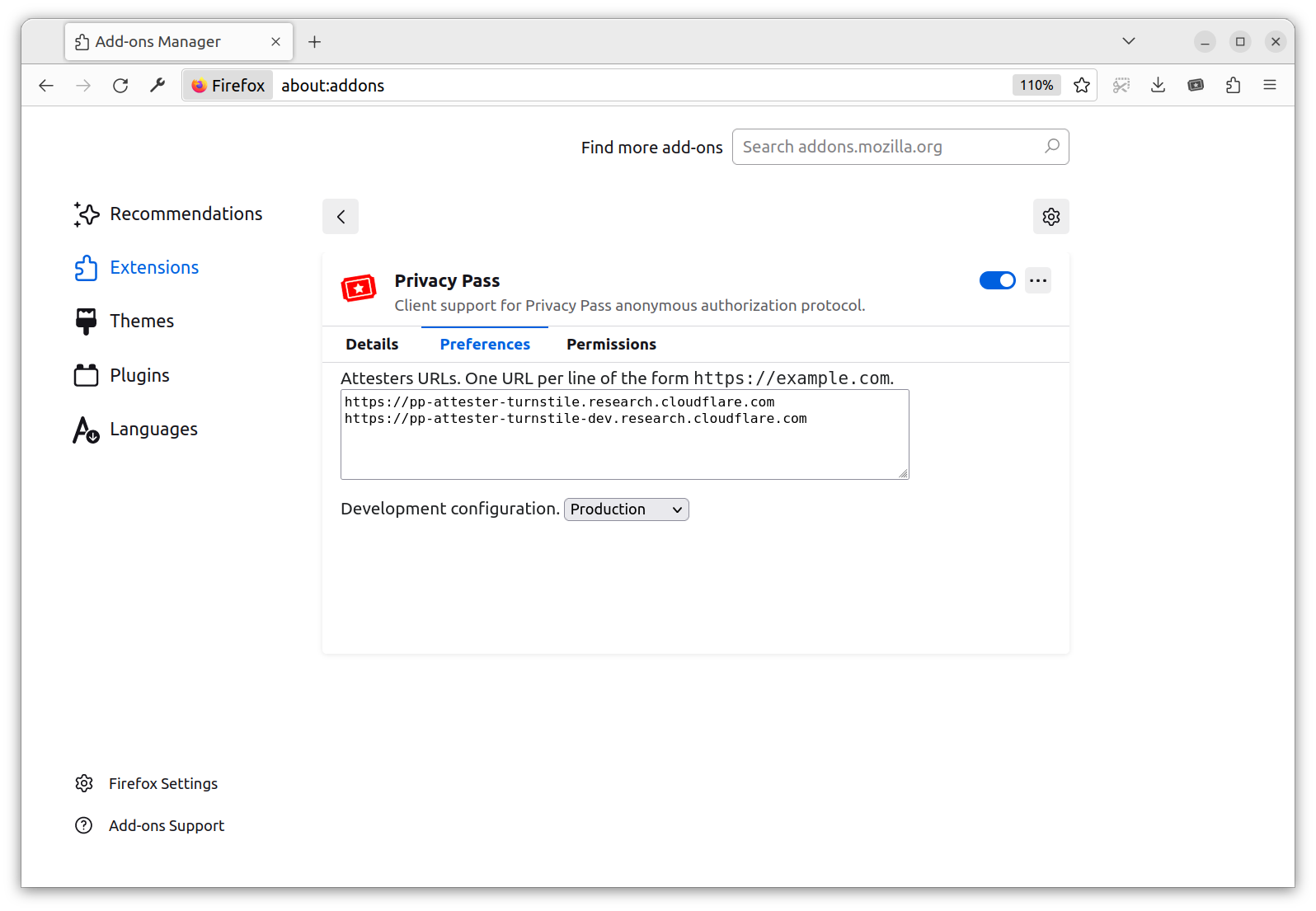
To complement the updated implementations, we are releasing a new version of our Privacy Pass browser extensions (Firefox, Chrome), which are rolling out with the name: Silk – Privacy Pass Client. Users of these extensions can expect to see fewer bot-checks around the web, and will be contributing to research about privacy preserving signals via a set of trusted attesters, which can be configured in the extension’s settings panel.
Finally, we will discuss how Privacy Pass can be used for an array of scenarios beyond differentiating bot from human traffic.
Notice to our users
If you use the Privacy Pass API that controls Privacy Pass configuration on Cloudflare, you can remove these calls. This API is no longer needed since Privacy Pass is now included by default in our Challenge Platform. Out of an abundance of caution for our customers, we are doing a four-month deprecation notice.
If you have the Privacy Pass extension installed, it should automatically update to Silk – Privacy Pass Client (Firefox, Chrome) over the next few days. We have renamed it to keep the distinction clear between the protocol itself and a client of the protocol.
Brief history
In the last decade, we’ve seen the rise of protocols with privacy at their core, including Oblivious HTTP (OHTTP), Distributed aggregation protocol (DAP), and MASQUE. These protocols improve privacy when browsing and interacting with services online. By protecting users’ privacy, these protocols also ask origins and website owners to revise their expectations around the data they can glean from user traffic. This might lead them to reconsider existing assumptions and mitigations around suspicious traffic, such as IP filtering, which often has unintended consequences.
In 2017, Cloudflare announced support for Privacy Pass. At launch, this meant improving content accessibility for web users who would see a lot of interstitial pages (such as CAPTCHAs) when browsing websites protected by Cloudflare. Privacy Pass tokens provide a signal about the user’s capabilities to website owners while protecting their privacy by ensuring each token redemption is unlinkable to its issuance context. Since then, the technology has turned into a fully fledged protocol used by millions thanks to academic and industry effort. The existing browser extension accounts for hundreds of thousands of downloads. During the same time, Cloudflare has dramatically evolved the way it allows customers to challenge their visitors, being more flexible about the signals it receives, and moving away from CAPTCHA as a binary legitimacy signal.
Deployments of this research have led to a broadening of use cases, opening the door to different kinds of attestation. An attestation is a cryptographically-signed data point supporting facts. This can include a signed token indicating that the user has successfully solved a CAPTCHA, having a user’s hardware attest it’s untampered, or a piece of data that an attester can verify against another data source.
For example, in 2022, Apple hardware devices began to offer Privacy Pass tokens to websites who wanted to reduce how often they show CAPTCHAs, by using the hardware itself as an attestation factor. Before showing images of buses and fire hydrants to users, CAPTCHA providers can request a Private Access Token (PAT). This native support does not require installing extensions, or any user action to benefit from a smoother and more private web browsing experience.
Below is a brief overview of changes to the protocol we participated in:
The timeline presents cryptographic changes, community inputs, and industry collaborations. These changes helped shape better standards for the web, such as VOPRF (RFC 9497), or RSA Blind Signatures (RFC 9474). In the next sections, we dive in the Privacy Pass protocol to understand its ins and outs.
Anonymous credentials in real life
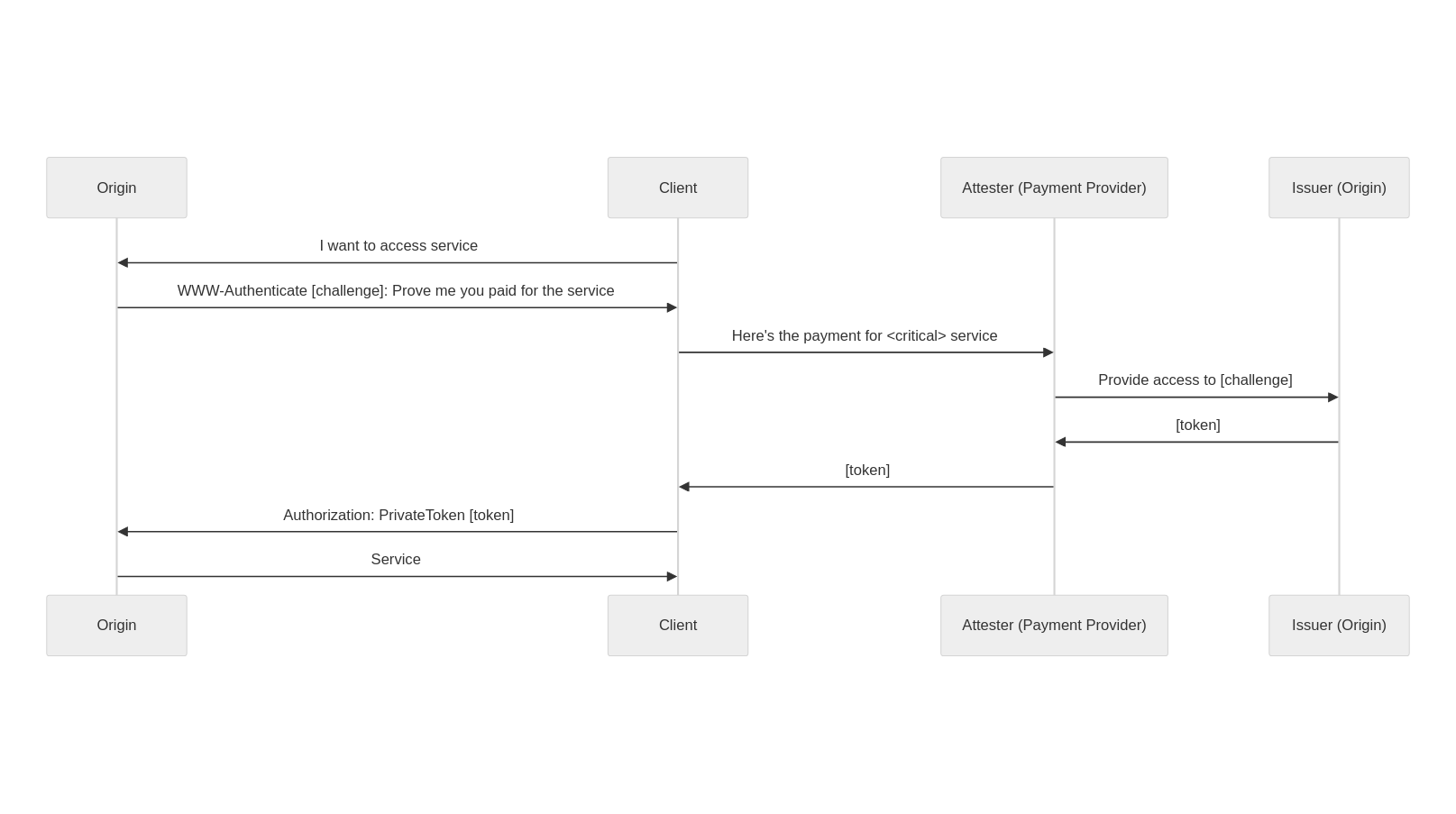
Before explaining the protocol in more depth, let’s use an analogy. You are at a music festival. You bought your ticket online with a student discount. When you arrive at the gates, an agent scans your ticket, checks your student status, and gives you a yellow wristband and two drink tickets.
During the festival, you go in and out by showing your wristband. When a friend asks you to grab a drink, you pay with your tickets. One for your drink and one for your friend. You give your tickets to the bartender, they check the tickets, and give you a drink. The characteristics that make this interaction private is that the drinks tickets cannot be traced back to you or your payment method, but they can be verified as having been unused and valid for purchase of a drink.
In the web use case, the Internet is a festival. When you arrive at the gates of a website, an agent scans your request, and gives you a session cookie as well as two Privacy Pass tokens. They could have given you just one token, or more than two, but in our example ‘two tokens’ is the given website’s policy. You can use these tokens to attest your humanity, to authenticate on certain websites, or even to confirm the legitimacy of your hardware.
Now, you might wonder if this is a technique we have been using for years, why do we need fancy cryptography and standardization efforts? Well, unlike at a real-world music festival where most people don’t carry around photocopiers, on the Internet it is pretty easy to copy tokens. For instance, how do we stop people using a token twice? We could put a unique number on each token, and check it is not spent twice, but that would allow the gate attendant to tell the bartender which numbers were linked to which person. So, we need cryptography.
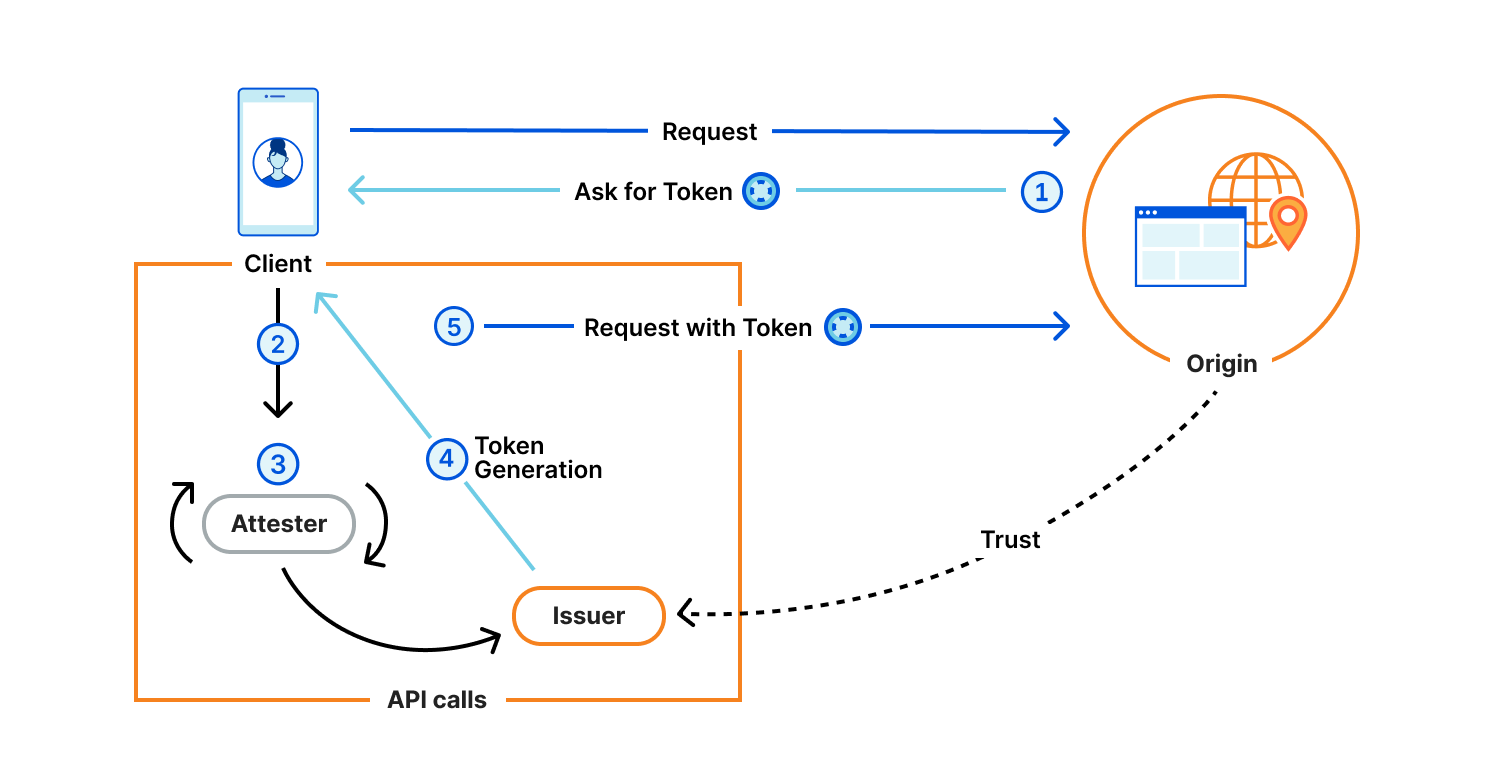
When another website presents a challenge to you, you provide your Privacy Pass token and are then allowed to view a gallery of beautiful cat pictures. The difference with the festival is this challenge might be interactive, which would be similar to the bartender giving you a numbered ticket which would have to be signed by the agent before getting a drink. The website owner can verify that the token is valid but has no way of tracing or connecting the user back to the action that provided them with the Privacy Pass tokens. With Privacy Pass terminology, you are a Client, the website is an Origin, the agent is an Attester, and the bar an Issuer. The next section goes through these in more detail.
Privacy Pass protocol
Privacy Pass specifies an extensible protocol for creating and redeeming anonymous and transferable tokens. In fact, Apple has their own implementation with Private Access Tokens (PAT), and later we will describe another implementation with the Silk browser extension. Given PAT was the first to implement the IETF defined protocol, Privacy Pass is sometimes referred to as PAT in the literature.
The protocol is generic, and defines four components:
Client: Web user agent with a Privacy Pass enabled browser. This could be your Apple device with PAT, or your web browser with the Silk extension installed. Typically, this is the actor who is requesting content and is asked to share some attribute of themselves.
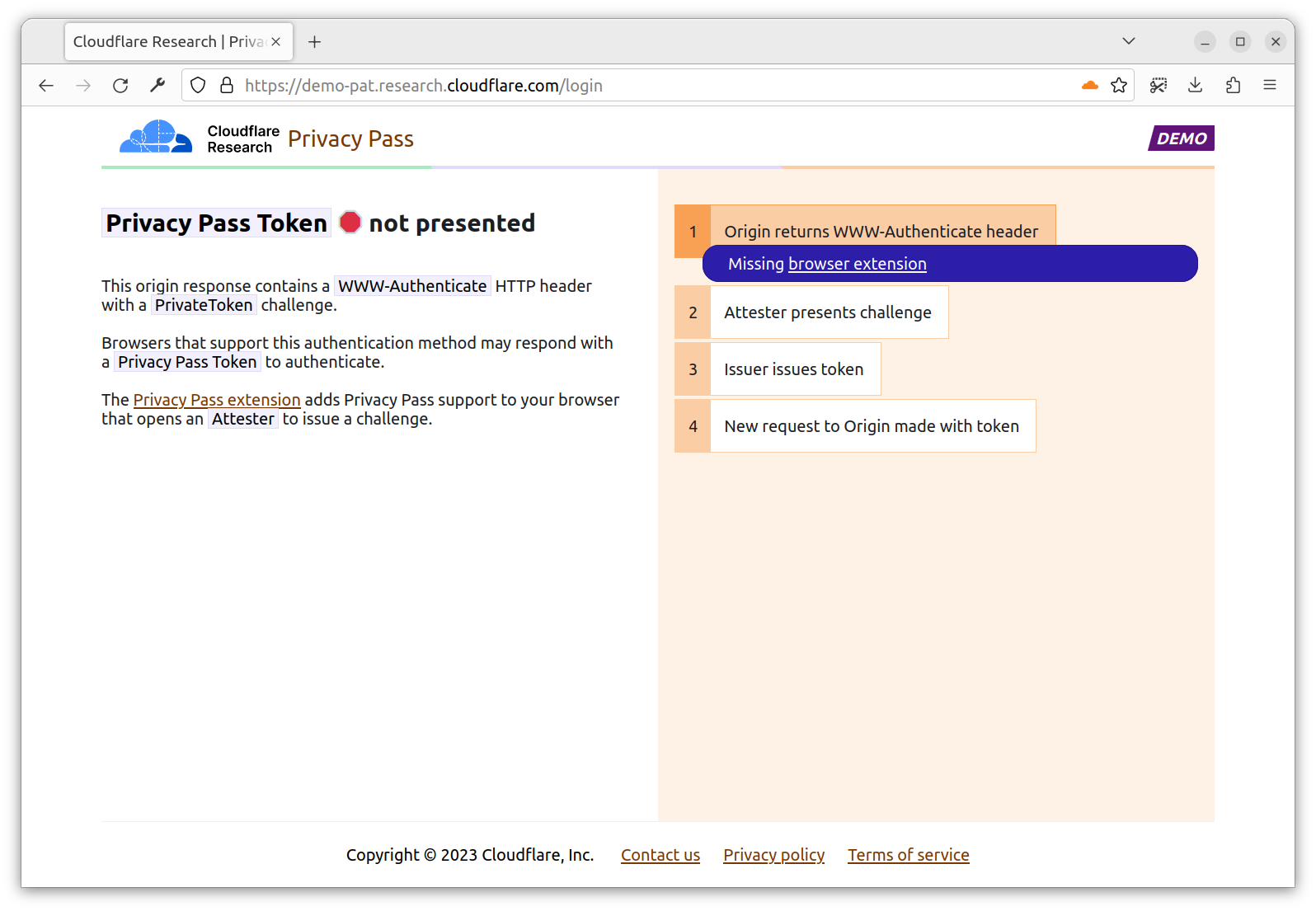
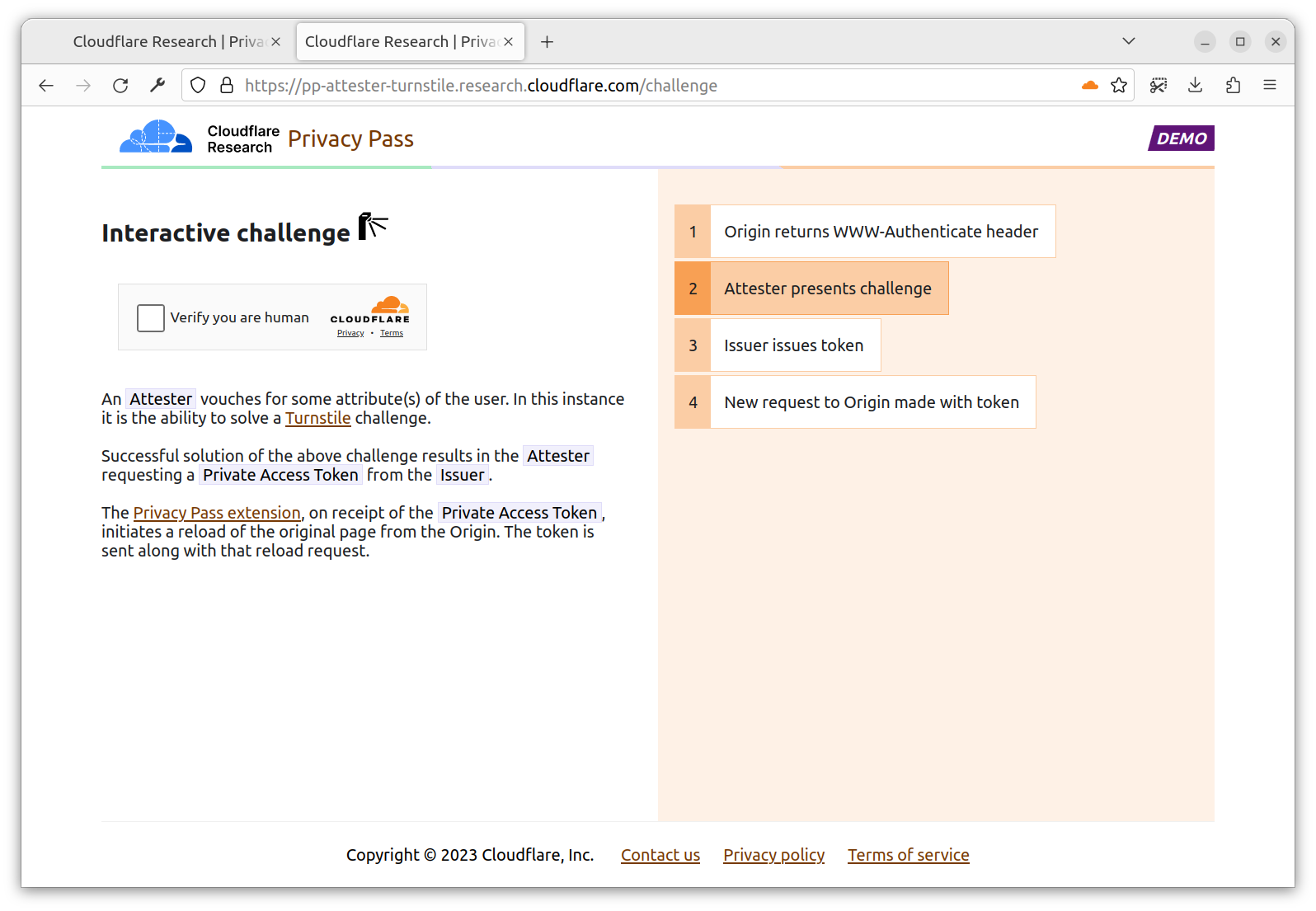
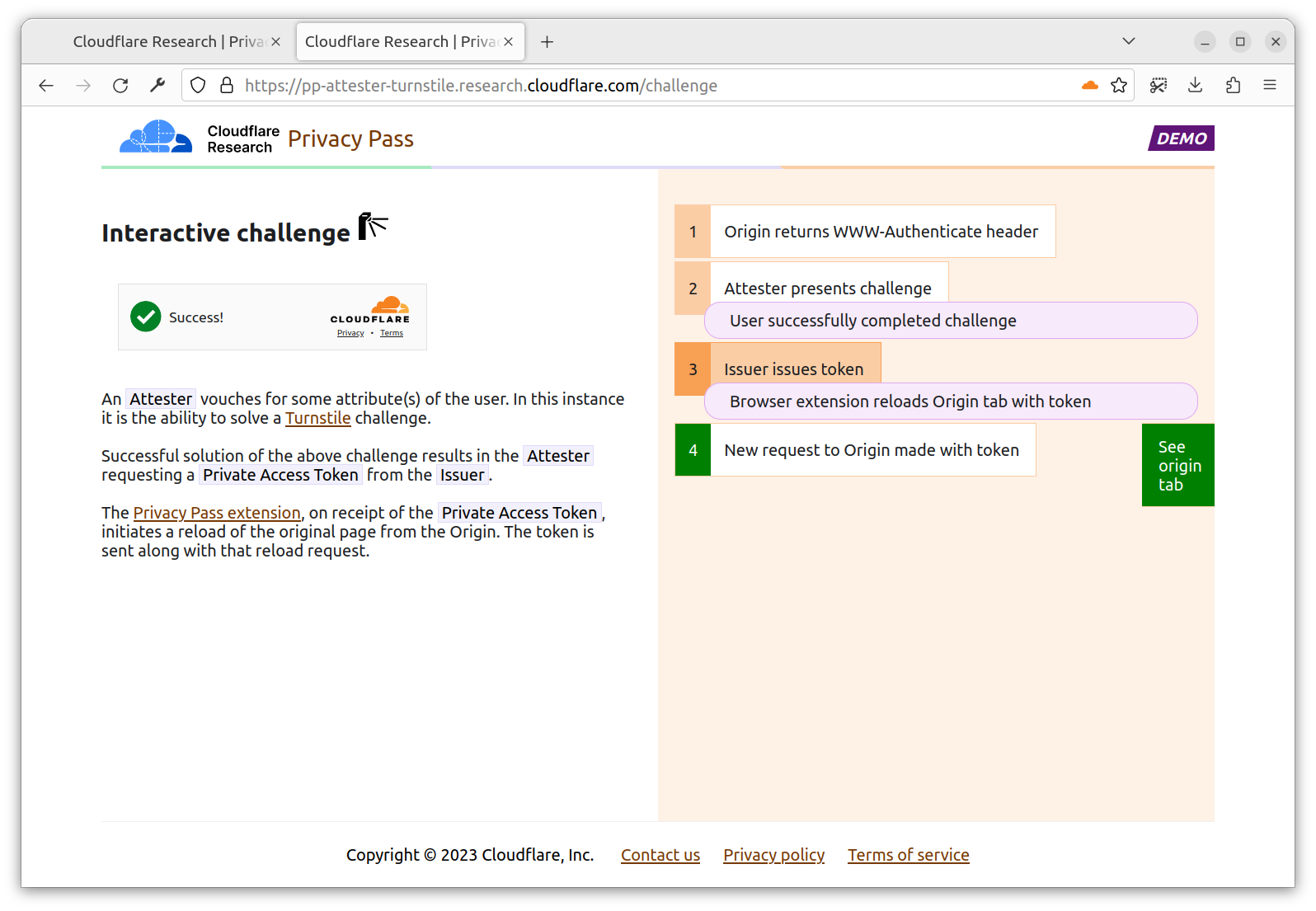
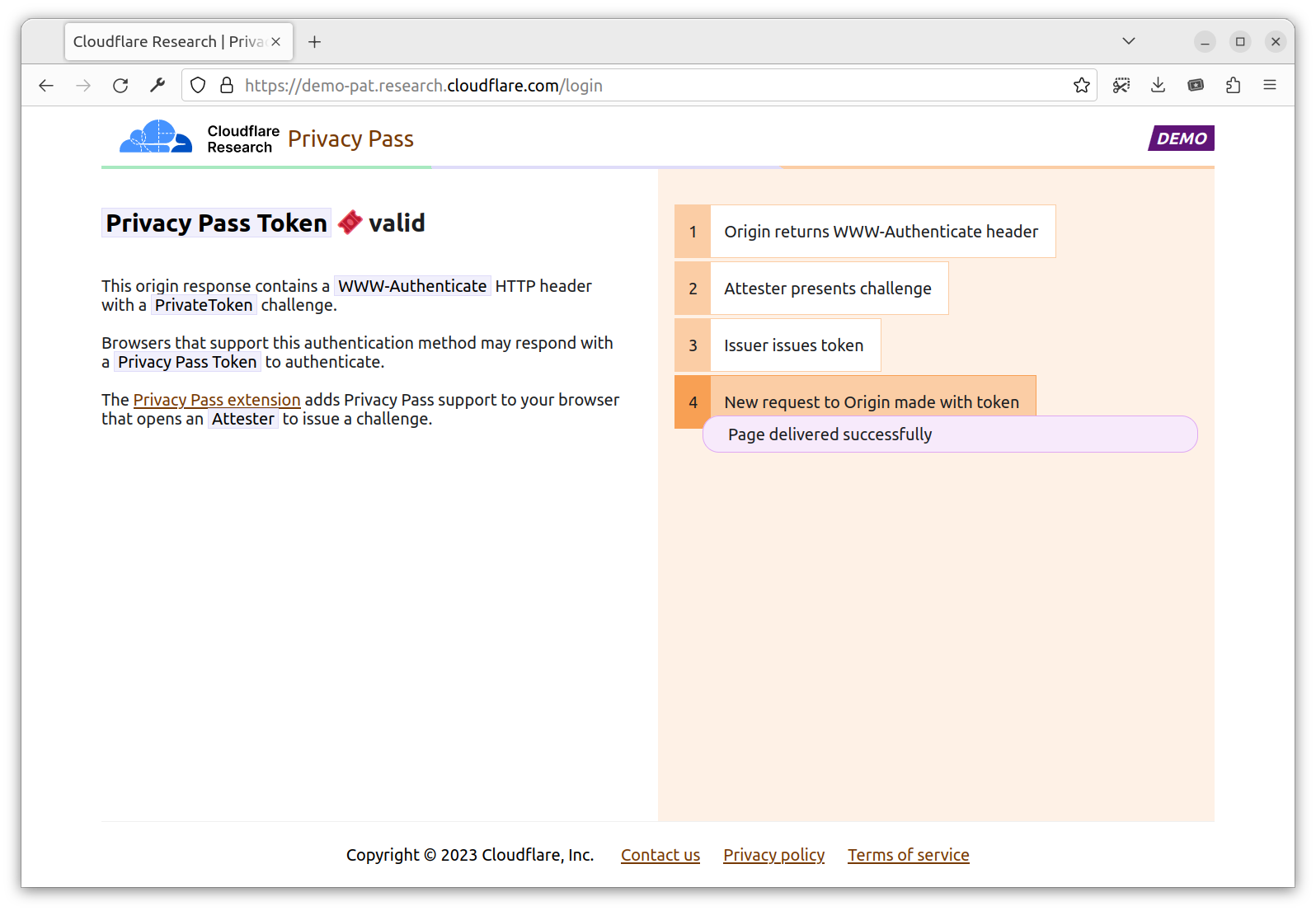
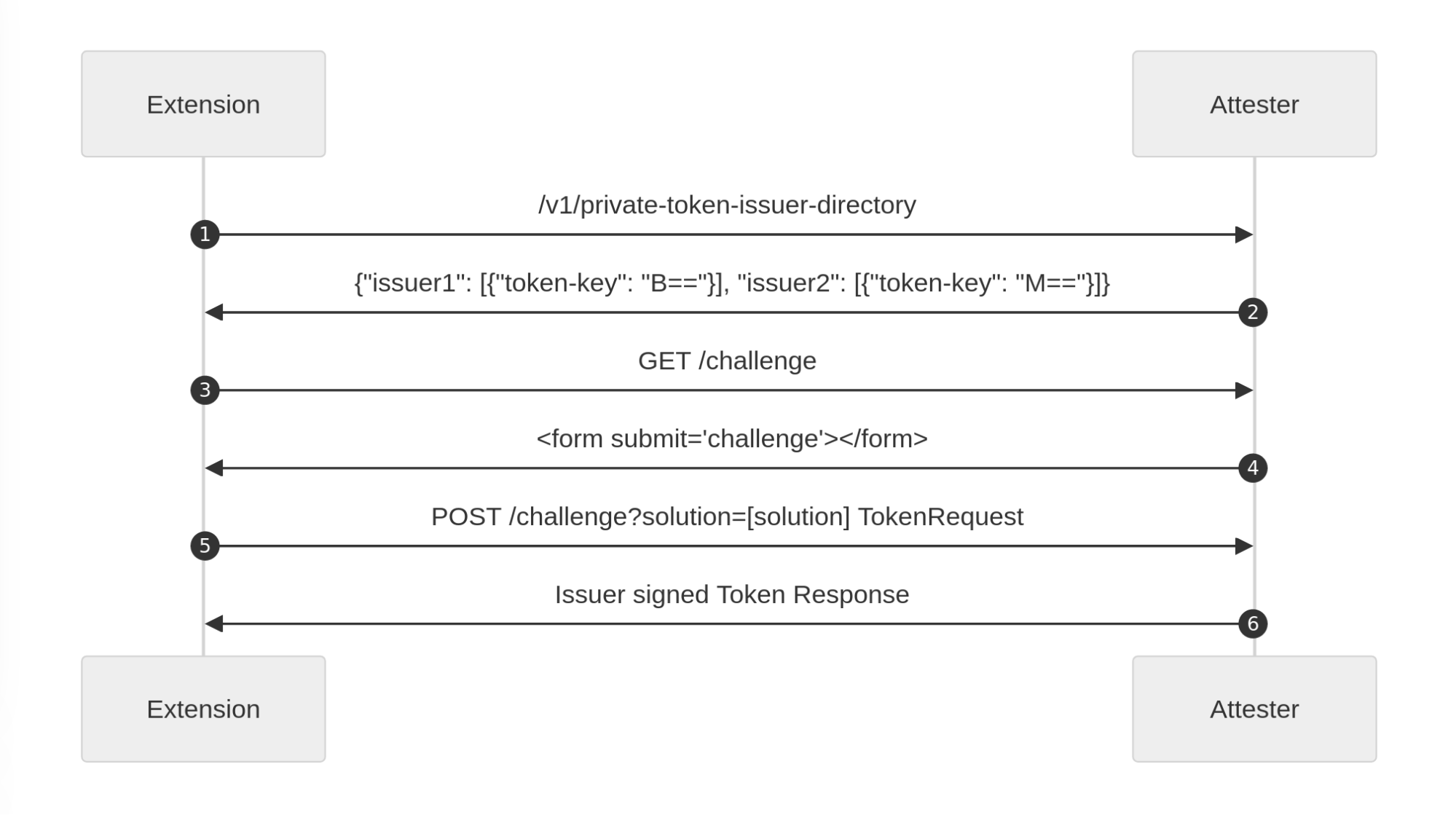
Origin: Serves content requested by the Client. The Origin trusts one or more Issuers, and presents Privacy Pass challenges to the Client. For instance, Cloudflare Managed Challenge is a Privacy Pass origin serving two Privacy Pass challenges: one for Apple PAT Issuer, one for Cloudflare Research Issuer.
Issuer: Signs Privacy Pass tokens upon request from a trusted party, either an Attester or a Client depending on the deployment model. Different Issuers have their own set of trusted parties, depending on the security level they are looking for, as well as their privacy considerations. An Issuer validating device integrity should use different methods that vouch for this attribute to acknowledge the diversity of Client configurations.
Attester: Verifies an attribute of the Client and when satisfied requests a signed Privacy Pass token from the Issuer to pass back to the Client. Before vouching for the Client, an Attester may ask the Client to complete a specific task. This task could be a CAPTCHA, a location check, or age verification or some other check that will result in a single binary result. The Privacy Pass token will then share this one-bit of information in an unlinkable manner.
They interact as illustrated below.
Let’s dive into what’s really happening with an example. The User wants to access an Origin, say store.example.com. This website has suffered attacks or abuse in the past, and the site is using Privacy Pass to help avoid these going forward. To that end, the Origin returns an authentication request to the Client: WWW-Authenticate: PrivateToken challenge="A==",token-key="B==". In this way, the Origin signals that it accepts tokens from the Issuer with public key “B==” to satisfy the challenge. That Issuer in turn trusts reputable Attesters to vouch for the Client not being an attacker by means of the presence of a cookie, CAPTCHA, Turnstile, or CAP challenge for example. For accessibility reasons for our example, let us say that the Client likely prefers the Turnstile method. The User’s browser prompts them to solve a Turnstile challenge. On success, it contacts the Issuer “B==” with that solution, and then replays the initial requests to store.example.com, this time sending along the token header Authorization: PrivateToken token="C==", which the Origin accepts and returns your desired content to the Client. And that’s it.
We’ve described the Privacy Pass authentication protocol. While Basic authentication (RFC 7671) asks you for a username and a password, the PrivateToken authentication scheme allows the browser to be more flexible on the type of check, while retaining privacy. The Origin store.example.com does not know your attestation method, they just know you are reputable according to the token issuer. In the same spirit, the Issuer “B==” does not see your IP, nor the website you are visiting. This separation between issuance and redemption, also referred to as unlinkability, is what makes Privacy Pass private.
Demo time
To put the above in practice, let’s see how the protocol works with Silk, a browser extension providing Privacy Pass support. First, download the relevant Chrome or Firefox extension.
Then, head to https://demo-pat.research.cloudflare.com/login. The page returns a 401 Privacy Pass Token not presented. In fact, the origin expects you to perform a PrivateToken authentication. If you don’t have the extension installed, the flow stops here. If you have the extension installed, the extension is going to orchestrate the flow required to get you a token requested by the Origin.
With the extension installed, you are directed to a new tab https://pp-attester-turnstile.research.cloudflare.com/challenge. This is a page provided by an Attester able to deliver you a token signed by the Issuer request by the Origin. In this case, the Attester checks you’re able to solve a Turnstile challenge.
You click, and that’s it. The Turnstile challenge solution is sent to the Attester, which upon validation, sends back a token from the requested Issuer. This page appears for a very short time, as once the extension has the token, the challenge page is no longer needed.
The extension, now having a token requested by the Origin, sends your initial request for a second time, with an Authorization header containing a valid Issuer PrivateToken. Upon validation, the Origin allows you in with a 200 Privacy Pass Token valid!
If you want to check behind the scenes, you can right-click on the extension logo and go to the preference/options page. It contains a list of attesters trusted by the extension, one per line. You can add your own attestation method (API described below). This allows the Client to decide on their preferred attestation methods.
Privacy Pass protocol — extended
The Privacy Pass protocol is new and not a standard yet, which implies that it’s not uniformly supported on all platforms. To improve flexibility beyond the existing standard proposal, we are introducing two mechanisms: an API for Attesters, and a replay API for web clients. The API for attesters allows developers to build new attestation methods, which only need to provide their URL to interface with the Silk browser extension. The replay API for web clients is a mechanism to enable websites to cooperate with the extension to make PrivateToken authentication work on browsers with Chrome user agents.
Because more than one Attester may be supported on your machine, your Client needs to understand which Attester to use depending on the requested Issuer. As mentioned before, you as the Client do not communicate directly with the Issuer because you don’t necessarily know their relation with the attester, so you cannot retrieve its public key. To this end, the Attester API exposes all Issuers reachable by the said Attester via an endpoint: /v1/private-token-issuer-directory. This way, your client selects an appropriate Attester – one in relation with an Issuer that the Origin trusts, before triggering a validation.
In addition, we propose a replay API. Its goal is to allow clients to fetch a resource a second time if the first response presented a Privacy pass challenge. Some platforms do this automatically, like Silk on Firefox, but some don’t. That’s the case with the Silk Chrome extension for instance, which in its support of manifest v3 cannot block requests and only supports Basic authentication in the onAuthRequired extension event. The Privacy Pass Authentication scheme proposes the request to be sent once to get a challenge, and then a second time to get the actual resource. Between these requests to the Origin, the platform orchestrates the issuance of a token. To keep clients informed about the state of this process, we introduce a private-token-client-replay: UUID header alongside WWW-Authenticate. Using a platform defined endpoint, this UUID informs web clients of the current state of authentication: pending, fulfilled, not-found.
To learn more about how you can use these today, and to deploy your own attestation method, read on.
Note: All examples below are designed in JavaScript and targeted at Cloudflare Workers. Privacy Pass is also implemented in other languages and can be deployed with a configuration that suits your needs.
As an Origin – website owners, service providers
You are an online service that people critically rely upon (health or messaging for instance). You want to provide private payment options to users to maintain your users’ privacy. You only have one subscription tier at $10 per month. You have heard people are making privacy preserving apps, and want to use the latest version of Privacy Pass.
To access your service, users are required to prove they’ve paid for the service through a payment provider of their choosing (that you deem acceptable). This payment provider acknowledges the payment and requests a token for the user to access the service. As a sequence diagram, it looks as follows:
To implement it in Workers, we rely on the @cloudflare/privacypass-ts library, which can be installed by running:
npm i @cloudflare/privacypass-ts
This section is going to focus on the Origin work. We assume you have an Issuer up and running, which is described in a later section.
From the user’s perspective, the overhead is minimal. Their client (possibly the Silk browser extension) receives a WWW-Authenticate header with the information required for a token issuance. Then, depending on their client configuration, they are taken to the payment provider of their choice to validate their access to the service.
With a successful response to the PrivateToken challenge a session is established, and the traditional web service flow continues.
As an Attester – CAPTCHA providers, authentication provider
You are the author of a new attestation method, such as CAP, a new CAPTCHA mechanism, or a new way to validate cookie consent. You know that website owners already use Privacy Pass to trigger such challenges on the user side, and an Issuer is willing to trust your method because it guarantees a high security level. In addition, because of the Privacy Pass protocol you never see which website your attestation is being used for.
So you decide to expose your attestation method as a Privacy Pass Attester. An Issuer with public key B== trusts you, and that’s the Issuer you are going to request a token from. You can check that with the Yes/No Attester below, whose code is on Cloudflare Workers playground
const ISSUER_URL = 'https://pp-issuer-public.research.cloudflare.com/token-request'
const b64ToU8 = (b) => Uint8Array.from(atob(b), c => c.charCodeAt(0))
const handleGetChallenge = (req) => {
return new Response(`
<html>
<head>
<title>Challenge Response</title>
</head>
<body>
<button onclick="sendResponse('Yes')">Yes</button>
<button onclick="sendResponse('No')">No</button>
</body>
<script>
function sendResponse(choice) {
fetch(location.href, { method: 'POST', headers: { 'private-token-attester-data': choice } })
}
</script>
</html>
`, { status: 401, headers: { 'content-type': 'text/html' } })
}
const handlePostChallenge = (req) => {
const choice = req.headers.get('private-token-attester-data')
if (choice !== 'Yes') {
return new Response('Unauthorised', { status: 401 })
}
// hardcoded token request
// debug here https://pepe-debug.research.cloudflare.com/?challenge=PrivateToken%20challenge=%22AAIAHnR1dG9yaWFsLmNsb3VkZmxhcmV3b3JrZXJzLmNvbSBE-oWKIYqMcyfiMXOZpcopzGBiYRvnFRP3uKknYPv1RQAicGVwZS1kZWJ1Zy5yZXNlYXJjaC5jbG91ZGZsYXJlLmNvbQ==%22,token-key=%22MIIBUjA9BgkqhkiG9w0BAQowMKANMAsGCWCGSAFlAwQCAqEaMBgGCSqGSIb3DQEBCDALBglghkgBZQMEAgKiAwIBMAOCAQ8AMIIBCgKCAQEApqzusqnywE_3PZieStkf6_jwWF-nG6Es1nn5MRGoFSb3aXJFDTTIX8ljBSBZ0qujbhRDPx3ikWwziYiWtvEHSLqjeSWq-M892f9Dfkgpb3kpIfP8eBHPnhRKWo4BX_zk9IGT4H2Kd1vucIW1OmVY0Z_1tybKqYzHS299mvaQspkEcCo1UpFlMlT20JcxB2g2MRI9IZ87sgfdSu632J2OEr8XSfsppNcClU1D32iL_ETMJ8p9KlMoXI1MwTsI-8Kyblft66c7cnBKz3_z8ACdGtZ-HI4AghgW-m-yLpAiCrkCMnmIrVpldJ341yR6lq5uyPej7S8cvpvkScpXBSuyKwIDAQAB%22
const body = b64ToU8('AALoAYM+fDO53GVxBRuLbJhjFbwr0uZkl/m3NCNbiT6wal87GEuXuRw3iZUSZ3rSEqyHDhMlIqfyhAXHH8t8RP14ws3nQt1IBGE43Q9UinwglzrMY8e+k3Z9hQCEw7pBm/hVT/JNEPUKigBYSTN2IS59AUGHEB49fgZ0kA6ccu9BCdJBvIQcDyCcW5LCWCsNo57vYppIVzbV2r1R4v+zTk7IUDURTa4Mo7VYtg1krAWiFCoDxUOr+eTsc51bWqMtw2vKOyoM/20Wx2WJ0ox6JWdPvoBEsUVbENgBj11kB6/L9u2OW2APYyUR7dU9tGvExYkydXOfhRFJdKUypwKN70CiGw==')
// You can perform some check here to confirm the body is a valid token request
console.log('requesting token for tutorial.cloudflareworkers.com')
return fetch(ISSUER_URL, {
method: 'POST',
headers: { 'content-type': 'application/private-token-request' },
body: body,
})
}
const handleIssuerDirectory = async () => {
// These are fake issuers
// Issuer data can be fetch at https://pp-issuer-public.research.cloudflare.com/.well-known/private-token-issuer-directory
const TRUSTED_ISSUERS = {
"issuer1": { "token-keys": [{ "token-type": 2, "token-key": "A==" }] },
"issuer2": { "token-keys": [{ "token-type": 2, "token-key": "B==" }] },
}
return new Response(JSON.stringify(TRUSTED_ISSUERS), { headers: { "content-type": "application/json" } })
}
const handleRequest = (req) => {
const pathname = new URL(req.url).pathname
console.log(pathname, req.url)
if (pathname === '/v1/challenge') {
if (req.method === 'POST') {
return handlePostChallenge(req)
}
return handleGetChallenge(req)
}
if (pathname === '/v1/private-token-issuer-directory') {
return handleIssuerDirectory()
}
return new Response('Not found', { status: 404 })
}
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
The validation method above is simply checking if the user selected yes. Your method might be more complex, the wrapping stays the same.
Screenshot of the Yes/No Attester example
Because users might have multiple Attesters configured for a given Issuer, we recommend your Attester implements one additional endpoint exposing the keys of the issuers you are in contact with. You can try this code on Cloudflare Workers playground.
Et voilà. You have an Attester that can be used directly with the Silk browser extension (Firefox, Chrome). As you progress through your deployment, it can also be directly integrated into your applications.
If you would like to have a more advanced Attester and deployment pipeline, look at cloudflare/pp-attester template.
As an Issuer – foundation, consortium
We’ve mentioned the Issuer multiple times already. The role of an Issuer is to select a set of Attesters it wants to operate with, and communicate its public key to Origins. The whole cryptographic behavior of an Issuer is specified by the IETF draft. In contrast to the Client and Attesters which have discretionary behavior, the Issuer is fully standardized. Their opportunity is to choose a signal that is strong enough for the Origin, while preserving privacy of Clients.
Cloudflare Research is operating a public Issuer for experimental purposes to use on https://pp-issuer-public.research.cloudflare.com. It is the simplest solution to start experimenting with Privacy Pass today. Once it matures, you can consider joining a production Issuer, or deploying your own.
To deploy your own, you should:
git clone github.com/cloudflare/pp-issuer
Update wrangler.toml with your Cloudflare Workers account id and zone id. The open source Issuer API works as follows:
/.well-known/private-token-issuer-directory returns the issuer configuration. Note it does not expose non-standard token-key-legacy
/token-request returns a token. This endpoint should be gated (by Cloudflare Access for instance) to only allow trusted attesters to call it
/admin/rotate to generate a new public key. This should only be accessible by your team, and be called prior to the issuer being available.
Then, wrangler publish, and you’re good to onboard Attesters.
Development of Silk extension
Just like the protocol, the browser technology on which Privacy Pass was proven viable has changed as well. For 5 years, the protocol got deployed along with a browser extension for Chrome and Firefox. In 2021, Chrome released a new version of extension configurations, usually referred to as Manifest version 3 (MV3). Chrome also started enforcing this new configuration for all newly released extensions.
Privacy Pass the extension is based on an agreed upon Privacy Pass authentication protocol. Briefly looking at Chrome’s API documentation, we should be able to use the onAuthRequired event. However, with PrivateToken authentication not yet being standard, there are no hooks provided by browsers for extensions to add logic to this event.
The approach we decided to use is to define a client side replay API. When a response comes with 401 WWW-Authenticate PrivateToken, the browser lets it through, but triggers the private token redemption flow. The original page is notified when a token has been retrieved, and replays the request. For this second request, the browser is able to attach an authorization token, and the request succeeds. This is an active replay performed by the client, rather than a transparent replay done by the platform. A specification is available on GitHub.
We are looking forward to the standard progressing, and simplifying this part of the project. This should improve diversity in attestation methods. As we see in the next section, this is key to identifying new signals that can be leveraged by origins.
A standard for anonymous credentials
IP remains as a key identifier in the anti abuse system. At the same time, IP fingerprinting techniques have become a bigger concern and platforms have started to remove some of these ways of tracking users. To enable anti abuse systems to not rely on IP, while ensuring user privacy, Privacy Pass offers a reasonable alternative to deal with potentially abusive or suspicious traffic. The attestation methods vary and can be chosen as needed for a particular deployment. For example, Apple decided to back their attestation with hardware when using Privacy Pass as the authorization technology for iCloud Private Relay. Another example is Cloudflare Research which decided to deploy a Turnstile attester to signal a successful solve for Cloudflare’s challenge platform.
In all these deployments, Privacy Pass-like technology has allowed for specific bits of information to be shared. Instead of sharing your location, past traffic, and possibly your name and phone number simply by connecting to a website, your device is able to prove specific information to a third party in a privacy preserving manner. Which user information and attestation methods are sufficient to prevent abuse is an open question. We are looking to empower researchers with the release of this software to help in the quest for finding these answers. This could be via new experiments such as testing out new attestation methods, or fostering other privacy protocols by providing a framework for specific information sharing.
Future recommendations
Just as we expect this latest version of Privacy Pass to lead to new applications and ideas we also expect further evolution of the standard and the clients that use it. Future development of Privacy Pass promises to cover topics like batch token issuance and rate limiting. From our work building and deploying this version of Privacy Pass we have encountered limitations that we expect to be resolved in the future as well.
The division of labor between Attesters and Issuers and the clear directions of trust relationships between the Origin and Issuer, and the Issuer and Attester make reasoning about the implications of a breach of trust clear. Issuers can trust more than one Attester, but since many current deployments of Privacy Pass do not identify the Attester that lead to issuance, a breach of trust in one Attester would render all tokens issued by any Issuer that trusts the Attester untrusted. This is because it would not be possible to tell which Attester was involved in the issuance process. Time will tell if this promotes a 1:1 correspondence between Attesters and Issuers.
The process of developing a browser extension supported by both Firefox and Chrome-based browsers can at times require quite baroque (and brittle) code paths. Privacy Pass the protocol seems a good fit for an extension of the webRequest.onAuthRequired browser event. Just as Privacy Pass appears as an alternate authentication message in the WWW-Authenticate HTTP header, browsers could fire the onAuthRequired event for Private Token authentication too and include and allow request blocking support within the onAuthRequired event. This seems a natural evolution of the use of this event which currently is limited to the now rather long-in-the-tooth Basic authentication.
Conclusion
Privacy Pass provides a solution to one of the longstanding challenges of the web: anonymous authentication. By leveraging cryptography, the protocol allows websites to get the information they need from users, and solely this information. It’s already used by millions to help distinguish human requests from automated bots in a manner that is privacy protective and often seamless. We are excited by the protocol’s broad and growing adoption, and by the novel use cases that are unlocked by this latest version.
Cloudflare’s Privacy Pass implementations are available on GitHub, and are compliant with the standard. We have open-sourced a set of templates that can be used to implement Privacy PassOrigins,Issuers, andAttesters, which leverage Cloudflare Workers to get up and running quickly.
For those looking to try Privacy Pass out for themselves right away, download the Silk – Privacy Pass Client browser extensions (Firefox, Chrome, GitHub) and start browsing a web with fewer bot checks today.
A helpful summary of which US retail stores are using facial recognition, thinking about using it, or currently not planning on using it. (This, of course, can all change without notice.)
Three years ago, I wrote that campaigns to ban facial recognition are too narrow. The problem here is identification, correlation, and then discrimination. There’s no difference whether the identification technology is facial recognition, the MAC address of our phones, gait recognition, license plate recognition, or anything else. Facial recognition is just the easiest technology right now.
To test PIGEON’s performance, I gave it five personal photos from a trip I took across America years ago, none of which have been published online. Some photos were snapped in cities, but a few were taken in places nowhere near roads or other easily recognizable landmarks.
That didn’t seem to matter much.
It guessed a campsite in Yellowstone to within around 35 miles of the actual location. The program placed another photo, taken on a street in San Francisco, to within a few city blocks.
Not every photo was an easy match: The program mistakenly linked one photo taken on the front range of Wyoming to a spot along the front range of Colorado, more than a hundred miles away. And it guessed that a picture of the Snake River Canyon in Idaho was of the Kawarau Gorge in New Zealand (in fairness, the two landscapes look remarkably similar).
This kind of thing will likely get better. And even if it is not perfect, it has some pretty profound privacy implications (but so did geolocation in the EXIF data that accompanies digital photos).
Lawmakers noted the pharmacies’ policies for releasing medical records in a letter dated Tuesday to the Department of Health and Human Services (HHS) Secretary Xavier Becerra. The letter—signed by Sen. Ron Wyden (D-Ore.), Rep. Pramila Jayapal (D-Wash.), and Rep. Sara Jacobs (D-Calif.)—said their investigation pulled information from briefings with eight big prescription drug suppliers.
They include the seven largest pharmacy chains in the country: CVS Health, Walgreens Boots Alliance, Cigna, Optum Rx, Walmart Stores, Inc., The Kroger Company, and Rite Aid Corporation. The lawmakers also spoke with Amazon Pharmacy.
All eight of the pharmacies said they do not require law enforcement to have a warrant prior to sharing private and sensitive medical records, which can include the prescription drugs a person used or uses and their medical conditions. Instead, all the pharmacies hand over such information with nothing more than a subpoena, which can be issued by government agencies and does not require review or approval by a judge.
Three pharmacies—CVS Health, The Kroger Company, and Rite Aid Corporation—told lawmakers they didn’t even require their pharmacy staff to consult legal professionals before responding to law enforcement requests at pharmacy counters. According to the lawmakers, CVS, Kroger, and Rite Aid said that “their pharmacy staff face extreme pressure to immediately respond to law enforcement demands and, as such, the companies instruct their staff to process those requests in store.”
The rest of the pharmacies—Amazon, Cigna, Optum Rx, Walmart, and Walgreens Boots Alliance—at least require that law enforcement requests be reviewed by legal professionals before pharmacists respond. But, only Amazon said it had a policy of notifying customers of law enforcement demands for pharmacy records unless there were legal prohibitions to doing so, such as a gag order.
The collective thoughts of the interwebz
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.