To track down an alleged mail thief, a US postal inspector used license plate reader technology, GPS data collected by a rental car company, and, most damning of all, hid a camera inside one of the targeted blue post boxes which captured the suspect’s full face as they allegedly helped themselves to swathes of peoples’ mail.
When you get a push notification on your Apple or Google phone, those notifications go through Apple and Google servers. Which means that those companies can spy on them—either for their own reasons or in response to government demands.
In a statement, Apple said that Wyden’s letter gave them the opening they needed to share more details with the public about how governments monitored push notifications.
“In this case, the federal government prohibited us from sharing any information,” the company said in a statement. “Now that this method has become public we are updating our transparency reporting to detail these kinds of requests.”
Google said that it shared Wyden’s “commitment to keeping users informed about these requests.”
The Department of Justice did not return messages seeking comment on the push notification surveillance or whether it had prevented Apple of Google from talking about it.
Wyden’s letter cited a “tip” as the source of the information about the surveillance. His staff did not elaborate on the tip, but a source familiar with the matter confirmed that both foreign and U.S. government agencies have been asking Apple and Google for metadata related to push notifications to, for example, help tie anonymous users of messaging apps to specific Apple or Google accounts.
Spying and surveillance are different but related things. If I hired a private detective to spy on you, that detective could hide a bug in your home or car, tap your phone, and listen to what you said. At the end, I would get a report of all the conversations you had and the contents of those conversations. If I hired that same private detective to put you under surveillance, I would get a different report: where you went, whom you talked to, what you purchased, what you did.
Before the internet, putting someone under surveillance was expensive and time-consuming. You had to manually follow someone around, noting where they went, whom they talked to, what they purchased, what they did, and what they read. That world is forever gone. Our phones track our locations. Credit cards track our purchases. Apps track whom we talk to, and e-readers know what we read. Computers collect data about what we’re doing on them, and as both storage and processing have become cheaper, that data is increasingly saved and used. What was manual and individual has become bulk and mass. Surveillance has become the business model of the internet, and there’s no reasonable way for us to opt out of it.
Spying is another matter. It has long been possible to tap someone’s phone or put a bug in their home and/or car, but those things still require someone to listen to and make sense of the conversations. Yes, spyware companies like NSO Group help the government hack into people’s phones, but someone still has to sort through all the conversations. And governments like China could censor social media posts based on particular words or phrases, but that was coarse and easy to bypass. Spying is limited by the need for human labor.
AI is about to change that. Summarization is something a modern generative AI system does well. Give it an hourlong meeting, and it will return a one-page summary of what was said. Ask it to search through millions of conversations and organize them by topic, and it’ll do that. Want to know who is talking about what? It’ll tell you.
The technologies aren’t perfect; some of them are pretty primitive. They miss things that are important. They get other things wrong. But so do humans. And, unlike humans, AI tools can be replicated by the millions and are improving at astonishing rates. They’ll get better next year, and even better the year after that. We are about to enter the era of mass spying.
Mass surveillance fundamentally changed the nature of surveillance. Because all the data is saved, mass surveillance allows people to conduct surveillance backward in time, and without even knowing whom specifically you want to target. Tell me where this person was last year. List all the red sedans that drove down this road in the past month. List all of the people who purchased all the ingredients for a pressure cooker bomb in the past year. Find me all the pairs of phones that were moving toward each other, turned themselves off, then turned themselves on again an hour later while moving away from each other (a sign of a secret meeting).
Similarly, mass spying will change the nature of spying. All the data will be saved. It will all be searchable, and understandable, in bulk. Tell me who has talked about a particular topic in the past month, and how discussions about that topic have evolved. Person A did something; check if someone told them to do it. Find everyone who is plotting a crime, or spreading a rumor, or planning to attend a political protest.
There’s so much more. To uncover an organizational structure, look for someone who gives similar instructions to a group of people, then all the people they have relayed those instructions to. To find people’s confidants, look at whom they tell secrets to. You can track friendships and alliances as they form and break, in minute detail. In short, you can know everything about what everybody is talking about.
This spying is not limited to conversations on our phones or computers. Just as cameras everywhere fueled mass surveillance, microphones everywhere will fuel mass spying. Siri and Alexa and “Hey Google” are already always listening; the conversations just aren’t being saved yet.
Knowing that they are under constant surveillance changes how people behave. They conform. They self-censor, with the chilling effects that brings. Surveillance facilitates social control, and spying will only make this worse. Governments around the world already use mass surveillance; they will engage in mass spying as well.
Corporations will spy on people. Mass surveillance ushered in the era of personalized advertisements; mass spying will supercharge that industry. Information about what people are talking about, their moods, their secrets—it’s all catnip for marketers looking for an edge. The tech monopolies that are currently keeping us all under constant surveillance won’t be able to resist collecting and using all of that data.
In the early days of Gmail, Google talked about using people’s Gmail content to serve them personalized ads. The company stopped doing it, almost certainly because the keyword data it collected was so poor—and therefore not useful for marketing purposes. That will soon change. Maybe Google won’t be the first to spy on its users’ conversations, but once others start, they won’t be able to resist. Their true customers—their advertisers—will demand it.
We could limit this capability. We could prohibit mass spying. We could pass strong data-privacy rules. But we haven’t done anything to limit mass surveillance. Why would spying be any different?
According to the letter, a surveillance program now known as Data Analytical Services (DAS) has for more than a decade allowed federal, state, and local law enforcement agencies to mine the details of Americans’ calls, analyzing the phone records of countless people who are not suspected of any crime, including victims. Using a technique known as chain analysis, the program targets not only those in direct phone contact with a criminal suspect but anyone with whom those individuals have been in contact as well.
The DAS program, formerly known as Hemisphere, is run in coordination with the telecom giant AT&T, which captures and conducts analysis of US call records for law enforcement agencies, from local police and sheriffs’ departments to US customs offices and postal inspectors across the country, according to a White House memo reviewed by WIRED. Records show that the White House has, for the past decade, provided more than $6 million to the program, which allows the targeting of the records of any calls that use AT&T’s infrastructure—a maze of routers and switches that crisscross the United States.
Generative AI is going to be a powerful tool for data analysis and summarization. Here’s an example of it being used for sentiment analysis. My guess is that it isn’t very good yet, but that it will get better.
This is an excerpt from a longer paper. You can read the whole thing (complete with sidebars and illustrations) here.
Our message is simple: it is possible to get the best of both worlds. We can and should get the benefits of the cloud while taking security back into our own hands. Here we outline a strategy for doing that.
What Is Decoupling?
In the last few years, a slew of ideas old and new have converged to reveal a path out of this morass, but they haven’t been widely recognized, combined, or used. These ideas, which we’ll refer to in the aggregate as “decoupling,” allow us to rethink both security and privacy.
Here’s the gist. The less someone knows, the less they can put you and your data at risk. In security this is called Least Privilege. The decoupling principle applies that idea to cloud services by making sure systems know as little as possible while doing their jobs. It states that we gain security and privacy by separating private data that today is unnecessarily concentrated.
To unpack that a bit, consider the three primary modes for working with our data as we use cloud services: data in motion, data at rest, and data in use. We should decouple them all.
Our data is in motion as we exchange traffic with cloud services such as videoconferencing servers, remote file-storage systems, and other content-delivery networks. Our data at rest, while sometimes on individual devices, is usually stored or backed up in the cloud, governed by cloud provider services and policies. And many services use the cloud to do extensive processing on our data, sometimes without our consent or knowledge. Most services involve more than one of these modes.
To ensure that cloud services do not learn more than they should, and that a breach of one does not pose a fundamental threat to our data, we need two types of decoupling. The first is organizational decoupling: dividing private information among organizations such that none knows the totality of what is going on. The second is functional decoupling: splitting information among layers of software. Identifiers used to authenticate users, for example, should be kept separate from identifiers used to connect their devices to the network.
In designing decoupled systems, cloud providers should be considered potential threats, whether due to malice, negligence, or greed. To verify that decoupling has been done right, we can learn from how we think about encryption: you’ve encrypted properly if you’re comfortable sending your message with your adversary’s communications system. Similarly, you’ve decoupled properly if you’re comfortable using cloud services that have been split across a noncolluding group of adversaries.
Apple has warned leaders of the opposition government in India that their phones are being spied on:
Multiple top leaders of India’s opposition parties and several journalists have received a notification from Apple, saying that “Apple believes you are being targeted by state-sponsored attackers who are trying to remotely compromise the iPhone associated with your Apple ID ….”
For India to uphold fundamental rights, authorities must initiate an immediate independent inquiry, implement a ban on the use of rights-abusing commercial spyware, and make a commitment to reform the country’s surveillance laws. These latest warnings build on repeated instances of cyber intrusion and spyware usage, and highlights the surveillance impunity in India that continues to flourish despite the public outcry triggered by the 2019 Pegasus Project revelations.
Fascinating story of a covert wiretap that was discovered because of an expired TLS certificate:
The suspected man-in-the-middle attack was identified when the administrator of jabber.ru, the largest Russian XMPP service, received a notification that one of the servers’ certificates had expired.
However, jabber.ru found no expired certificates on the server, as explained in a blog post by ValdikSS, a pseudonymous anti-censorship researcher based in Russia who collaborated on the investigation.
The expired certificate was instead discovered on a single port being used by the service to establish an encrypted Transport Layer Security (TLS) connection with users. Before it had expired, it would have allowed someone to decrypt the traffic being exchanged over the service.
Interesting article about the Snowden documents, including comments from former Guardian editor Ewen MacAskill
MacAskill, who shared the Pulitzer Prize for Public Service with Glenn Greenwald and Laura Poitras for their journalistic work on the Snowden files, retired from The Guardian in 2018. He told Computer Weekly that:
As far as he knows, a copy of the documents is still locked in the New York Times office. Although the files are in the New York Times office, The Guardian retains responsibility for them.
As to why the New York Times has not published them in a decade, MacAskill maintains “this is a complicated issue.” “There is, at the very least, a case to be made for keeping them for future generations of historians,” he said.
Why was only 1% of the Snowden archive published by the journalists who had full access to it? Ewen MacAskill replied: “The main reason for only a small percentage—though, given the mass of documents, 1% is still a lot—was diminishing interest.”
[…]
The Guardian’s journalist did not recall seeing the three revelations published by Computer Weekly, summarized below:
The NSA listed Cavium, an American semiconductor company marketing Central Processing Units (CPUs)—the main processor in a computer which runs the operating system and applications—as a successful example of a “SIGINT-enabled” CPU supplier. Cavium, now owned by Marvell, said it does not implement back doors for any government.
The NSA compromised lawful Russian interception infrastructure, SORM. The NSA archive contains slides showing two Russian officers wearing jackets with a slogan written in Cyrillic: “You talk, we listen.” The NSA and/or GCHQ has also compromised key lawful interception systems.
Among example targets of its mass-surveillance programme, PRISM, the NSA listed the Tibetan government in exile.
Those three pieces of info come from Jake Appelbaum’s Ph.D. thesis.
Susan Landau published an excellent essay on the current justification for the government breaking end-to-end-encryption: child sexual abuse and exploitation (CSAE). She puts the debate into historical context, discusses the problem of CSAE, and explains why breaking encryption isn’t the solution.
Amnesty International has published a comprehensive analysis of the Predator government spyware products.
These technologies used to be the exclusive purview of organizations like the NSA. Now they’re available to every country on the planet—democratic, nondemocratic, authoritarian, whatever—for a price. This is the legacy of not securing the Internet when we could have.
In 2023, data-driven approaches to making decisions are the norm. We use data for everything from analyzing x-rays to translating thousands of languages to directing autonomous cars. However, when it comes to building these systems, the conventional approach has been to collect as much data as possible, and worry about privacy as an afterthought.
The problem is, data can be sensitive and used to identify individuals – even when explicit identifiers are removed or noise is added.
Cloudflare Research has been interested in exploring different approaches to this question: is there a truly private way to perform data collection, especially for some of the most sensitive (but incredibly useful!) technology?
It’s with those use cases in mind that we’ve been participating in the Privacy Preserving Measurement working group at the IETF whose goal is to develop systems for collecting and using this data while minimizing the amount of per-user information exposed to the data collector.
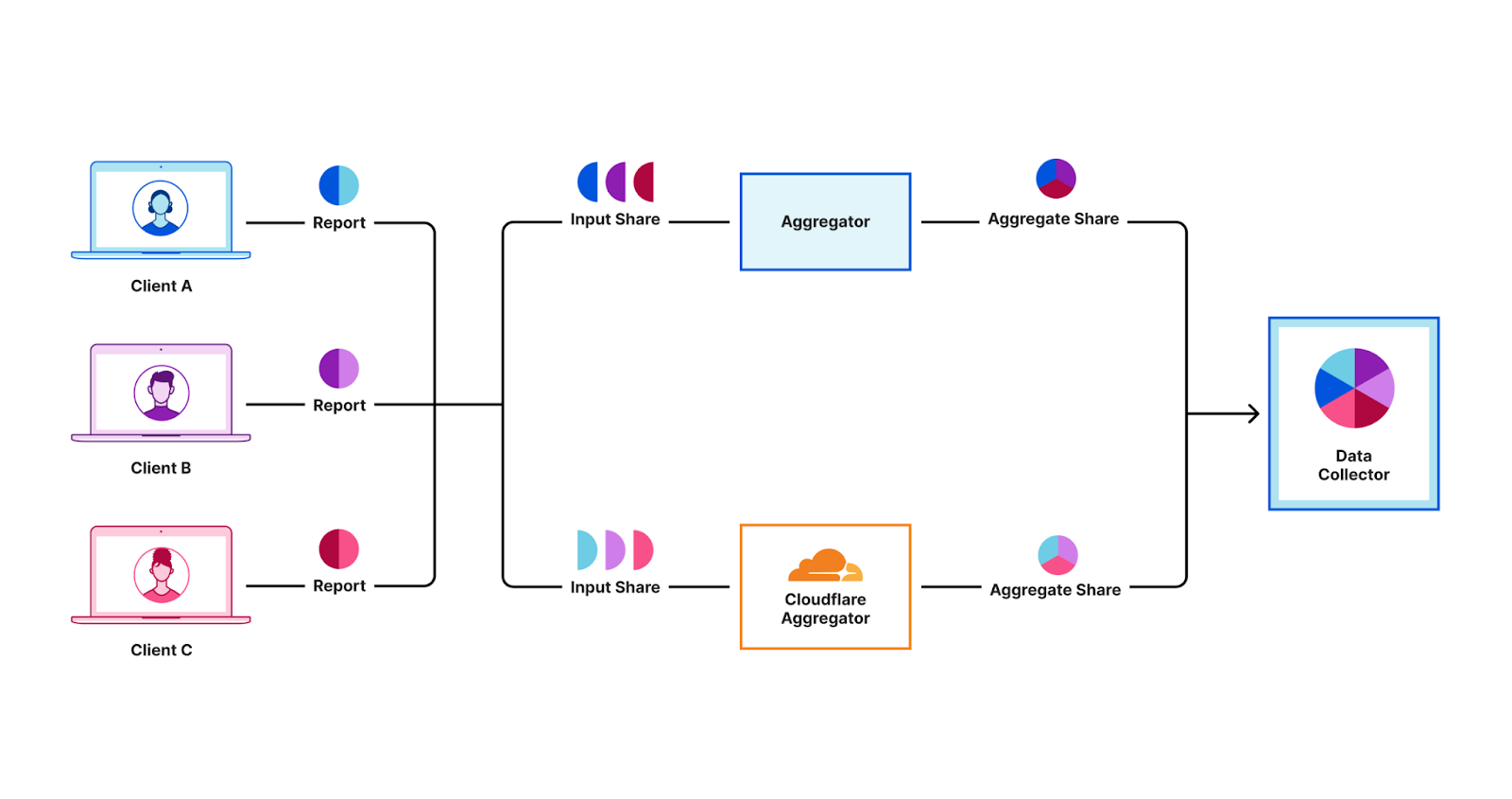
In this blog post, we’ll do a deep dive into the fundamental concepts behind the DAP protocol and give an example of how we’ve implemented it into Daphne, our open source aggregator server. We hope this will inspire others to collaborate with us and get involved in this space!
The principles behind DAP, an open standard for privacy preserving measurement
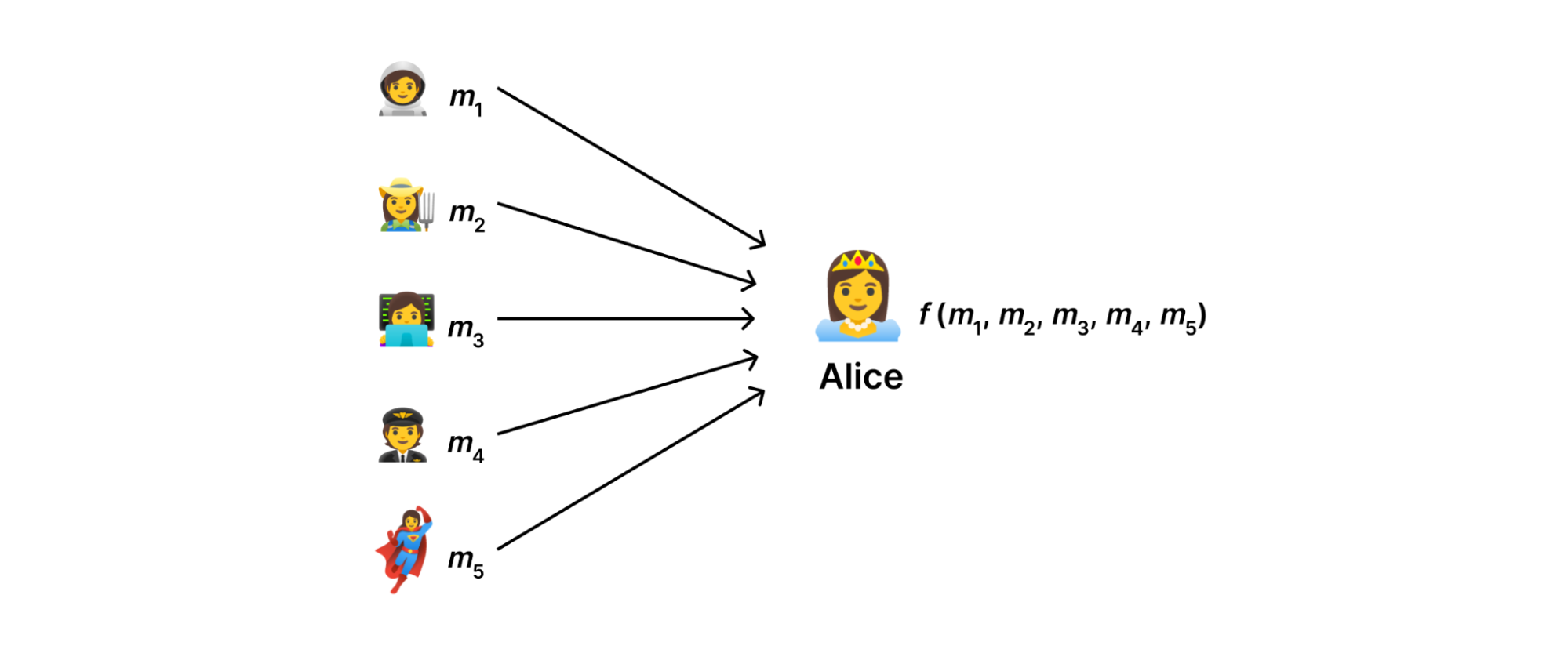
At a high level, using the DAP protocol forces us to think in terms of data minimization:collect only the data that we use and nothing more. Abstractly, our goal is to devise a system with which a data collector can compute some function \( f(m_{1},…,m_{N}) \) of measurements \( m_{1},…,m_{N} \) uploaded by users without observing the measurements in the clear.
Alice wants to know some aggregate statistic – like the average salary of the people at the party – without knowing how much each individual person makes.
This may at first seem like an impossible task: to compute on data without knowing the data we're computing on. Nevertheless, —and, as is often the case in cryptography— once we've properly constrained the problem, solutions begin to emerge.
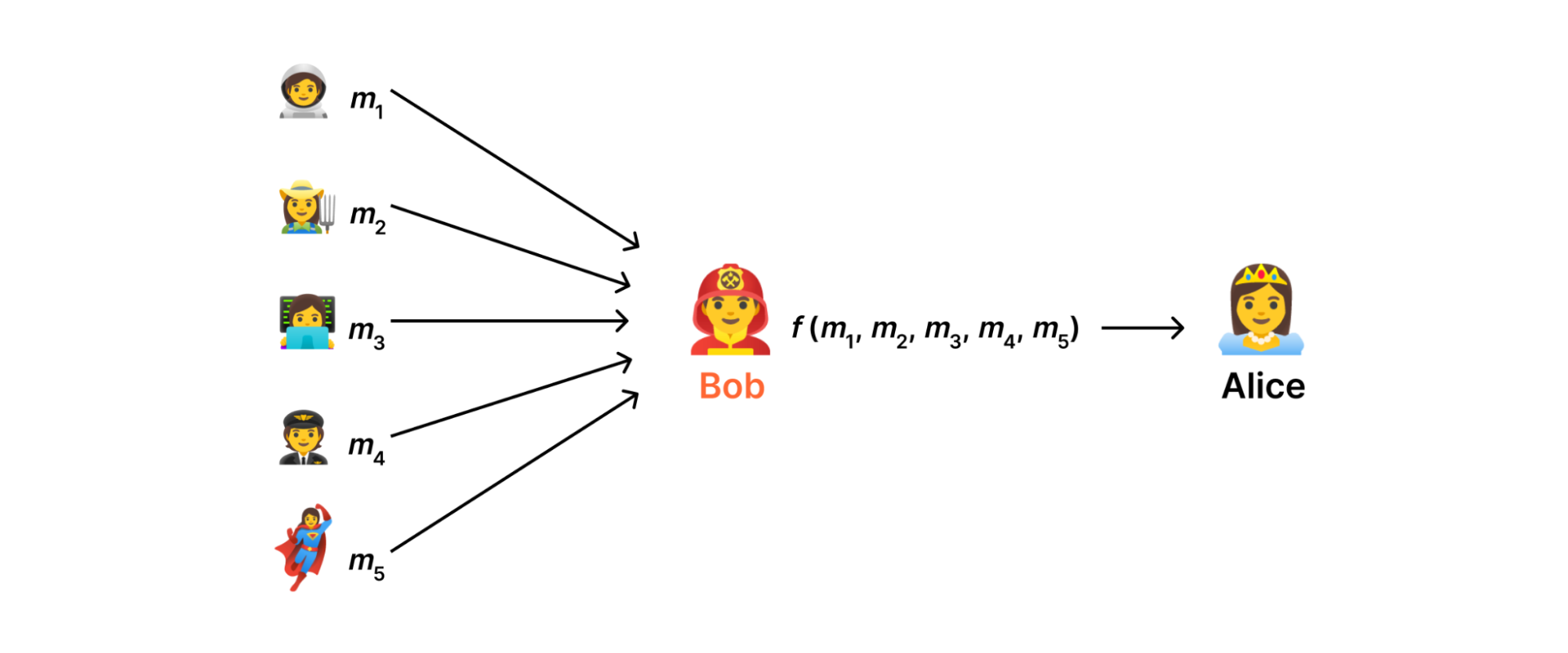
Strawperson solution: delegate the calculation to a trusted third party, Bob. The problem with this is that Bob can see the private inputs in the clear
In an ideal world (see above), there would be some server somewhere on the Internet that we could trust to consume measurements, aggregate them, and send the result to the data collector without ever disclosing anything else. However, in reality there's no reason for users to trust such a server more than the data collector; Indeed, both are subject to the usual assortment of attacks that can lead to a data breach.
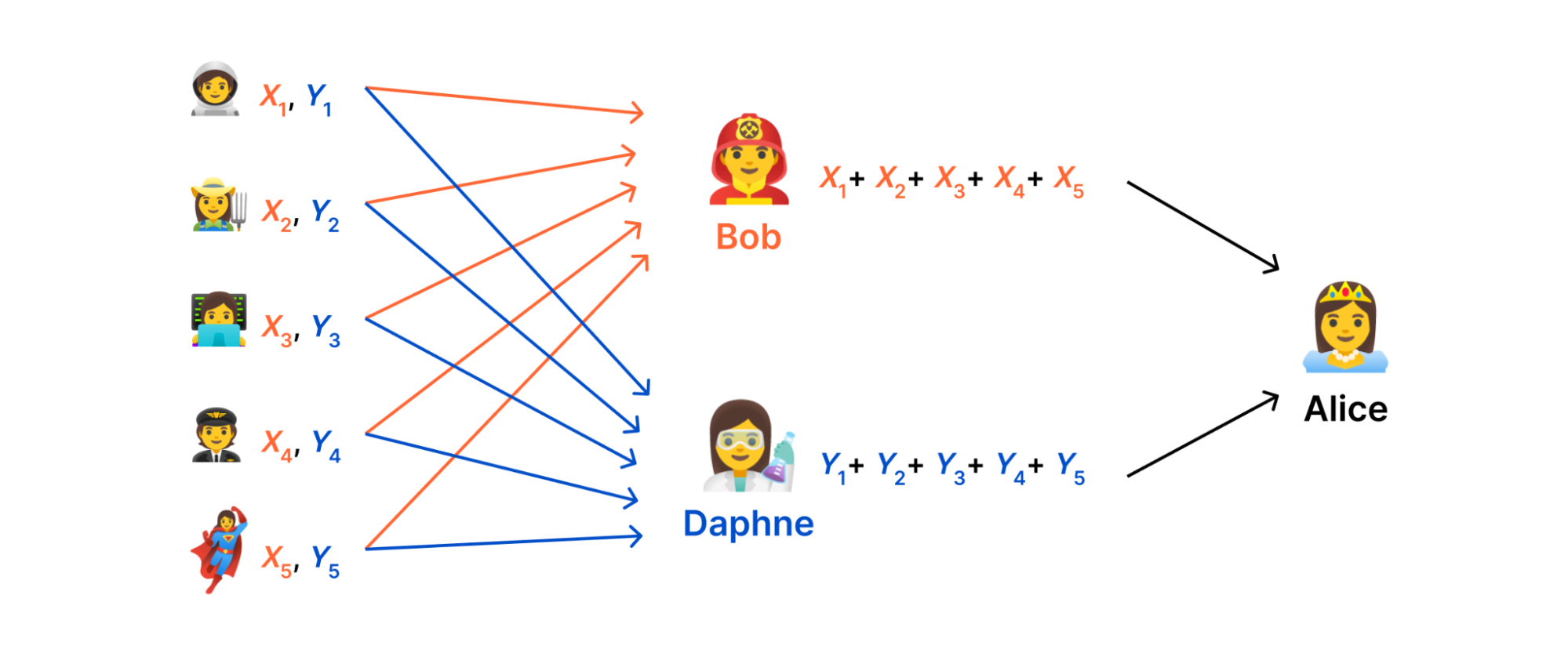
MPC solution: secret-share the inputs across multiple parties, a.k.a. Bob and Daphne. If at least one person is honest, Alice gets the aggregate result without anyone knowing individual inputs in the clear.
Instead, what we do in DAP is distribute the computation across the servers such that no single server has a complete measurement. The key idea that makes this possible is secret sharing.
Computing on secret shared data
To set things up, let's make the problem a little more concrete. Suppose each measurement \( m_{i} \) is a number and our goal is to compute the sum of the measurements. That is, \( f(m_{1},…,m_{N}) = m_{1} + \cdots + m_{N} \). Our goal is to use secret sharing to allow two servers, which we'll call aggregators, to jointly compute this sum.
To understand secret sharing, we're going to need a tiny bit of math—modular arithmetic. The expression \( X + 1 (\textrm{mod}) \textit{q} \) means "add \( X \) and \( Y \), then divide the sum by \( q \) and return the remainder". For now the modulus \( q \) can be any large number, as long as it's larger than any sum we'd ever want to compute (\( 2 ^{64} \), say). In the remainder of this section, we'll omit \( q \) and simply write \( X + Y \) for addition modulo \( q \).
The goal of secret sharing is to shard a measurement (i.e., a "secret") into two "shares" such that (i) the measurement can be recovered by combining the shares together and (ii) neither share leaks any information about the measurement. To secret share each \( m_{i} \), we choose a random number \( R_{i} \in \lbrace 0,…,q – 1\rbrace \), set the first share to be \(X_{i} = m_{i} – R_{i} \) and set the other share to be \( Y_{i} = R_{i} \). To recover the measurement, we simply add the shares together. This works because \( X_{i} + Y_{i} = (m_{i} – R_{i}) + R_{i} = m_{i} \). Moreover, each share is indistinguishable from a random number: For example, \( 1337 \) might be secret-shared into \( 11419752798245067454 \) and \( 7026991275464485499 \) (modulo \( q = 2^{64} \)).
With this scheme we can devise a simple protocol for securely computing the sum:
Each client shards its measurement \( m_{i} \) into \( X_{i} \) and \( Y_{i} \) and sends one share to each server.
The first aggregator computes \( X = X_{1} + \cdots + X_{N} \) and reveals \( X \) to the data collector. The second aggregator computes \( Y = Y_{1} + \cdots + Y_{N} \) and reveals \( Y \) to the data collector.
The data collector unshards the result as \( r = X + Y \).
This works because the secret shares are additive, and the order in which we add things up is irrelevant to the function we're computing:
\( r = m_{1} + \cdots + m_{N} \) // by definition \( r = (m_{1} – R_{1}) + R_{1} + \cdots (m_{N} – R_{N}) + R_{N} \) // apply sharding \( r = (m_{1} – R_{1}) + \cdots + (m_{N} – R_{N}) + R_{1} + \cdots R_{N} \) // rearrange the sum \( r = X + Y \) // apply aggregation
Rich data types
This basic template for secure aggregation was described in a paper from Henry Corrigan-Gibbs and Dan Boneh called "Prio: Private, Robust, and Scalable Computation of Aggregate Statistics" (NSDI 2017). This paper is a critical milestone in DAP's history, as it showed that a wide variety of aggregation tasks (not just sums) can be solved within one, simple protocol framework, Prio. With DAP, our goal in large part is to bring this framework to life.
All Prio tasks are instances of the same template. Measurements are encoded in a form that allows the aggregation function to be expressed as the sum of (shares of) the encoded measurements. For example:
To get arithmetic mean, we just divide the sum by the number of measurements.
Variance and standard deviation can be expressed as a linear function of the sum and the sum of squares (i.e., \( m_{i}, m_{i}^{2} \) for each \( i \)).
Quantiles (e.g., median) can be estimated reasonably well by mapping the measurements into buckets and aggregating the histogram.
Linear regression (i.e., finding a line of best fit through a set of data points) is a bit more complicated, but can also be expressed in the Prio framework.
This degree of flexibility is essential for wide-spread adoption because it allows us to get the most value we can out of a relatively small amount of software. However, there are a couple problems we still need to overcome, both of which entail the need for some form of interaction.
Input validation
The first problem is input validation. Software engineers, especially those of us who operate web services, know in our bones that validating inputs we get from clients is of paramount importance. (Never, ever stick a raw input you got from a client into an SQL query!) But if the inputs are secret shared, then there is no way for an aggregator to discern even a single bit of the measurement, let alone check that it has an expected value. (A secret share of a valid measurement and a number sampled randomly from \( \lbrace 0,…,q – 1 \rbrace \) look identical.) At least, not on its own.
The solution adopted by Prio (and the standard, with some improvements), is a special kind of zero-knowledge proof (ZKP) system designed to operate on secret shared data. The goal is for a prover to convince a verifier that a statement about some data it has committed to is true (e.g., the user has a valid hardware key), without revealing the data itself (e.g. which hardware key is in-use).
Our setting is exactly the same, except that we're working on secret-shared data rather than committed data. Along with the measurement shares, the client sends shares of a validity proof; then during aggregation, the aggregators interact with one another in order to check and verify the proof. (One round-trip over the network is required.)
A happy consequence of working with secret shared data is that proof generation and verification are much faster than for committed (or encrypted) data. This is mainly because we avoid the use of public-key cryptography (i.e., elliptic curves) and are less constrained in how we choose cryptographic parameters. (We require the modulus \( q \) to be a prime number with a particular structure, but such primes are not hard to find.)
Non-linear aggregation
There are a variety of aggregation tasks for which Prio is not well-suited, in particular those that are non-linear. One such task is to find the "heavy hitters" among the set of measurements. The heavy hitters are the subset of the measurements that occur most frequently, say at least \( t \) times for some threshold \( t \). For example, the measurements might be the URLs visited on a given day by users of a web browser; the heavy hitters would be the set of URLs that were visited by at least \( t \) users.
This computation can be expressed as a simple program:
However, it cannot be expressed as a linear function, at least not efficiently (with sub-exponential space). This would be required to perform this computation on secret-shared measurements.
In order to enable non-linear computation on secret shared data, it is necessary to introduce some form of interaction. There are a few possibilities. For the heavy hitters problem in particular, Henry Corrigan-Gibbs and others devised a protocol called Poplar (IEEE Security & Privacy 2021) in which several rounds of aggregation and unsharding are performed, where in each round, information provided by the collector is used to "query" the measurements to obtain a refined aggregate result.
Helping to build a world of multi-party computation
Protocols like Prio or Poplar that enable computation over secret shared data fit into a rich tradition in cryptography known as multi-party computation (MPC). MPC is at once an active research area in theoretical computer science and a class of protocols that are beginning to see real-world use—in our case, to minimize the amount of privacy-sensitive information we collect in order to keep the Internet moving.
The PPM working group at IETF represents a significant effort, by Cloudflare and others, to standardize MPC techniques for privacy preserving measurement. This work has three main prongs:
To identify the types of problems that need to be solved.
To provide cryptography researchers from academia, industry, and the public sector with "templates" for solutions that we know how to deploy. One such template is called a "Verifiable Distributed Aggregation Function (VDAF)", which specifies a kind of "API boundary" between protocols like Prio and Poplar and the systems that are built around them. Cloudflare Research is leading development of the standard, contributing to implementations, and providing security analysis.
To provide a deployment roadmap for emerging protocols. DAP is one such roadmap: it specifies execution of a generic VDAF over HTTPS and attends to the various operational considerations that arise as deployments progress. As well as contributing to the standard itself, Cloudflare has developed its own implementation designed for our own infrastructure (see below).
The IETF is working on its first set of drafts (DAP/VDAF). These drafts are mature enough to deploy, and a number of deployments are scaling up as we speak. Our hope is that we have initiated positive feedback between theorists and practitioners: as new cryptographic techniques emerge, more practitioners will begin to work with them, which will lead to identifying new problems to solve, leading to new techniques, and so on.
Daphne: Cloudflare’s implementation of a DAP Aggregation Server
Our emerging technology group has been working on Daphne, our Rust-based implementation of a DAP aggregator server. This is only half of a deployment – DAP architecture requires two aggregator servers to interoperate, both operated by different parties. Our current version only implements the DAP Helper role; the other role is the DAP Leader. Plans are in the works to implement the Leader as well, which will open us up to deploy Daphne for more use cases.
We made two big decisions in our implementation here: using Rust and using Workers. Rust has been skyrocketing in popularity in the past few years due to its performance and memory management – a favorite of cryptographers for similar reasons. Workers is Cloudflare’s serverless execution environment that allows developers to easily deploy applications globally across our network – making it a favorite tool to prototype with at Cloudflare. This allows for easy integration with our Workers-based storage solutions like: Durable Objects, which we’re using for storing various data artifacts as required by the DAP protocol; and KV, which we’re using for managing aggregation task configuration. We’ve learned a lot from our interop tests and deployment, which has helped improve our own Workers products and which we have also fed back into the PPM working group to help improve the DAP standard.
If you’re interested in learning more about Daphne or collaborating with us in this space, you can fill out this form. If you’d like to get involved in the DAP standard, you can check out the working group.
Between third-party cookies that track your activity across websites, to highly targeted advertising based on your IP address and browsing data, it's no secret that today’s Internet browsing experience isn’t as private as it should be. Here at Cloudflare, we believe everyone should be able to browse the Internet free of persistent tracking and prying eyes.
That’s why we’re excited to announce that we’ve partnered with Microsoft Edge to provide a fast and secure VPN, right in the browser. Users don’t have to install anything new or understand complex concepts to get the latest in network-level privacy: Edge Secure Network VPN is available on the latest consumer version of Microsoft Edge in most markets, and automatically comes with 5 GB of data. Just enable the feature by going to [Microsoft Edge Settings & more (…) > Browser essentials, and click Get VPN for free]. See Microsoft’s Edge Secure Network page for more details.
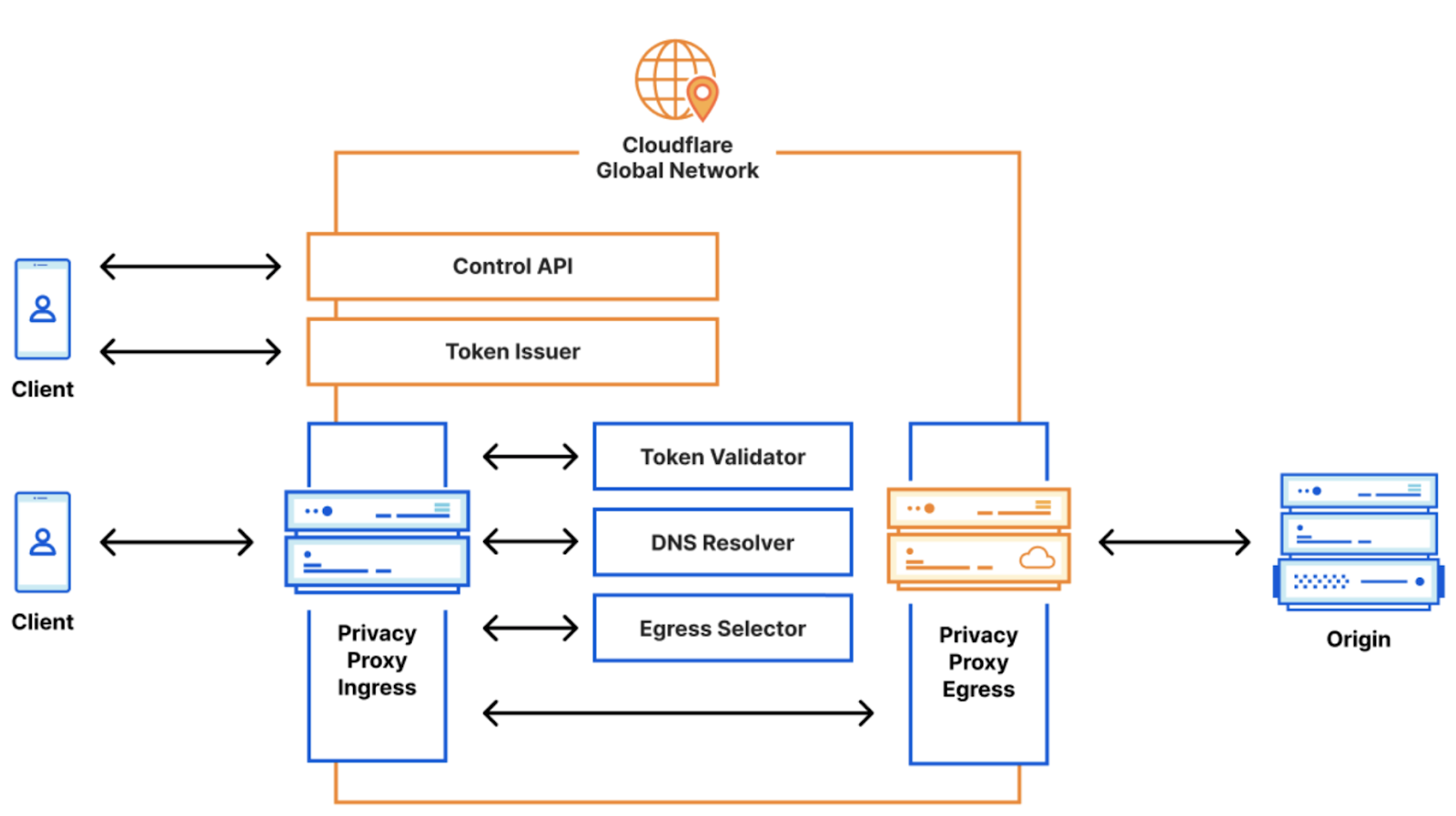
Cloudflare’s Privacy Proxy platform isn’t your typical VPN
To take a step back: a VPN is a way in which the Internet traffic leaving your device is tunneled through an intermediary server operated by a provider – in this case, Cloudflare! There are many important pieces that make this possible, but among them is the VPNprotocol, which defines the way in which the tunnel is established and how traffic flows through it. You may have heard of some of these protocols: Wireguard, IPsec, and OpenVPN, for example. And while we’re no stranger to these, (Cloudflare’s WireGuard implementation is currently in use by millions of devices that use 1.1.1.1+WARP) – we see our Privacy Proxy Platform as a way to push forward the next frontier of Internet privacy and embrace one of Cloudflare’s core values: open Internet standards.
The Privacy Proxy Platform implements HTTP CONNECT, a method defined in the HTTP standard that proxies traffic by establishing a tunnel and then sending reliable and ordered byte streams through that tunnel. You can read more about this proxying method (and its history!) in our Primer on Proxies.
We also leverage other parts of Cloudflare’s privacy-oriented infrastructure that are already deployed at scale: requests first utilize 1.1.1.1 for DNS, a token proxy based on Privacy Pass for client authentication, and Geo-egress to choose an accurate egress IP address without exposing users’ precise location.
How it works
Let’s dive into the details of these components. For the purposes of this blog, we’ll call the devices people are using to browse the Internet (your phone, tablet or computer) clients, and the websites they’re trying to visit origin sites.
The Privacy Proxy Platform includes three main parts:
Token Proxy: this is the service that checks if you’re an Edge Secure Network user with a legitimate Microsoft account.
Privacy API: based on the above, Cloudflare’s Privacy API issues authentication tokens that clients use for authenticating to the proxy itself.
Privacy Proxy: this is the HTTP CONNECT-based proxy service running on Cloudflare’s network. This service checks that the client presents a valid authentication token, and if so, proxies the encrypted HTTP request to the origin site. It is also responsible for selecting a valid egress IP address to be used.
When Edge Secure Network protections are on – say, when a user connects to an open Wi-Fi network at a coffee shop – our proxy will automatically prompt that client for a token to authenticate. If the client has a token, it will present one. If it doesn’t, it will utilize the token proxy to mint a new pool using the help of an attester and issuer: the attester checks the validity of the client and Microsoft account, and the issuer issues tokens for that client in return. This dance is based on the Privacy Pass protocol. Importantly, it allows Cloudflare to validate that clients are who they say they are without collecting or storing personal information from Microsoft users.
Once the client has presented the proxy server with a valid token, the Privacy Proxy then chooses a valid egress IP address based on a hash of the client’s geolocation. It then uses the DNS record (provided by Cloudflare’s DNS resolver, 1.1.1.1) to open up an encrypted session to the origin website. From there, it’s pretty straightforward: if the user continues to browse on that site, further requests will be sent through that connection, if they stop or close the browser, that connection will close as well.
Because Cloudflare proxies millions of requests per second, many of the operational aspects of the proxy are managed by Oxy, our proxying framework that handles everything from telemetry, graceful restarts, to stream multiplexing and IP fallbacks, and authentication hooks.
Low last-mile latency and geolocation parity thanks to Cloudflare’s Network
Cloudflare’s privacy proxy implementation maximizes user experience without sacrificing privacy. When Edge Secure Network is enabled, users will have search and browsing results relevant to where they’re geographically located. At Cloudflare, we call this the pizza test: people should be able to use any of our privacy proxy products and still be able to get results for “pizza places near me”. We accomplish this by always egressing through a Cloudflare data center that has an IP address that corresponds to the user’s location – we’ve written more about how we did this for 1.1.1.1+WARP.
Unlike your typical VPN operator that has dozens – sometimes hundreds – of servers, Cloudflare has a much larger footprint: data centers in over 300 cities. Because our network is an anycast “every service, everywhere” approach, each of our data centers can accept traffic from an Edge Secure network client. This means that Edge users will automatically detect and connect with a Cloudflare data center geographically very close to them, minimizing last-mile latency. Finally, because Cloudflare also operates a CDN, websites that are already on Cloudflare will be given a “hot-path,” and will load faster.
We at Cloudflare are always striving to bring more privacy options to the open Internet, and we are excited to provide more private and secure browsing to Edge users. To learn more, head to Microsoft’s Edge Secure Network page or Microsoft’s support page. If you’re a partner interested in using a privacy-preserving proxy like this one, fill out this form.
Onstage at TechCrunch Disrupt 2023, Meredith Whittaker, the president of the Signal Foundation, which maintains the nonprofit Signal messaging app, reaffirmed that Signal would leave the U.K. if the country’s recently passed Online Safety Bill forced Signal to build “backdoors” into its end-to-end encryption.
“We would leave the U.K. or any jurisdiction if it came down to the choice between backdooring our encryption and betraying the people who count on us for privacy, or leaving,” Whittaker said. “And that’s never not true.”
Jake Appelbaum’s PhD thesis contains several newrevelations from the classified NSA documents provided to journalists by Edward Snowden. Nothing major, but a few more tidbits.
Kind of amazing that that all happened ten years ago. At this point, those documents are more historical than anything else.
And it’s unclear who has those archives anymore. According to Appelbaum, The Intercept destroyed their copy.
I recently published an essay about my experiences ten years ago.
A new Mozilla Foundation report concludes that cars, all of them, have terrible data privacy.
All 25 car brands we researched earned our *Privacy Not Included warning label—making cars the official worst category of products for privacy that we have ever reviewed.
There’s a lot of details in the report. They’re all bad.
A used government surveillance van is for sale in Chicago:
So how was this van turned into a mobile spying center? Well, let’s start with how it has more LCD monitors than a Counterstrike LAN party. They can be used to monitor any of six different video inputs including a videoscope camera. A videoscope and a borescope are very similar as they’re both cameras on the ends of optical fibers, so the same tech you’d use to inspect cylinder walls is also useful for surveillance. Kind of cool, right? Multiple Sony DVD-based video recorders store footage captured by cameras, audio recorders by high-end equipment brand Marantz capture sounds, and time and date generators sync gathered media up for accurate analysis. Circling back around to audio, this van features seven different audio inputs including a body wire channel.
Only $26,795, but you can probably negotiate them down.
License plate scanners aren’t new. Neither is using them for bulk surveillance. What’s new is that AI is being used on the data, identifying “suspicious” vehicle behavior:
Typically, Automatic License Plate Recognition (ALPR) technology is used to search for plates linked to specific crimes. But in this case it was used to examine the driving patterns of anyone passing one of Westchester County’s 480 cameras over a two-year period. Zayas’ lawyer Ben Gold contested the AI-gathered evidence against his client, decrying it as “dragnet surveillance.”
And he had the data to back it up. A FOIA he filed with the Westchester police revealed that the ALPR system was scanning over 16 million license plates a week, across 480 ALPR cameras. Of those systems, 434 were stationary, attached to poles and signs, while the remaining 46 were mobile, attached to police vehicles. The AI was not just looking at license plates either. It had also been taking notes on vehicles’ make, model and color—useful when a plate number for a suspect vehicle isn’t visible or is unknown.
Zoom updated its Terms of Service in March, spelling out that the company reserves the right to train AI on user data with no mention of a way to opt out. On Monday, the company said in a blog post that there’s no need to worry about that. Zoom execs swear the company won’t actually train its AI on your video calls without permission, even though the Terms of Service still say it can.
Of course, these are Terms of Service. They can change at any time. Zoom can renege on its promise at any time. There are no rules, only the whims of the company as it tries to maximize its profits.
It’s a stupid way to run a technological revolution. We should not have to rely on the benevolence of for-profit corporations to protect our rights. It’s not their job, and it shouldn’t be.
The collective thoughts of the interwebz
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.