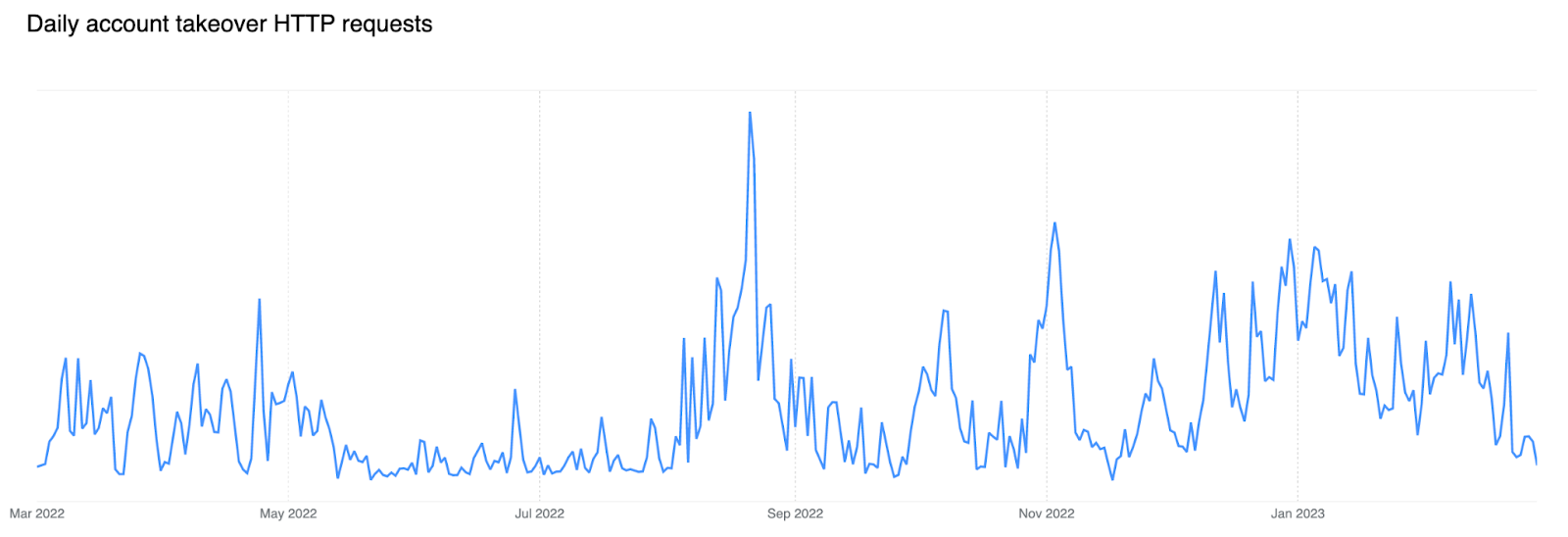
Post Syndicated from Phillip Jones original https://blog.cloudflare.com/developer-week-2024-wrap-up

Developer Week 2024 has officially come to a close. Each day last week, we shipped new products and functionality geared towards giving developers the components they need to build full-stack applications on Cloudflare.
Even though Developer Week is now over, we are continuing to innovate with the over two million developers who build on our platform. Building a platform is only as exciting as seeing what developers build on it. Before we dive into a recap of the announcements, to send off the week, we wanted to share how a couple of companies are using Cloudflare to power their applications:
We have been using Workers for image delivery using R2 and have been able to maintain stable operations for a year after implementation. The speed of deployment and the flexibility of detailed configurations have greatly reduced the time and effort required for traditional server management. In particular, we have seen a noticeable cost savings and are deeply appreciative of the support we have received from Cloudflare Workers.
– FAN Communications
Milkshake helps creators, influencers, and business owners create engaging web pages directly from their phone, to simply and creatively promote their projects and passions. Cloudflare has helped us migrate data quickly and affordably with R2. We use Workers as a routing layer between our users’ websites and their images and assets, and to build a personalized analytics offering affordably. Cloudflare’s innovations have consistently allowed us to run infrastructure at a fraction of the cost of other developer platforms and we have been eagerly awaiting updates to D1 and Queues to sustainably scale Milkshake as the product continues to grow.
– Milkshake
In case you missed anything, here’s a quick recap of the announcements and in-depth technical explorations that went out last week:
Summary of announcements
Monday
| Announcement | Summary |
|---|---|
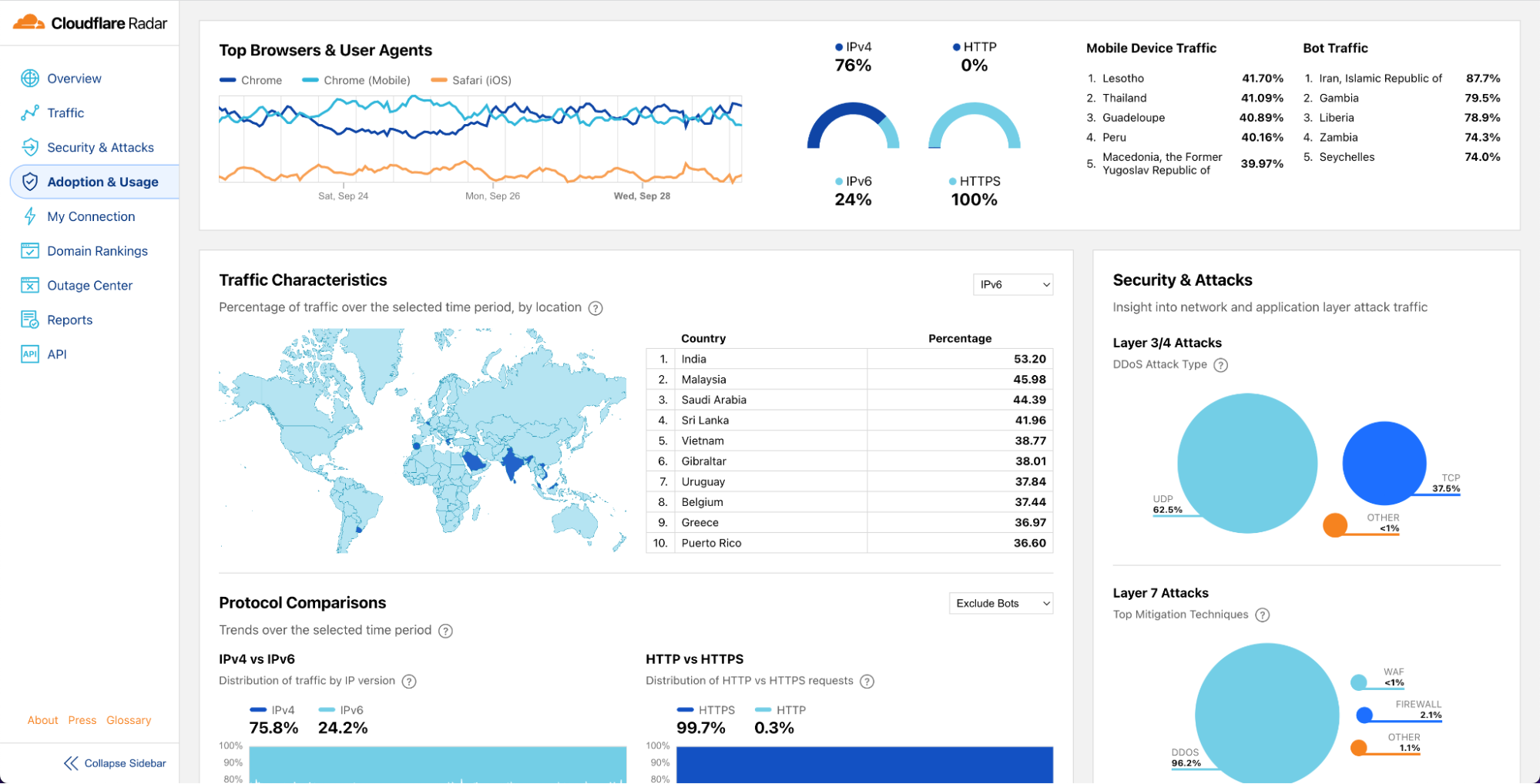
| Making state easy with D1 GA, Hyperdrive, Queues and Workers Analytics Engine updates | A core part of any full-stack application is storing and persisting data! We kicked off the week with announcements that help developers build stateful applications on top of Cloudflare, including making D1, Cloudflare’s SQL database and Hyperdrive, our database accelerating service, generally available. |
| Building D1: a Global Database | D1, Cloudflare’s SQL database, is now generally available. With new support for 10GB databases, data export, and enhanced query debugging, we empower developers to build production-ready applications with D1 to meet all their relational SQL needs. To support Workers in global applications, we’re sharing a sneak peek of our design and API for D1 global read replication to demonstrate how developers scale their workloads with D1. |
| Why Workers environment variables contain live objects | Bindings don’t just reduce boilerplate. They are a core design feature of the Workers platform which simultaneously improve developer experience and application security in several ways. Usually these two goals are in opposition to each other, but bindings elegantly solve for both at the same time. |
Tuesday
| Announcement | Summary |
|---|---|
| Leveling up Workers AI: General Availability and more new capabilities | We made a series of AI-related announcements, including Workers AI, Cloudflare’s inference platform becoming GA, support for fine-tuned models with LoRAs, one-click deploys from HuggingFace, Python support for Cloudflare Workers, and more. |
| Running fine-tuned models on Workers AI with LoRAs | Workers AI now supports fine-tuned models using LoRAs. But what is a LoRA and how does it work? In this post, we dive into fine-tuning, LoRAs and even some math to share the details of how it all works under the hood. |
| Bringing Python to Workers using Pyodide and WebAssembly | We introduced Python support for Cloudflare Workers, now in open beta. We’ve revamped our systems to support Python, from the Workers runtime itself to the way Workers are deployed to Cloudflare’s network. Learn about a Python Worker’s lifecycle, Pyodide, dynamic linking, and memory snapshots in this post. |
Wednesday
| Announcement | Summary |
|---|---|
| R2 adds event notifications, support for migrations from Google Cloud Storage, and an infrequent access storage tier | We announced three new features for Cloudflare R2: event notifications, support for migrations from Google Cloud Storage, and an infrequent access storage tier. |
| Data Anywhere with Pipelines, Event Notifications, and Workflows | We’re making it easier to build scalable, reliable, data-driven applications on top of our global network, and so we announced a new Event Notifications framework; our take on durable execution, Workflows; and an upcoming streaming ingestion service, Pipelines. |
| Improving Cloudflare Workers and D1 developer experience with Prisma ORM | Together, Cloudflare and Prisma make it easier than ever to deploy globally available apps with a focus on developer experience. To further that goal, Prisma ORM now natively supports Cloudflare Workers and D1 in Preview. With version 5.12.0 of Prisma ORM you can now interact with your data stored in D1 from your Cloudflare Workers with the convenience of the Prisma Client API. Learn more and try it out now. |
| How Picsart leverages Cloudflare’s Developer Platform to build globally performant services | Picsart, one of the world’s largest digital creation platforms, encountered performance challenges in catering to its global audience. Adopting Cloudflare’s global-by-default Developer Platform emerged as the optimal solution, empowering Picsart to enhance performance and scalability substantially. |
Thursday
| Announcement | Summary |
|---|---|
| Announcing Pages support for monorepos, wrangler.toml, database integrations and more! | We launched four improvements to Pages that bring functionality previously restricted to Workers, with the goal of unifying the development experience between the two. Support for monorepos, wrangler.toml, new additions to Next.js support and database integrations! |
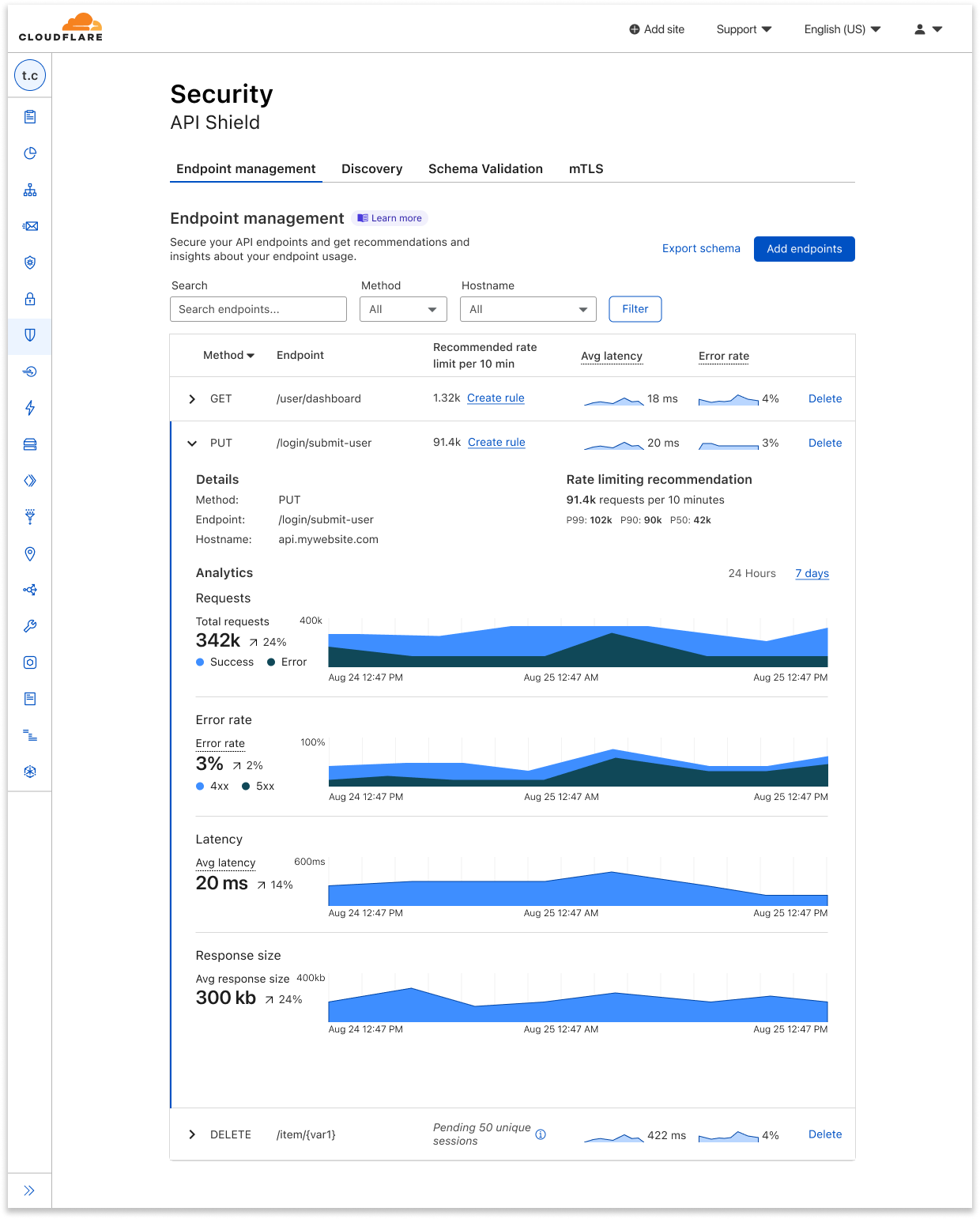
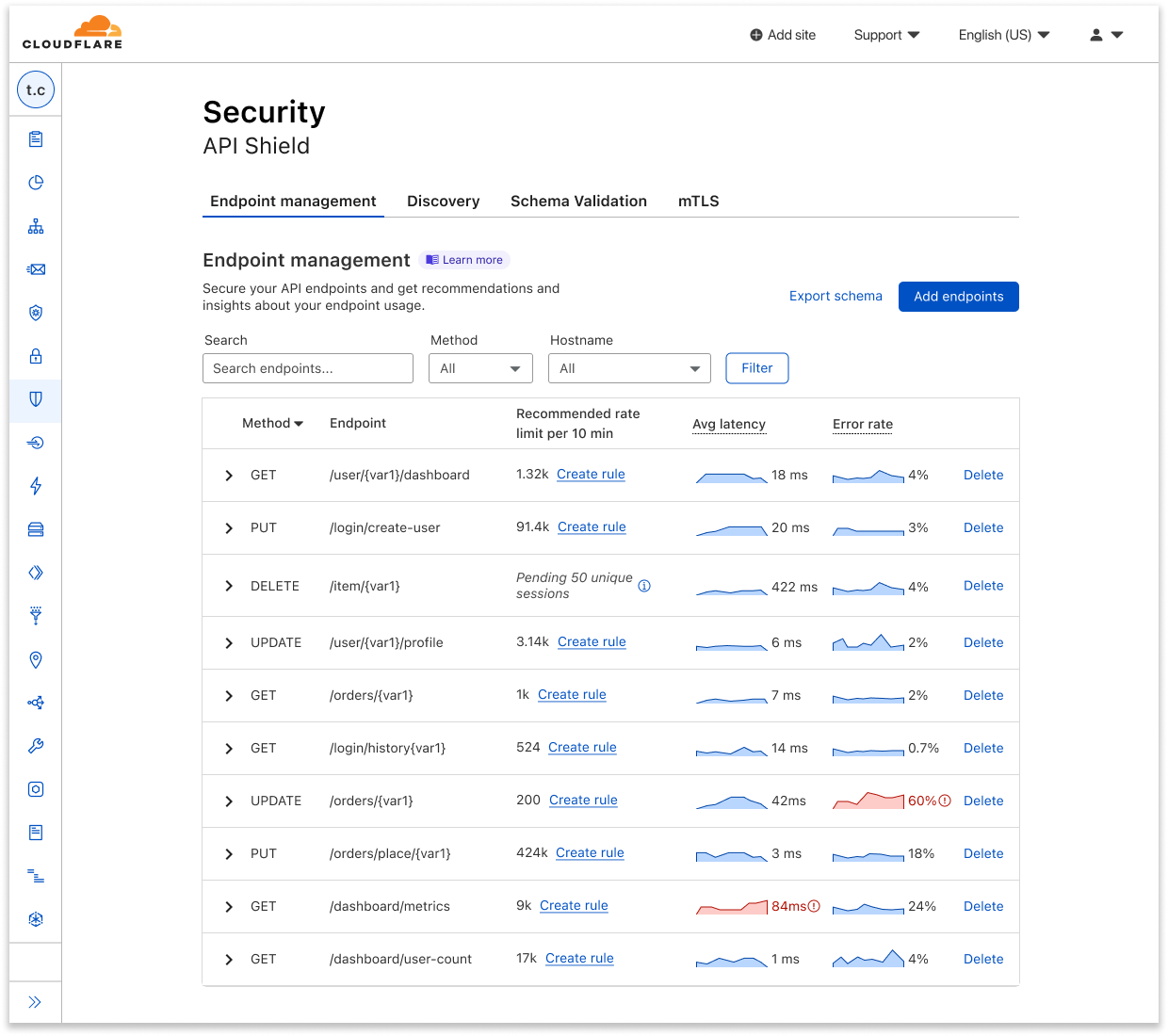
| New tools for production safety — Gradual Deployments, Stack Traces, Rate Limiting, and API SDKs | Production readiness isn’t just about scale and reliability of the services you build with. We announced five updates that put more power in your hands – Gradual Deployments, Source mapped stack traces in Tail Workers, a new Rate Limiting API, brand-new API SDKs, and updates to Durable Objects – each built with mission-critical production services in mind. |
| What’s new with Cloudflare Media: updates for Calls, Stream, and Images | With Cloudflare Calls in open beta, you can build real-time, serverless video and audio applications. Cloudflare Stream lets your viewers instantly clip from ongoing streams. Finally, Cloudflare Images now supports automatic face cropping and has an upload widget that lets you easily integrate into your application. |
| Cloudflare Calls: millions of cascading trees all the way down | Cloudflare Calls is a serverless SFU and TURN service running at Cloudflare’s edge. It’s now in open beta and costs $0.05/ real-time GB. It’s 100% anycast WebRTC. |
Friday
| Announcement | Summary |
|---|---|
| Browser Rendering API GA, rolling out Cloudflare Snippets, SWR, and bringing Workers for Platforms to all users | Browser Rendering API is now available to all paid Workers customers with improved session management. |
| Cloudflare acquires Baselime to expand serverless application observability capabilities | We announced that Cloudflare has acquired Baselime, a serverless observability company. |
| Cloudflare acquires PartyKit to allow developers to build real-time multi-user applications | We announced that PartyKit, a trailblazer in enabling developers to craft ambitious real-time, collaborative, multiplayer applications, is now a part of Cloudflare. This acquisition marks a significant milestone in our journey to redefine the boundaries of serverless computing, making it more dynamic, interactive, and, importantly, stateful. |
| Blazing fast development with full-stack frameworks and Cloudflare | Full-stack web development with Cloudflare is now faster and easier! You can now use your framework’s development server while accessing D1 databases, R2 object stores, AI models, and more. Iterate locally in milliseconds to build sophisticated web apps that run on Cloudflare. Let’s dev together! |
| We’ve added JavaScript-native RPC to Cloudflare Workers | Cloudflare Workers now features a built-in RPC (Remote Procedure Call) system for use in Worker-to-Worker and Worker-to-Durable Object communication, with absolutely minimal boilerplate. We’ve designed an RPC system so expressive that calling a remote service can feel like using a library. |
| Community Update: empowering startups building on Cloudflare and creating an inclusive community | We closed out Developer Week by sharing updates on our Workers Launchpad program, our latest Developer Challenge, and the work we’re doing to ensure our community spaces – like our Discord and Community forums – are safe and inclusive for all developers. |
Continue the conversation
Thank you for being a part of Developer Week! Want to continue the conversation and share what you’re building? Join us on Discord. To get started building on Workers, check out our developer documentation.